 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitating Shortest Paths in Simulation Enables Effective Navigation and Manipulation in the Real World
Dec 05, 2023



Reinforcement learning (RL) with dense rewards and imitation learning (IL) with human-generated trajectories are the most widely used approaches for training modern embodied agents. RL requires extensive reward shaping and auxiliary losses and is often too slow and ineffective for long-horizon tasks. While IL with human supervision is effective, collecting human trajectories at scale is extremely expensive. In this work, we show that imitating shortest-path planners in simulation produces agents that, given a language instruction, can proficiently navigate, explore, and manipulate objects in both simulation and in the real world using only RGB sensors (no depth map or GPS coordinates). This surprising result is enabled by our end-to-end, transformer-based, SPOC architecture, powerful visual encoders paired with extensive image augmentation, and the dramatic scale and diversity of our training data: millions of frames of shortest-path-expert trajectories collected inside approximately 200,000 procedurally generated houses containing 40,000 unique 3D assets. Our models, data, training code, and newly proposed 10-task benchmarking suite CHORES will be open-sourced.
Universal Visual Decomposer: Long-Horizon Manipulation Made Easy
Oct 12, 2023



Real-world robotic tasks stretch over extended horizons and encompass multiple stages. Learning long-horizon manipulation tasks, however, is a long-standing challenge, and demands decomposing the overarching task into several manageable subtasks to facilitate policy learning and generalization to unseen tasks. Prior task decomposition methods require task-specific knowledge, are computationally intensive, and cannot readily be applied to new tasks. To address these shortcomings, we propose Universal Visual Decomposer (UVD), an off-the-shelf task decomposition method for visual long horizon manipulation using pre-trained visual representations designed for robotic control. At a high level, UVD discovers subgoals by detecting phase shifts in the embedding space of the pre-trained representation. Operating purely on visual demonstrations without auxiliary information, UVD can effectively extract visual subgoals embedded in the videos, while incurring zero additional training cost on top of standard visuomotor policy training. Goal-conditioned policies learned with UVD-discovered subgoals exhibit significantly improved compositional generalization at test time to unseen tasks. Furthermore, UVD-discovered subgoals can be used to construct goal-based reward shaping that jump-starts temporally extended exploration for reinforcement learning. We extensively evaluate UVD on both simulation and real-world tasks, and in all cases, UVD substantially outperforms baselines across imitation and reinforcement learning settings on in-domain and out-of-domain task sequences alike, validating the clear advantage of automated visual task decomposition within the simple, compact UVD framework.
Moving Forward by Moving Backward: Embedding Action Impact over Action Semantics
Apr 24, 2023



