 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond World Models: Rethinking Understanding in AI Models
Nov 15, 2025World models have garnered substantial interest in the AI community. These are internal representations that simulate aspects of the external world, track entities and states, capture causal relationships, and enable prediction of consequences. This contrasts with representations based solely on statistical correlations. A key motivation behind this research direction is that humans possess such mental world models, and finding evidence of similar representations in AI models might indicate that these models "understand" the world in a human-like way. In this paper, we use case studies from the philosophy of science literature to critically examine whether the world model framework adequately characterizes human-level understanding. We focus on specific philosophical analyses where the distinction between world model capabilities and human understanding is most pronounced. While these represent particular views of understanding rather than universal definitions, they help us explore the limits of world models.
Adapting a World Model for Trajectory Following in a 3D Game
Apr 16, 2025



Imitation learning is a powerful tool for training agents by leveraging expert knowledge, and being able to replicate a given trajectory is an integral part of it. In complex environments, like modern 3D video games, distribution shift and stochasticity necessitate robust approaches beyond simple action replay. In this study, we apply Inverse Dynamics Models (IDM) with different encoders and policy heads to trajectory following in a modern 3D video game -- Bleeding Edge. Additionally, we investigate several future alignment strategies that address the distribution shift caused by the aleatoric uncertainty and imperfections of the agent. We measure both the trajectory deviation distance and the first significant deviation point between the reference and the agent's trajectory and show that the optimal configuration depends on the chosen setting. Our results show that in a diverse data setting, a GPT-style policy head with an encoder trained from scratch performs the best, DINOv2 encoder with the GPT-style policy head gives the best results in the low data regime, and both GPT-style and MLP-style policy heads had comparable results when pre-trained on a diverse setting and fine-tuned for a specific behaviour setting.
All That Glitters is Not Novel: Plagiarism in AI Generated Research
Feb 23, 2025



Automating scientific research is considered the final frontier of science. Recently, several papers claim autonomous research agents can generate novel research ideas. Amidst the prevailing optimism, we document a critical concern: a considerable fraction of such research documents are smartly plagiarized. Unlike past efforts where experts evaluate the novelty and feasibility of research ideas, we request $13$ experts to operate under a different situational logic: to identify similarities between LLM-generated research documents and existing work. Concerningly, the experts identify $24\%$ of the $50$ evaluated research documents to be either paraphrased (with one-to-one methodological mapping), or significantly borrowed from existing work. These reported instances are cross-verified by authors of the source papers. Problematically, these LLM-generated research documents do not acknowledge original sources, and bypass inbuilt plagiarism detectors. Lastly, through controlled experiments we show that automated plagiarism detectors are inadequate at catching deliberately plagiarized ideas from an LLM. We recommend a careful assessment of LLM-generated research, and discuss the implications of our findings on research and academic publishing.
The Essential Role of Causality in Foundation World Models for Embodied AI
Feb 06, 2024

Recent advances in foundation models, especially in large multi-modal models and conversational agents, have ignited interest in the potential of generally capable embodied agents. Such agents would require the ability to perform new tasks in many different real-world environments. However, current foundation models fail to accurately model physical interactions with the real world thus not sufficient for Embodied AI. The study of causality lends itself to the construction of veridical world models, which are crucial for accurately predicting the outcomes of possible interactions. This paper focuses on the prospects of building foundation world models for the upcoming generation of embodied agents and presents a novel viewpoint on the significance of causality within these. We posit that integrating causal considerations is vital to facilitate meaningful physical interactions with the world. Finally, we demystify misconceptions about causality in this context and present our outlook for future research.
Hierarchical Imitation Learning for Stochastic Environments
Sep 25, 2023



