 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA System-Level View on Out-of-Distribution Data in Robotics
Dec 28, 2022When testing conditions differ from those represented in training data, so-called out-of-distribution (OOD) inputs can mar the reliability of black-box learned components in the modern robot autonomy stack. Therefore, coping with OOD data is an important challenge on the path towards trustworthy learning-enabled open-world autonomy. In this paper, we aim to demystify the topic of OOD data and its associated challenges in the context of data-driven robotic systems, drawing connections to emerging paradigms in the ML community that study the effect of OOD data on learned models in isolation. We argue that as roboticists, we should reason about the overall system-level competence of a robot as it performs tasks in OOD conditions. We highlight key research questions around this system-level view of OOD problems to guide future research toward safe and reliable learning-enabled autonomy.
Hybrid Multi-agent Deep Reinforcement Learning for Autonomous Mobility on Demand Systems
Dec 14, 2022We consider the sequential decision-making problem of making proactive request assignment and rejection decisions for a profit-maximizing operator of an autonomous mobility on demand system. We formalize this problem as a Markov decision process and propose a novel combination of multi-agent Soft Actor-Critic and weighted bipartite matching to obtain an anticipative control policy. Thereby, we factorize the operator's otherwise intractable action space, but still obtain a globally coordinated decision. Experiments based on real-world taxi data show that our method outperforms state of the art benchmarks with respect to performance, stability, and computational tractability.
DiffStack: A Differentiable and Modular Control Stack for Autonomous Vehicles
Dec 13, 2022



Autonomous vehicle (AV) stacks are typically built in a modular fashion, with explicit components performing detection, tracking, prediction, planning, control, etc. While modularity improves reusability, interpretability, and generalizability, it also suffers from compounding errors, information bottlenecks, and integration challenges. To overcome these challenges, a prominent approach is to convert the AV stack into an end-to-end neural network and train it with data. While such approaches have achieved impressive results, they typically lack interpretability and reusability, and they eschew principled analytical components, such as planning and control, in favor of deep neural networks. To enable the joint optimization of AV stacks while retaining modularity, we present DiffStack, a differentiable and modular stack for prediction, planning, and control. Crucially, our model-based planning and control algorithms leverage recent advancements in differentiable optimization to produce gradients, enabling optimization of upstream components, such as prediction, via backpropagation through planning and control. Our results on the nuScenes dataset indicate that end-to-end training with DiffStack yields substantial improvements in open-loop and closed-loop planning metrics by, e.g., learning to make fewer prediction errors that would affect planning. Beyond these immediate benefits, DiffStack opens up new opportunities for fully data-driven yet modular and interpretable AV architectures. Project website: https://sites.google.com/view/diffstack
Receding Horizon Planning with Rule Hierarchies for Autonomous Vehicles
Dec 06, 2022



Autonomous vehicles must often contend with conflicting planning requirements, e.g., safety and comfort could be at odds with each other if avoiding a collision calls for slamming the brakes. To resolve such conflicts, assigning importance ranking to rules (i.e., imposing a rule hierarchy) has been proposed, which, in turn, induces rankings on trajectories based on the importance of the rules they satisfy. On one hand, imposing rule hierarchies can enhance interpretability, but introduce combinatorial complexity to planning; while on the other hand, differentiable reward structures can be leveraged by modern gradient-based optimization tools, but are less interpretable and unintuitive to tune. In this paper, we present an approach to equivalently express rule hierarchies as differentiable reward structures amenable to modern gradient-based optimizers, thereby, achieving the best of both worlds. We achieve this by formulating rank-preserving reward functions that are monotonic in the rank of the trajectories induced by the rule hierarchy; i.e., higher ranked trajectories receive higher reward. Equipped with a rule hierarchy and its corresponding rank-preserving reward function, we develop a two-stage planner that can efficiently resolve conflicting planning requirements. We demonstrate that our approach can generate motion plans in ~7-10 Hz for various challenging road navigation and intersection negotiation scenarios.
