 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Deep Semi-supervised Learning: An Empirical Distribution Alignment Framework and Its Generalization Bound
Mar 13, 2022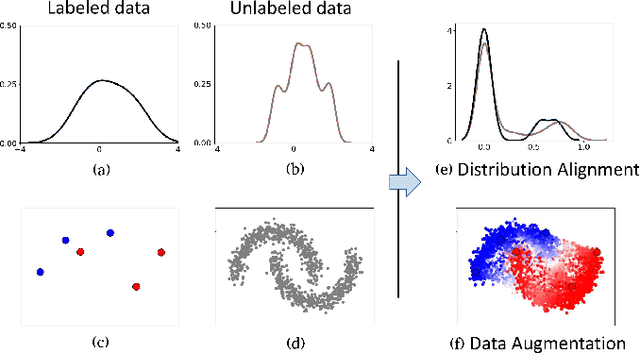
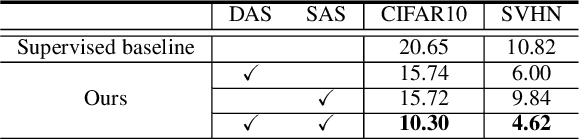
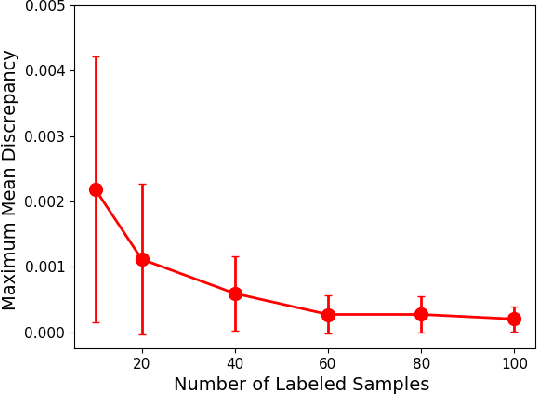
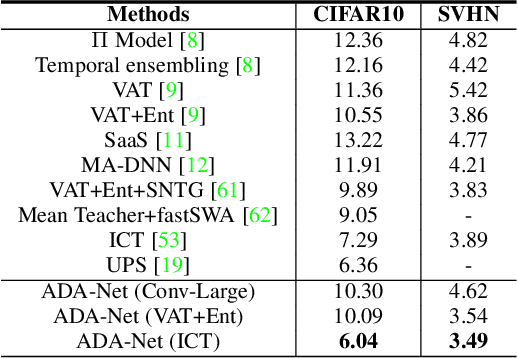
In this work, we revisit the semi-supervised learning (SSL) problem from a new perspective of explicitly reducing empirical distribution mismatch between labeled and unlabeled samples. Benefited from this new perspective, we first propose a new deep semi-supervised learning framework called Semi-supervised Learning by Empirical Distribution Alignment (SLEDA), in which existing technologies from the domain adaptation community can be readily used to address the semi-supervised learning problem through reducing the empirical distribution distance between labeled and unlabeled data. Based on this framework, we also develop a new theoretical generalization bound for the research community to better understand the semi-supervised learning problem, in which we show the generalization error of semi-supervised learning can be effectively bounded by minimizing the training error on labeled data and the empirical distribution distance between labeled and unlabeled data. Building upon our new framework and the theoretical bound, we develop a simple and effective deep semi-supervised learning method called Augmented Distribution Alignment Network (ADA-Net) by simultaneously adopting the well-established adversarial training strategy from the domain adaptation community and a simple sample interpolation strategy for data augmentation. Additionally, we incorporate both strategies in our ADA-Net into two exiting SSL methods to further improve their generalization capability, which indicates that our new framework provides a complementary solution for solving the SSL problem. Our comprehensive experimental results on two benchmark datasets SVHN and CIFAR-10 for the semi-supervised image recognition task and another two benchmark datasets ModelNet40 and ShapeNet55 for the semi-supervised point cloud recognition task demonstrate the effectiveness of our proposed framework for SSL.