Many applications of imitation learning require the agent to generate the full distribution of behaviour observed in the training data. For example, to evaluate the safety of autonomous vehicles in simulation, accurate and diverse behaviour models of other road users are paramount. Existing methods that improve this distributional realism typically rely on hierarchical policies. These condition the policy on types such as goals or personas that give rise to multi-modal behaviour. However, such methods are often inappropriate for stochastic environments where the agent must also react to external factors: because agent types are inferred from the observed future trajectory during training, these environments require that the contributions of internal and external factors to the agent behaviour are disentangled and only internal factors, i.e., those under the agent's control, are encoded in the type. Encoding future information about external factors leads to inappropriate agent reactions during testing, when the future is unknown and types must be drawn independently from the actual future. We formalize this challenge as distribution shift in the conditional distribution of agent types under environmental stochasticity. We propose Robust Type Conditioning (RTC), which eliminates this shift with adversarial training under randomly sampled types. Experiments on two domains, including the large-scale Waymo Open Motion Dataset, show improved distributional realism while maintaining or improving task performance compared to state-of-the-art baselines.
Improving Spoken Language Identification with Map-Mix
Feb 16, 2023The pre-trained multi-lingual XLSR model generalizes well for language identification after fine-tuning on unseen languages. However, the performance significantly degrades when the languages are not very distinct from each other, for example, in the case of dialects. Low resource dialect classification remains a challenging problem to solve. We present a new data augmentation method that leverages model training dynamics of individual data points to improve sampling for latent mixup. The method works well in low-resource settings where generalization is paramount. Our datamaps-based mixup technique, which we call Map-Mix improves weighted F1 scores by 2% compared to the random mixup baseline and results in a significantly well-calibrated model. The code for our method is open sourced on https://github.com/skit-ai/Map-Mix.
Foundation Models for Semantic Novelty in Reinforcement Learning
Nov 09, 2022



Effectively exploring the environment is a key challenge in reinforcement learning (RL). We address this challenge by defining a novel intrinsic reward based on a foundation model, such as contrastive language image pretraining (CLIP), which can encode a wealth of domain-independent semantic visual-language knowledge about the world. Specifically, our intrinsic reward is defined based on pre-trained CLIP embeddings without any fine-tuning or learning on the target RL task. We demonstrate that CLIP-based intrinsic rewards can drive exploration towards semantically meaningful states and outperform state-of-the-art methods in challenging sparse-reward procedurally-generated environments.
Estimation of speaker age and height from speech signal using bi-encoder transformer mixture model
Mar 22, 2022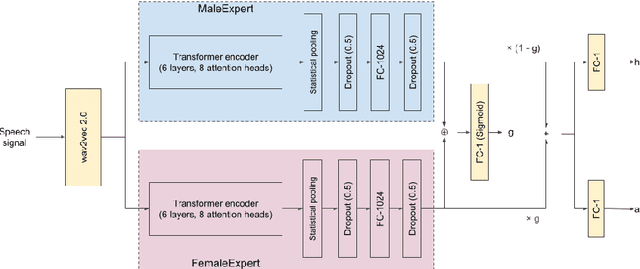
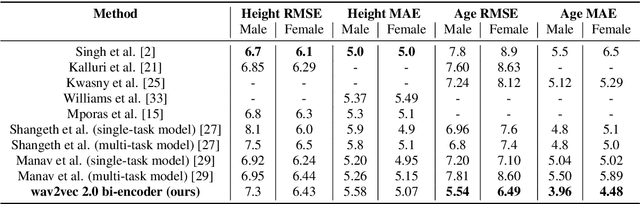


The estimation of speaker characteristics such as age and height is a challenging task, having numerous applications in voice forensic analysis. In this work, we propose a bi-encoder transformer mixture model for speaker age and height estimation. Considering the wide differences in male and female voice characteristics such as differences in formant and fundamental frequencies, we propose the use of two separate transformer encoders for the extraction of specific voice features in the male and female gender, using wav2vec 2.0 as a common-level feature extractor. This architecture reduces the interference effects during backpropagation and improves the generalizability of the model. We perform our experiments on the TIMIT dataset and significantly outperform the current state-of-the-art results on age estimation. Specifically, we achieve root mean squared error (RMSE) of 5.54 years and 6.49 years for male and female age estimation, respectively. Further experiment to evaluate the relative importance of different phonetic types for our task demonstrate that vowel sounds are the most distinguishing for age estimation.
Generalization in Cooperative Multi-Agent Systems
Jan 31, 2022


