 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Semantic Segmentation Beyond 1K Classes on a Single GPU
Dec 14, 2020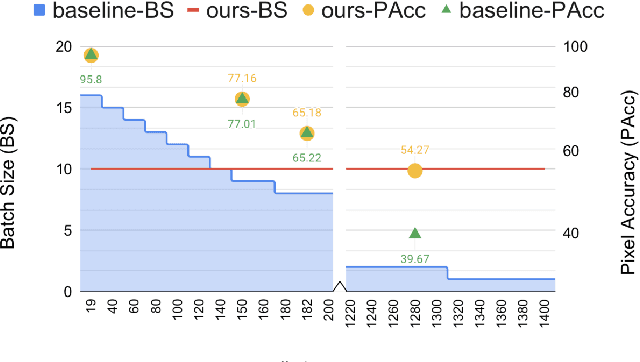
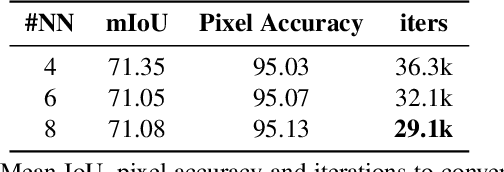
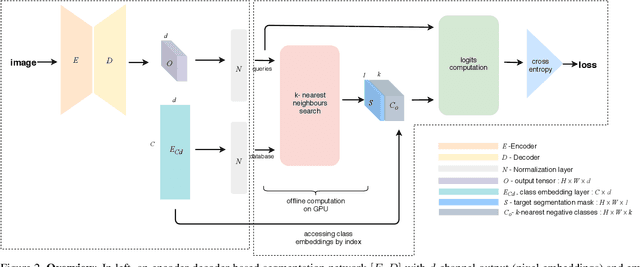

The state-of-the-art object detection and image classification methods can perform impressively on more than 9k and 10k classes, respectively. In contrast, the number of classes in semantic segmentation datasets is relatively limited. This is not surprising when the restrictions caused by the lack of labeled data and high computation demand for segmentation are considered. In this paper, we propose a novel training methodology to train and scale the existing semantic segmentation models for a large number of semantic classes without increasing the memory overhead. In our embedding-based scalable segmentation approach, we reduce the space complexity of the segmentation model's output from O(C) to O(1), propose an approximation method for ground-truth class probability, and use it to compute cross-entropy loss. The proposed approach is general and can be adopted by any state-of-the-art segmentation model to gracefully scale it for any number of semantic classes with only one GPU. Our approach achieves similar, and in some cases, even better mIoU for Cityscapes, Pascal VOC, ADE20k, COCO-Stuff10k datasets when adopted to DeeplabV3+ model with different backbones. We demonstrate a clear benefit of our approach on a dataset with 1284 classes, bootstrapped from LVIS and COCO annotations, with three times better mIoU than the DeeplabV3+ model.
Uncalibrated Neural Inverse Rendering for Photometric Stereo of General Surfaces
Dec 12, 2020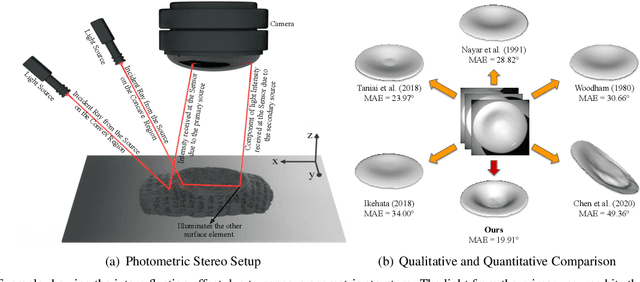
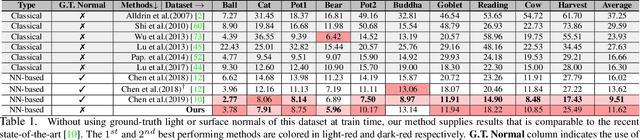
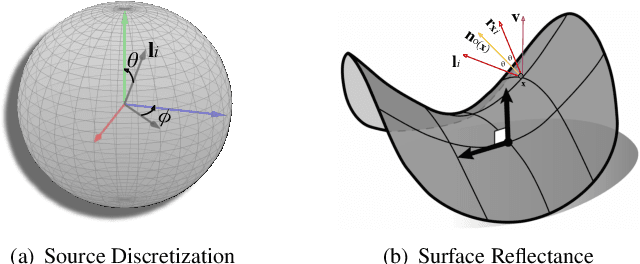