Adaptive Robust Model Predictive Control via Uncertainty Cancellation
Dec 02, 2022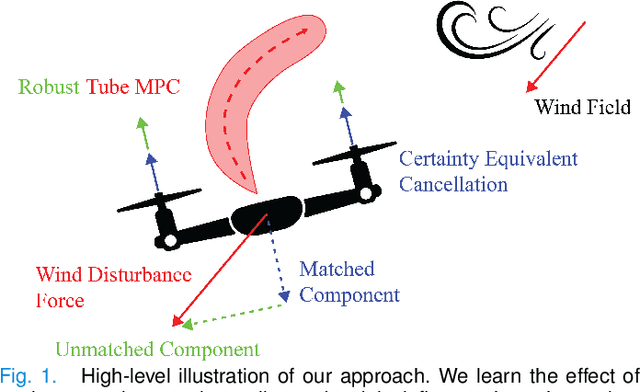
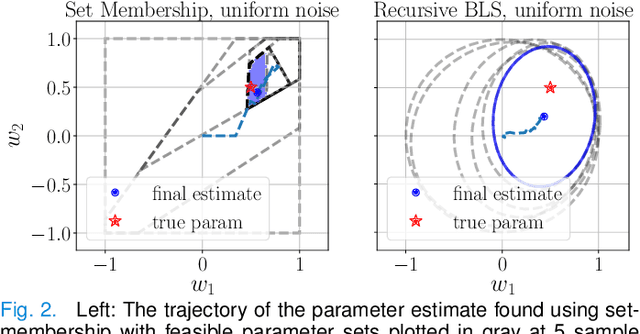
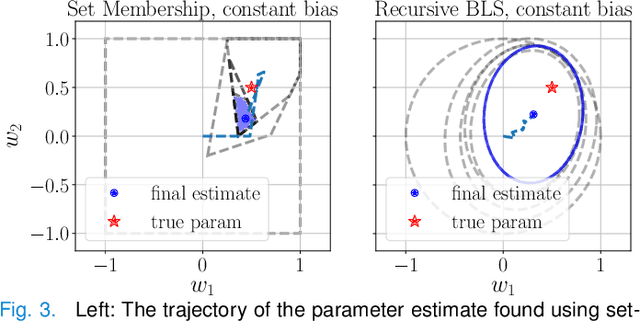
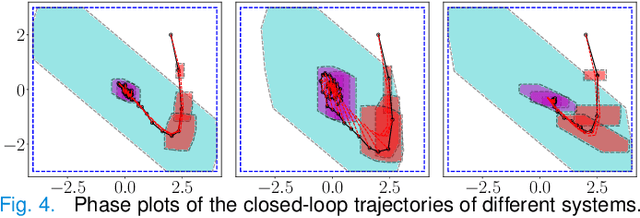
We propose a learning-based robust predictive control algorithm that compensates for significant uncertainty in the dynamics for a class of discrete-time systems that are nominally linear with an additive nonlinear component. Such systems commonly model the nonlinear effects of an unknown environment on a nominal system. We optimize over a class of nonlinear feedback policies inspired by certainty equivalent "estimate-and-cancel" control laws pioneered in classical adaptive control to achieve significant performance improvements in the presence of uncertainties of large magnitude, a setting in which existing learning-based predictive control algorithms often struggle to guarantee safety. In contrast to previous work in robust adaptive MPC, our approach allows us to take advantage of structure (i.e., the numerical predictions) in the a priori unknown dynamics learned online through function approximation. Our approach also extends typical nonlinear adaptive control methods to systems with state and input constraints even when we cannot directly cancel the additive uncertain function from the dynamics. We apply contemporary statistical estimation techniques to certify the system's safety through persistent constraint satisfaction with high probability. Moreover, we propose using Bayesian meta-learning algorithms that learn calibrated model priors to help satisfy the assumptions of the control design in challenging settings. Finally, we show in simulation that our method can accommodate more significant unknown dynamics terms than existing methods and that the use of Bayesian meta-learning allows us to adapt to the test environments more rapidly.