Coarse-to-Fine Sparse Transformer for Hyperspectral Image Reconstruction
Mar 09, 2022
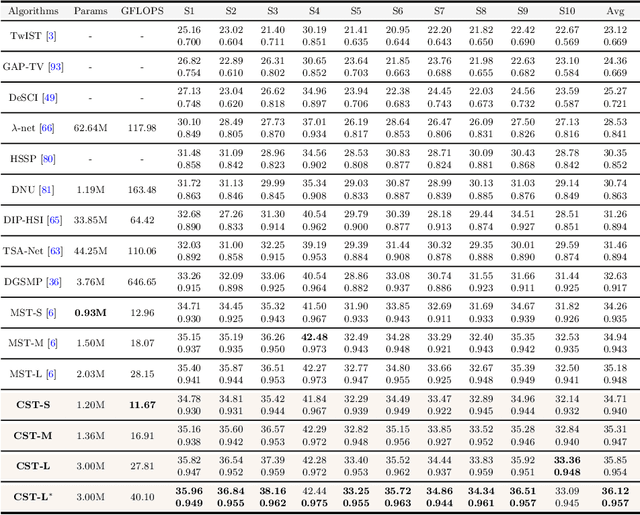
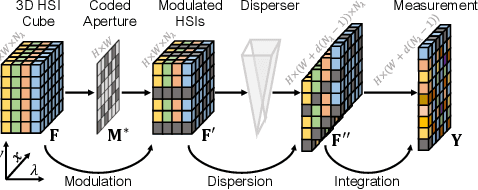
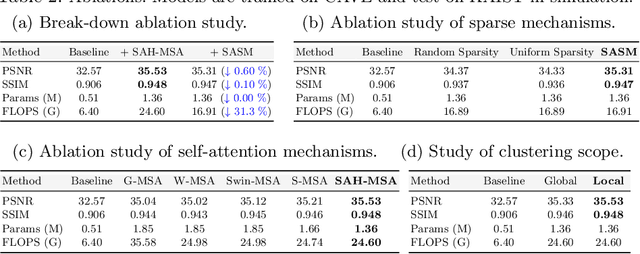
Many algorithms have been developed to solve the inverse problem of coded aperture snapshot spectral imaging (CASSI), i.e., recovering the 3D hyperspectral images (HSIs) from a 2D compressive measurement. In recent years, learning-based methods have demonstrated promising performance and dominated the mainstream research direction. However, existing CNN-based methods show limitations in capturing long-range dependencies and non-local self-similarity. Previous Transformer-based methods densely sample tokens, some of which are uninformative, and calculate the multi-head self-attention (MSA) between some tokens that are unrelated in content. This does not fit the spatially sparse nature of HSI signals and limits the model scalability. In this paper, we propose a novel Transformer-based method, coarse-to-fine sparse Transformer (CST), firstly embedding HSI sparsity into deep learning for HSI reconstruction. In particular, CST uses our proposed spectra-aware screening mechanism (SASM) for coarse patch selecting. Then the selected patches are fed into our customized spectra-aggregation hashing multi-head self-attention (SAH-MSA) for fine pixel clustering and self-similarity capturing. Comprehensive experiments show that our CST significantly outperforms state-of-the-art methods while requiring cheaper computational costs. The code and models will be made public.