This paper presents an uncalibrated deep neural network framework for the photometric stereo problem. For training models to solve the problem, existing neural network-based methods either require exact light directions or ground-truth surface normals of the object or both. However, in practice, it is challenging to procure both of this information precisely, which restricts the broader adoption of photometric stereo algorithms for vision application. To bypass this difficulty, we propose an uncalibrated neural inverse rendering approach to this problem. Our method first estimates the light directions from the input images and then optimizes an image reconstruction loss to calculate the surface normals, bidirectional reflectance distribution function value, and depth. Additionally, our formulation explicitly models the concave and convex parts of a complex surface to consider the effects of interreflections in the image formation process. Extensive evaluation of the proposed method on the challenging subjects generally shows comparable or better results than the supervised and classical approaches.
Quantifying Aleatoric and Epistemic Uncertainty Using Density Estimation in Latent Space
Dec 05, 2020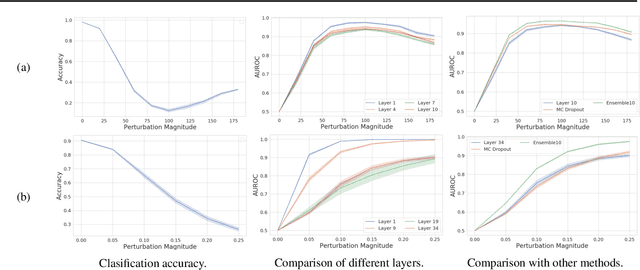
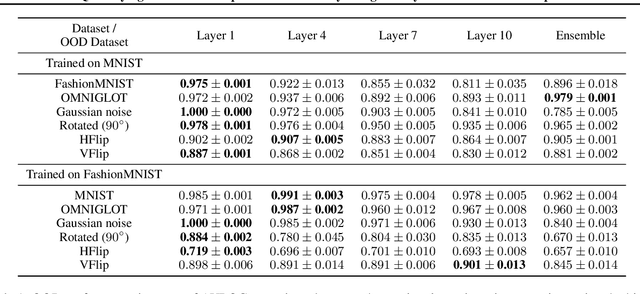

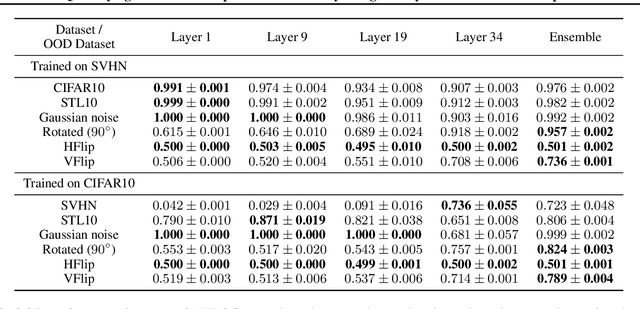
The distribution of a neural network's latent representations has been successfully used to detect Out-of-Distribution (OOD) data. Since OOD detection denotes a popular benchmark for epistemic uncertainty estimates, this raises the question of a deeper correlation. This work investigates whether the distribution of latent representations indeed contains information about the uncertainty associated with the predictions of a neural network. Prior work identifies epistemic uncertainty with the surprise, thus the negative log-likelihood, of observing a particular latent representation, which we verify empirically. Moreover, we demonstrate that the output-conditional distribution of hidden representations allows quantifying aleatoric uncertainty via the entropy of the predictive distribution. We analyze epistemic and aleatoric uncertainty inferred from the representations of different layers and conclude with the exciting finding that the hidden repesentations of a deterministic neural network indeed contain information about its uncertainty. We verify our findings on both classification and regression models.
Understanding Bird's-Eye View Semantic HD-Maps Using an Onboard Monocular Camera
Dec 05, 2020