A common assumption when training embodied agents is that the impact of taking an action is stable; for instance, executing the "move ahead" action will always move the agent forward by a fixed distance, perhaps with some small amount of actuator-induced noise. This assumption is limiting; an agent may encounter settings that dramatically alter the impact of actions: a move ahead action on a wet floor may send the agent twice as far as it expects and using the same action with a broken wheel might transform the expected translation into a rotation. Instead of relying that the impact of an action stably reflects its pre-defined semantic meaning, we propose to model the impact of actions on-the-fly using latent embeddings. By combining these latent action embeddings with a novel, transformer-based, policy head, we design an Action Adaptive Policy (AAP). We evaluate our AAP on two challenging visual navigation tasks in the AI2-THOR and Habitat environments and show that our AAP is highly performant even when faced, at inference-time with missing actions and, previously unseen, perturbed action space. Moreover, we observe significant improvement in robustness against these actions when evaluating in real-world scenarios.
When Learning Is Out of Reach, Reset: Generalization in Autonomous Visuomotor Reinforcement Learning
Mar 30, 2023Episodic training, where an agent's environment is reset after every success or failure, is the de facto standard when training embodied reinforcement learning (RL) agents. The underlying assumption that the environment can be easily reset is limiting both practically, as resets generally require human effort in the real world and can be computationally expensive in simulation, and philosophically, as we'd expect intelligent agents to be able to continuously learn without intervention. Work in learning without any resets, i.e{.} Reset-Free RL (RF-RL), is promising but is plagued by the problem of irreversible transitions (e.g{.} an object breaking) which halt learning. Moreover, the limited state diversity and instrument setup encountered during RF-RL means that works studying RF-RL largely do not require their models to generalize to new environments. In this work, we instead look to minimize, rather than completely eliminate, resets while building visual agents that can meaningfully generalize. As studying generalization has previously not been a focus of benchmarks designed for RF-RL, we propose a new Stretch Pick-and-Place benchmark designed for evaluating generalizations across goals, cosmetic variations, and structural changes. Moreover, towards building performant reset-minimizing RL agents, we propose unsupervised metrics to detect irreversible transitions and a single-policy training mechanism to enable generalization. Our proposed approach significantly outperforms prior episodic, reset-free, and reset-minimizing approaches achieving higher success rates with fewer resets in Stretch-P\&P and another popular RF-RL benchmark. Finally, we find that our proposed approach can dramatically reduce the number of resets required for training other embodied tasks, in particular for RoboTHOR ObjectNav we obtain higher success rates than episodic approaches using 99.97\% fewer resets.
Objaverse: A Universe of Annotated 3D Objects
Dec 15, 2022Massive data corpora like WebText, Wikipedia, Conceptual Captions, WebImageText, and LAION have propelled recent dramatic progress in AI. Large neural models trained on such datasets produce impressive results and top many of today's benchmarks. A notable omission within this family of large-scale datasets is 3D data. Despite considerable interest and potential applications in 3D vision, datasets of high-fidelity 3D models continue to be mid-sized with limited diversity of object categories. Addressing this gap, we present Objaverse 1.0, a large dataset of objects with 800K+ (and growing) 3D models with descriptive captions, tags, and animations. Objaverse improves upon present day 3D repositories in terms of scale, number of categories, and in the visual diversity of instances within a category. We demonstrate the large potential of Objaverse via four diverse applications: training generative 3D models, improving tail category segmentation on the LVIS benchmark, training open-vocabulary object-navigation models for Embodied AI, and creating a new benchmark for robustness analysis of vision models. Objaverse can open new directions for research and enable new applications across the field of AI.
Phone2Proc: Bringing Robust Robots Into Our Chaotic World
Dec 08, 2022Training embodied agents in simulation has become mainstream for the embodied AI community. However, these agents often struggle when deployed in the physical world due to their inability to generalize to real-world environments. In this paper, we present Phone2Proc, a method that uses a 10-minute phone scan and conditional procedural generation to create a distribution of training scenes that are semantically similar to the target environment. The generated scenes are conditioned on the wall layout and arrangement of large objects from the scan, while also sampling lighting, clutter, surface textures, and instances of smaller objects with randomized placement and materials. Leveraging just a simple RGB camera, training with Phone2Proc shows massive improvements from 34.7% to 70.7% success rate in sim-to-real ObjectNav performance across a test suite of over 200 trials in diverse real-world environments, including homes, offices, and RoboTHOR. Furthermore, Phone2Proc's diverse distribution of generated scenes makes agents remarkably robust to changes in the real world, such as human movement, object rearrangement, lighting changes, or clutter.
A General Purpose Supervisory Signal for Embodied Agents
Dec 01, 2022



Training effective embodied AI agents often involves manual reward engineering, expert imitation, specialized components such as maps, or leveraging additional sensors for depth and localization. Another approach is to use neural architectures alongside self-supervised objectives which encourage better representation learning. In practice, there are few guarantees that these self-supervised objectives encode task-relevant information. We propose the Scene Graph Contrastive (SGC) loss, which uses scene graphs as general-purpose, training-only, supervisory signals. The SGC loss does away with explicit graph decoding and instead uses contrastive learning to align an agent's representation with a rich graphical encoding of its environment. The SGC loss is generally applicable, simple to implement, and encourages representations that encode objects' semantics, relationships, and history. Using the SGC loss, we attain significant gains on three embodied tasks: Object Navigation, Multi-Object Navigation, and Arm Point Navigation. Finally, we present studies and analyses which demonstrate the ability of our trained representation to encode semantic cues about the environment.
Ask4Help: Learning to Leverage an Expert for Embodied Tasks
Nov 18, 2022Embodied AI agents continue to become more capable every year with the advent of new models, environments, and benchmarks, but are still far away from being performant and reliable enough to be deployed in real, user-facing, applications. In this paper, we ask: can we bridge this gap by enabling agents to ask for assistance from an expert such as a human being? To this end, we propose the Ask4Help policy that augments agents with the ability to request, and then use expert assistance. Ask4Help policies can be efficiently trained without modifying the original agent's parameters and learn a desirable trade-off between task performance and the amount of requested help, thereby reducing the cost of querying the expert. We evaluate Ask4Help on two different tasks -- object goal navigation and room rearrangement and see substantial improvements in performance using minimal help. On object navigation, an agent that achieves a $52\%$ success rate is raised to $86\%$ with $13\%$ help and for rearrangement, the state-of-the-art model with a $7\%$ success rate is dramatically improved to $90.4\%$ using $39\%$ help. Human trials with Ask4Help demonstrate the efficacy of our approach in practical scenarios. We release the code for Ask4Help here: https://github.com/allenai/ask4help.
Retrospectives on the Embodied AI Workshop
Oct 17, 2022