Collective intelligence is a fundamental trait shared by several species of living organisms. It has allowed them to thrive in the diverse environmental conditions that exist on our planet. From simple organisations in an ant colony to complex systems in human groups, collective intelligence is vital for solving complex survival tasks. As is commonly observed, such natural systems are flexible to changes in their structure. Specifically, they exhibit a high degree of generalization when the abilities or the total number of agents changes within a system. We term this phenomenon as Combinatorial Generalization (CG). CG is a highly desirable trait for autonomous systems as it can increase their utility and deployability across a wide range of applications. While recent works addressing specific aspects of CG have shown impressive results on complex domains, they provide no performance guarantees when generalizing towards novel situations. In this work, we shed light on the theoretical underpinnings of CG for cooperative multi-agent systems (MAS). Specifically, we study generalization bounds under a linear dependence of the underlying dynamics on the agent capabilities, which can be seen as a generalization of Successor Features to MAS. We then extend the results first for Lipschitz and then arbitrary dependence of rewards on team capabilities. Finally, empirical analysis on various domains using the framework of multi-agent reinforcement learning highlights important desiderata for multi-agent algorithms towards ensuring CG.
Semi-On-Policy Training for Sample Efficient Multi-Agent Policy Gradients
May 06, 2021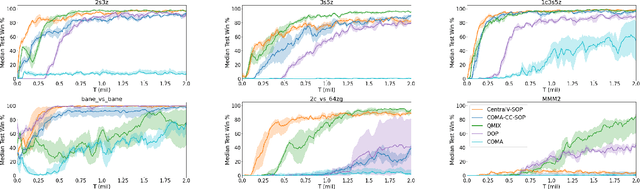
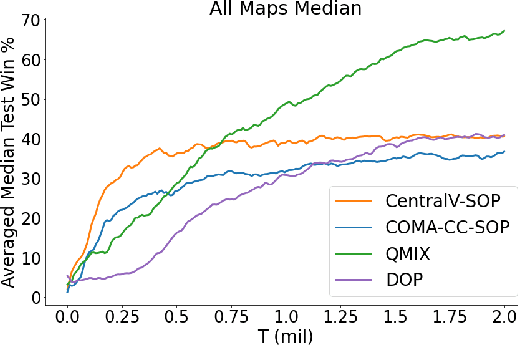
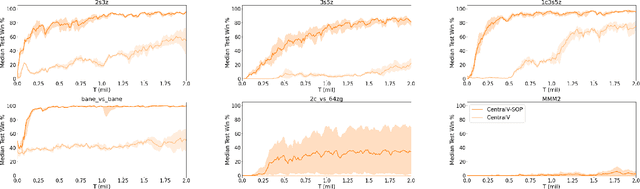
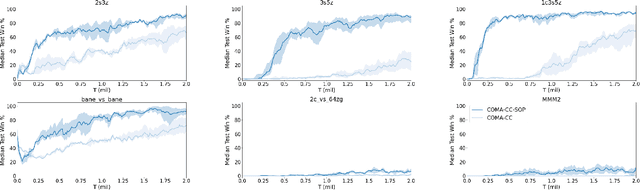
Policy gradient methods are an attractive approach to multi-agent reinforcement learning problems due to their convergence properties and robustness in partially observable scenarios. However, there is a significant performance gap between state-of-the-art policy gradient and value-based methods on the popular StarCraft Multi-Agent Challenge (SMAC) benchmark. In this paper, we introduce semi-on-policy (SOP) training as an effective and computationally efficient way to address the sample inefficiency of on-policy policy gradient methods. We enhance two state-of-the-art policy gradient algorithms with SOP training, demonstrating significant performance improvements. Furthermore, we show that our methods perform as well or better than state-of-the-art value-based methods on a variety of SMAC tasks.