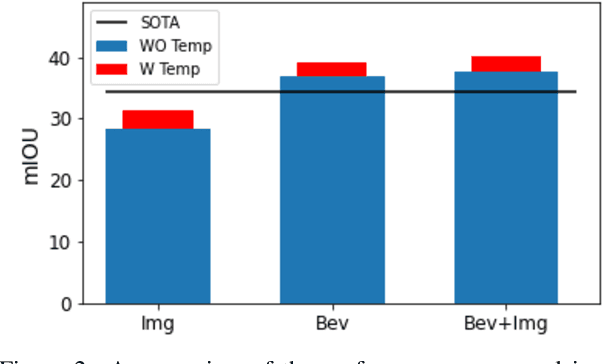

Autonomous navigation requires scene understanding of the action-space to move or anticipate events. For planner agents moving on the ground plane, such as autonomous vehicles, this translates to scene understanding in the bird's-eye view. However, the onboard cameras of autonomous cars are customarily mounted horizontally for a better view of the surrounding. In this work, we study scene understanding in the form of online estimation of semantic bird's-eye-view HD-maps using the video input from a single onboard camera. We study three key aspects of this task, image-level understanding, BEV level understanding, and the aggregation of temporal information. Based on these three pillars we propose a novel architecture that combines these three aspects. In our extensive experiments, we demonstrate that the considered aspects are complementary to each other for HD-map understanding. Furthermore, the proposed architecture significantly surpasses the current state-of-the-art.
Learning from Simulation, Racing in Reality
Nov 26, 2020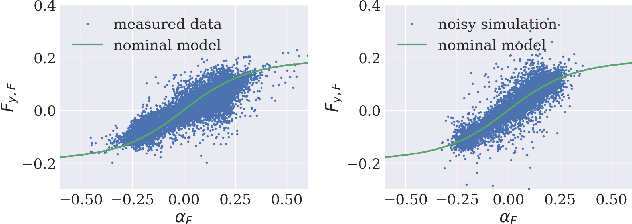
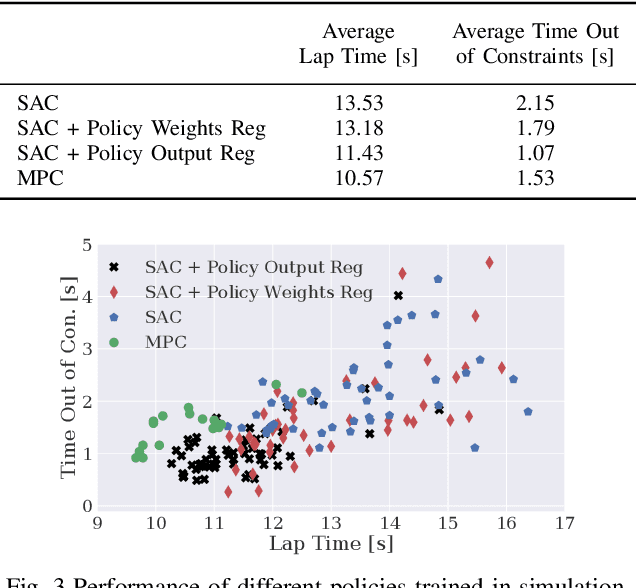
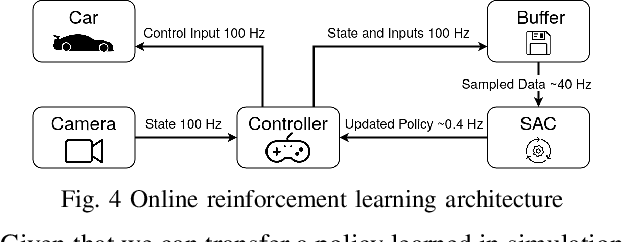
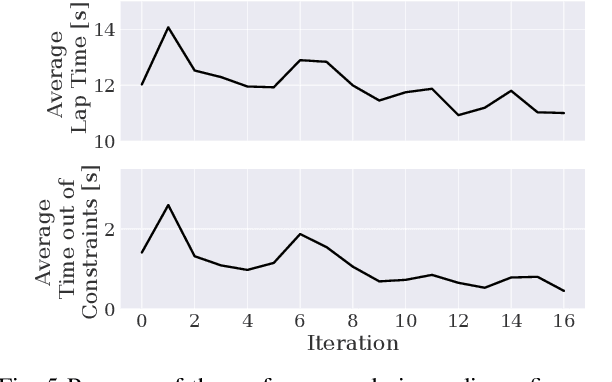
We present a reinforcement learning-based solution to autonomously race on a miniature race car platform. We show that a policy that is trained purely in simulation using a relatively simple vehicle model, including model randomization, can be successfully transferred to the real robotic setup. We achieve this by using novel policy output regularization approach and a lifted action space which enables smooth actions but still aggressive race car driving. We show that this regularized policy does outperform the Soft Actor Critic (SAC) baseline method, both in simulation and on the real car, but it is still outperformed by a Model Predictive Controller (MPC) state of the art method. The refinement of the policy with three hours of real-world interaction data allows the reinforcement learning policy to achieve lap times similar to the MPC controller while reducing track constraint violations by 50%.
3D CNNs with Adaptive Temporal Feature Resolutions
Nov 17, 2020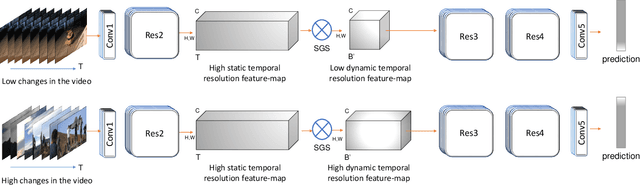