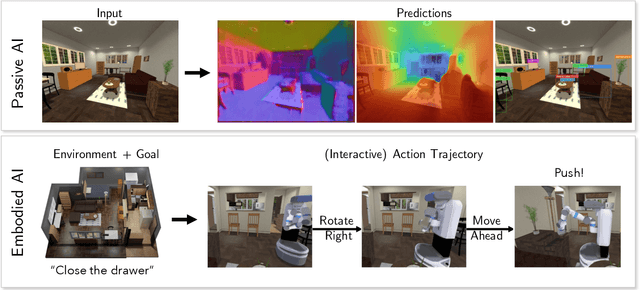
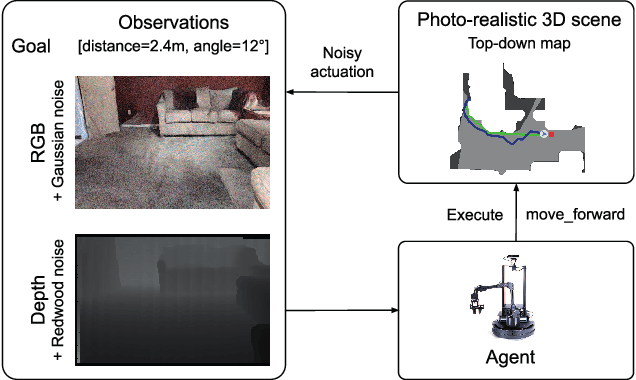
We present a retrospective on the state of Embodied AI research. Our analysis focuses on 13 challenges presented at the Embodied AI Workshop at CVPR. These challenges are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of state-of-the-art models. We highlight commonalities between top approaches to the challenges and identify potential future directions for Embodied AI research.
ProcTHOR: Large-Scale Embodied AI Using Procedural Generation
Jun 14, 2022

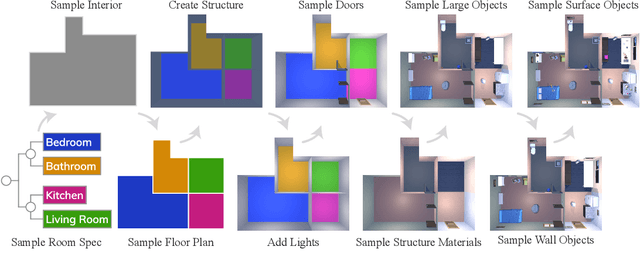
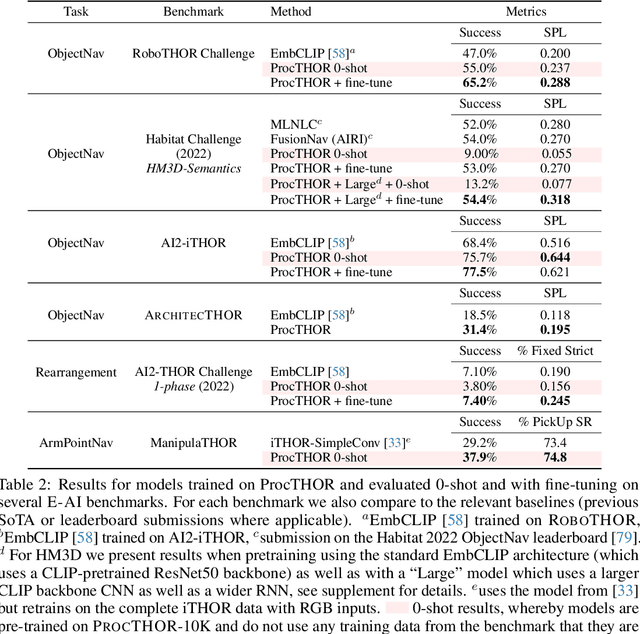
Massive datasets and high-capacity models have driven many recent advancements in computer vision and natural language understanding. This work presents a platform to enable similar success stories in Embodied AI. We propose ProcTHOR, a framework for procedural generation of Embodied AI environments. ProcTHOR enables us to sample arbitrarily large datasets of diverse, interactive, customizable, and performant virtual environments to train and evaluate embodied agents across navigation, interaction, and manipulation tasks. We demonstrate the power and potential of ProcTHOR via a sample of 10,000 generated houses and a simple neural model. Models trained using only RGB images on ProcTHOR, with no explicit mapping and no human task supervision produce state-of-the-art results across 6 embodied AI benchmarks for navigation, rearrangement, and arm manipulation, including the presently running Habitat 2022, AI2-THOR Rearrangement 2022, and RoboTHOR challenges. We also demonstrate strong 0-shot results on these benchmarks, via pre-training on ProcTHOR with no fine-tuning on the downstream benchmark, often beating previous state-of-the-art systems that access the downstream training data.