Online Distribution Shift Detection via Recency Prediction
Nov 17, 2022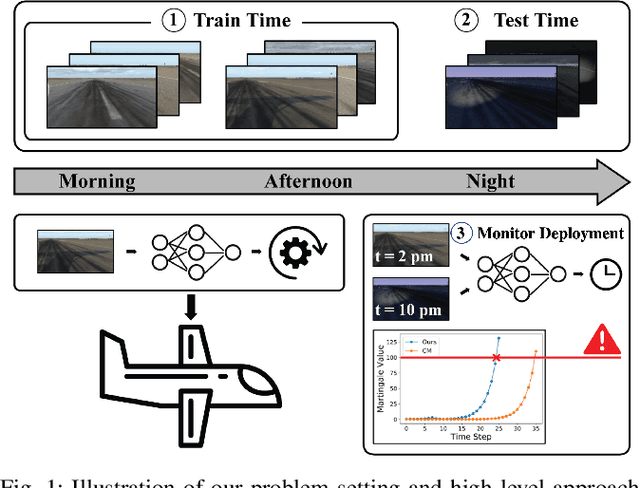

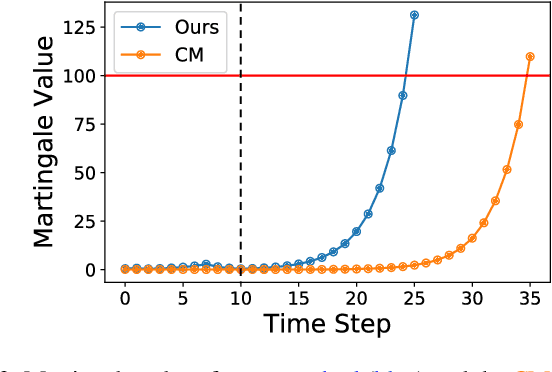

When deploying modern machine learning-enabled robotic systems in high-stakes applications, detecting distribution shift is critical. However, most existing methods for detecting distribution shift are not well-suited to robotics settings, where data often arrives in a streaming fashion and may be very high-dimensional. In this work, we present an online method for detecting distribution shift with guarantees on the false positive rate - i.e., when there is no distribution shift, our system is very unlikely (with probability $< \epsilon$) to falsely issue an alert; any alerts that are issued should therefore be heeded. Our method is specifically designed for efficient detection even with high dimensional data, and it empirically achieves up to 11x faster detection on realistic robotics settings compared to prior work while maintaining a low false negative rate in practice (whenever there is a distribution shift in our experiments, our method indeed emits an alert).
Foundation Models for Semantic Novelty in Reinforcement Learning
Nov 09, 2022



Effectively exploring the environment is a key challenge in reinforcement learning (RL). We address this challenge by defining a novel intrinsic reward based on a foundation model, such as contrastive language image pretraining (CLIP), which can encode a wealth of domain-independent semantic visual-language knowledge about the world. Specifically, our intrinsic reward is defined based on pre-trained CLIP embeddings without any fine-tuning or learning on the target RL task. We demonstrate that CLIP-based intrinsic rewards can drive exploration towards semantically meaningful states and outperform state-of-the-art methods in challenging sparse-reward procedurally-generated environments.
Guided Conditional Diffusion for Controllable Traffic Simulation
Oct 31, 2022Controllable and realistic traffic simulation is critical for developing and verifying autonomous vehicles. Typical heuristic-based traffic models offer flexible control to make vehicles follow specific trajectories and traffic rules. On the other hand, data-driven approaches generate realistic and human-like behaviors, improving transfer from simulated to real-world traffic. However, to the best of our knowledge, no traffic model offers both controllability and realism. In this work, we develop a conditional diffusion model for controllable traffic generation (CTG) that allows users to control desired properties of trajectories at test time (e.g., reach a goal or follow a speed limit) while maintaining realism and physical feasibility through enforced dynamics. The key technical idea is to leverage recent advances from diffusion modeling and differentiable logic to guide generated trajectories to meet rules defined using signal temporal logic (STL). We further extend guidance to multi-agent settings and enable interaction-based rules like collision avoidance. CTG is extensively evaluated on the nuScenes dataset for diverse and composite rules, demonstrating improvement over strong baselines in terms of the controllability-realism tradeoff.