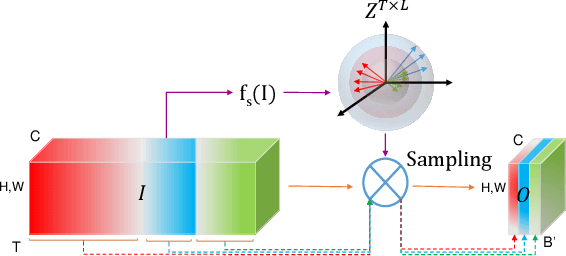

While state-of-the-art 3D Convolutional Neural Networks (CNN) achieve very good results on action recognition datasets, they are computationally very expensive and require many GFLOPs. While the GFLOPs of a 3D CNN can be decreased by reducing the temporal feature resolution within the network, there is no setting that is optimal for all input clips. In this work, we, therefore, introduce a differentiable Similarity Guided Sampling (SGS) module, which can be plugged into any existing 3D CNN architecture. SGS empowers 3D CNNs by learning the similarity of temporal features and grouping similar features together. As a result, the temporal feature resolution is not anymore static but it varies for each input video clip. By integrating SGS as an additional layer within current 3D CNNs, we can convert them into much more efficient 3D CNNs with adaptive temporal feature resolutions (ATFR). Our evaluations show that the proposed module improves the state-of-the-art by reducing the computational cost (GFLOPs)by half while preserving or even improving the accuracy. We evaluate our module by adding it to multiple state-of-the-art 3D CNNs on various datasets such as Kinetics-600, Kinetics-400, mini-Kinetics, Something-Something V2, UCF101, and HMDB51
Zero-Pair Image to Image Translation using Domain Conditional Normalization
Nov 11, 2020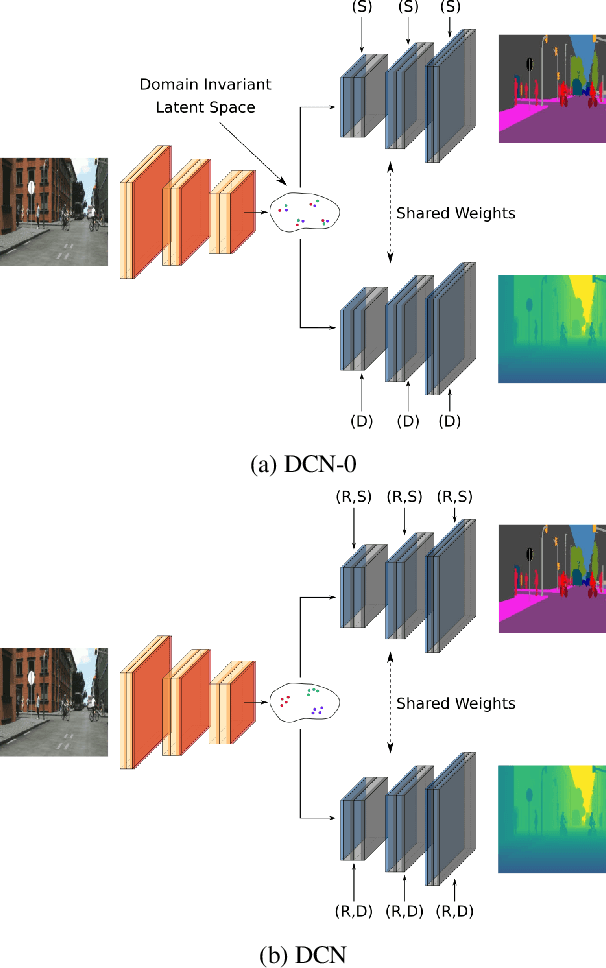
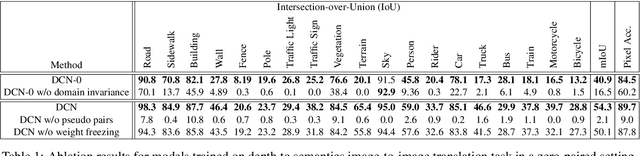
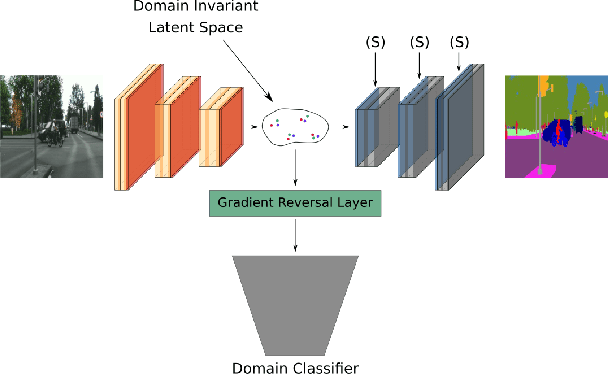

In this paper, we propose an approach based on domain conditional normalization (DCN) for zero-pair image-to-image translation, i.e., translating between two domains which have no paired training data available but each have paired training data with a third domain. We employ a single generator which has an encoder-decoder structure and analyze different implementations of domain conditional normalization to obtain the desired target domain output. The validation benchmark uses RGB-depth pairs and RGB-semantic pairs for training and compares performance for the depth-semantic translation task. The proposed approaches improve in qualitative and quantitative terms over the compared methods, while using much fewer parameters. Code available at https://github.com/samarthshukla/dcn
Neural Architecture Search of SPD Manifold Networks
Oct 27, 2020

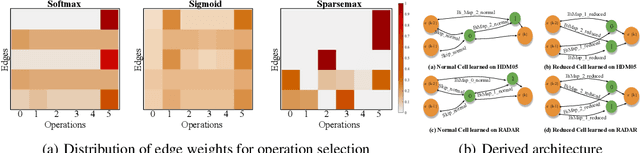

In this paper, we propose a new neural architecture search (NAS) problem of Symmetric Positive Definite (SPD) manifold networks. Unlike the conventional NAS problem, our problem requires to search for a unique computational cell called the SPD cell. This SPD cell serves as a basic building block of SPD neural architectures. An efficient solution to our problem is important to minimize the extraneous manual effort in the SPD neural architecture design. To accomplish this goal, we first introduce a geometrically rich and diverse SPD neural architecture search space for an efficient SPD cell design. Further, we model our new NAS problem using the supernet strategy which models the architecture search problem as a one-shot training process of a single supernet. Based on the supernet modeling, we exploit a differentiable NAS algorithm on our relaxed continuous search space for SPD neural architecture search. Statistical evaluation of our method on drone, action, and emotion recognition tasks mostly provides better results than the state-of-the-art SPD networks and NAS algorithms. Empirical results show that our algorithm excels in discovering better SPD network design, and providing models that are more than 3 times lighter than searched by state-of-the-art NAS algorithms.
Self-Supervised Shadow Removal
Oct 22, 2020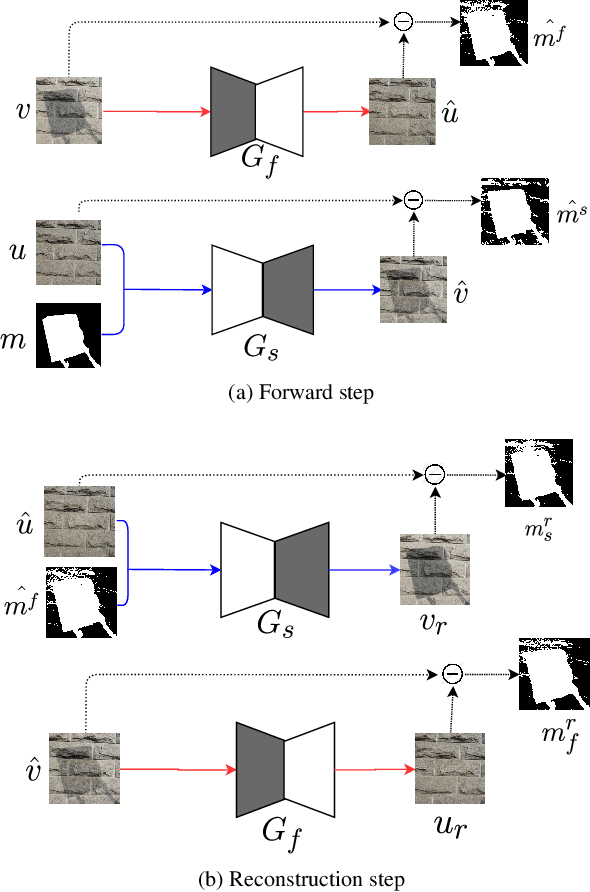