Planning with Occluded Traffic Agents using Bi-Level Variational Occlusion Models
Oct 26, 2022Reasoning with occluded traffic agents is a significant open challenge for planning for autonomous vehicles. Recent deep learning models have shown impressive results for predicting occluded agents based on the behaviour of nearby visible agents; however, as we show in experiments, these models are difficult to integrate into downstream planning. To this end, we propose Bi-level Variational Occlusion Models (BiVO), a two-step generative model that first predicts likely locations of occluded agents, and then generates likely trajectories for the occluded agents. In contrast to existing methods, BiVO outputs a trajectory distribution which can then be sampled from and integrated into standard downstream planning. We evaluate the method in closed-loop replay simulation using the real-world nuScenes dataset. Our results suggest that BiVO can successfully learn to predict occluded agent trajectories, and these predictions lead to better subsequent motion plans in critical scenarios.
Robust and Controllable Object-Centric Learning through Energy-based Models
Oct 11, 2022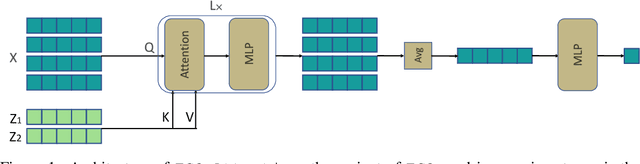
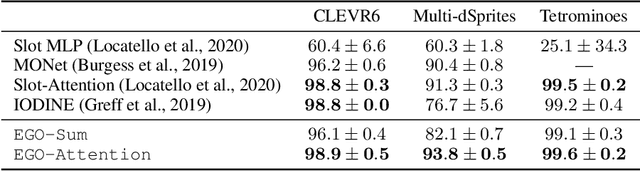
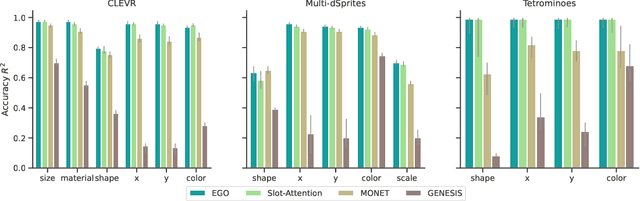
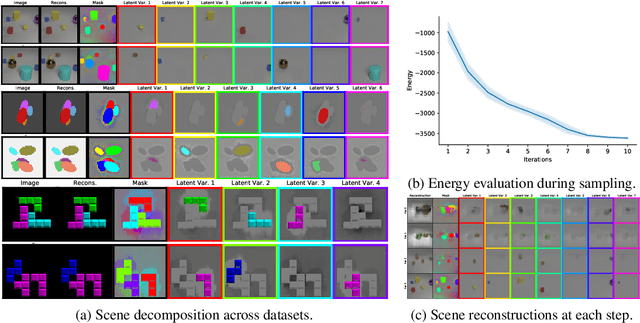
Humans are remarkably good at understanding and reasoning about complex visual scenes. The capability to decompose low-level observations into discrete objects allows us to build a grounded abstract representation and identify the compositional structure of the world. Accordingly, it is a crucial step for machine learning models to be capable of inferring objects and their properties from visual scenes without explicit supervision. However, existing works on object-centric representation learning either rely on tailor-made neural network modules or strong probabilistic assumptions in the underlying generative and inference processes. In this work, we present \ours, a conceptually simple and general approach to learning object-centric representations through an energy-based model. By forming a permutation-invariant energy function using vanilla attention blocks readily available in Transformers, we can infer object-centric latent variables via gradient-based MCMC methods where permutation equivariance is automatically guaranteed. We show that \ours can be easily integrated into existing architectures and can effectively extract high-quality object-centric representations, leading to better segmentation accuracy and competitive downstream task performance. Further, empirical evaluations show that \ours's learned representations are robust against distribution shift. Finally, we demonstrate the effectiveness of \ours in systematic compositional generalization, by re-composing learned energy functions for novel scene generation and manipulation.