Shadow removal is an important computer vision task aiming at the detection and successful removal of the shadow produced by an occluded light source and a photo-realistic restoration of the image contents. Decades of re-search produced a multitude of hand-crafted restoration techniques and, more recently, learned solutions from shad-owed and shadow-free training image pairs. In this work,we propose an unsupervised single image shadow removal solution via self-supervised learning by using a conditioned mask. In contrast to existing literature, we do not require paired shadowed and shadow-free images, instead we rely on self-supervision and jointly learn deep models to remove and add shadows to images. We validate our approach on the recently introduced ISTD and USR datasets. We largely improve quantitatively and qualitatively over the compared methods and set a new state-of-the-art performance in single image shadow removal.
Facial Emotion Recognition with Noisy Multi-task Annotations
Oct 19, 2020
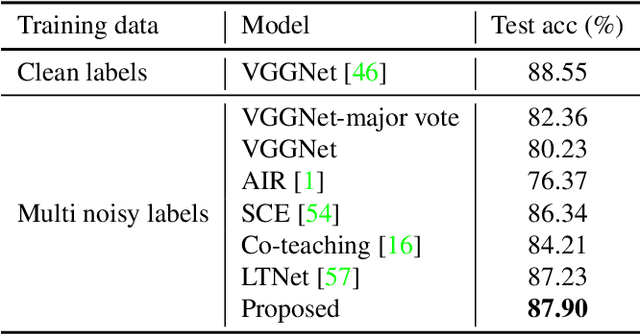
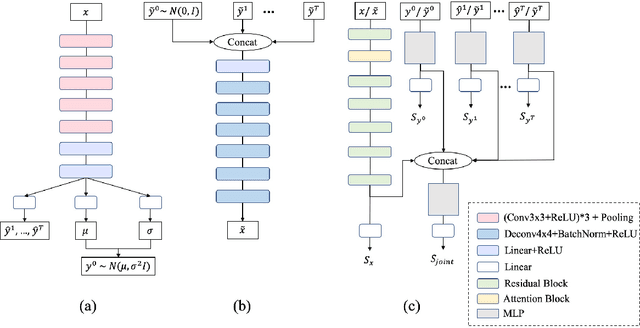
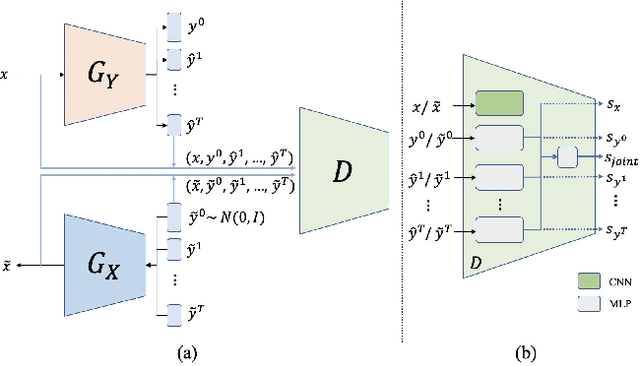
Human emotions can be inferred from facial expressions. However, the annotations of facial expressions are often highly noisy in common emotion coding models, including categorical and dimensional ones. To reduce human labelling effort on multi-task labels, we introduce a new problem of facial emotion recognition with noisy multi-task annotations. For this new problem, we suggest a formulation from the point of joint distribution match view, which aims at learning more reliable correlations among raw facial images and multi-task labels, resulting in the reduction of noise influence. In our formulation, we exploit a new method to enable the emotion prediction and the joint distribution learning in a unified adversarial learning game. Evaluation throughout extensive experiments studies the real setups of the suggested new problem, as well as the clear superiority of the proposed method over the state-of-the-art competing methods on either the synthetic noisy labeled CIFAR-10 or practical noisy multi-task labeled RAF and AffectNet.