Probabilistic Warp Consistency for Weakly-Supervised Semantic Correspondences
Mar 08, 2022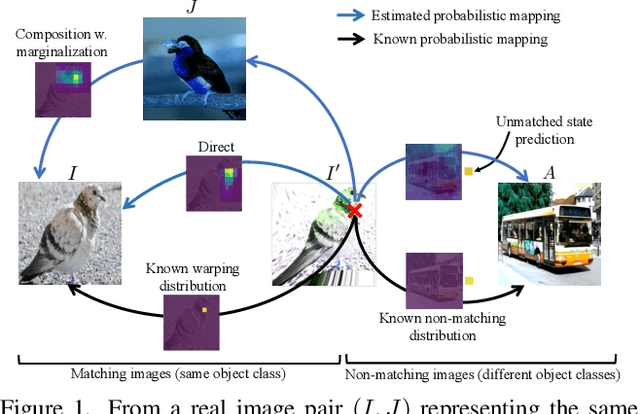
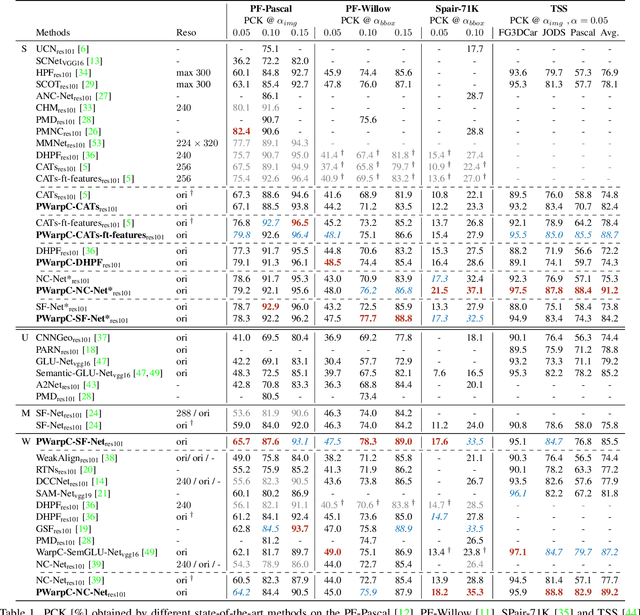
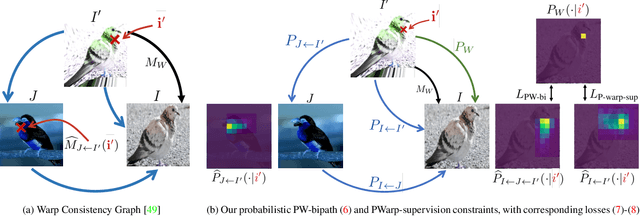
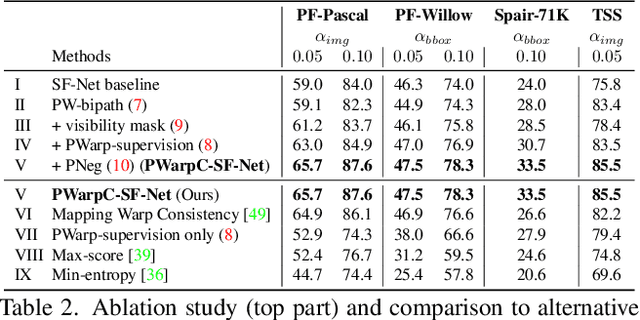
We propose Probabilistic Warp Consistency, a weakly-supervised learning objective for semantic matching. Our approach directly supervises the dense matching scores predicted by the network, encoded as a conditional probability distribution. We first construct an image triplet by applying a known warp to one of the images in a pair depicting different instances of the same object class. Our probabilistic learning objectives are then derived using the constraints arising from the resulting image triplet. We further account for occlusion and background clutter present in real image pairs by extending our probabilistic output space with a learnable unmatched state. To supervise it, we design an objective between image pairs depicting different object classes. We validate our method by applying it to four recent semantic matching architectures. Our weakly-supervised approach sets a new state-of-the-art on four challenging semantic matching benchmarks. Lastly, we demonstrate that our objective also brings substantial improvements in the strongly-supervised regime, when combined with keypoint annotations.
* Accepted at CVPR 2022 code: https://github.com/PruneTruong/DenseMatching
Barlow constrained optimization for Visual Question Answering
Mar 07, 2022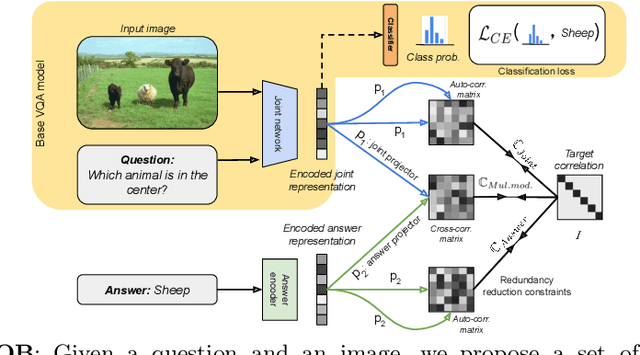
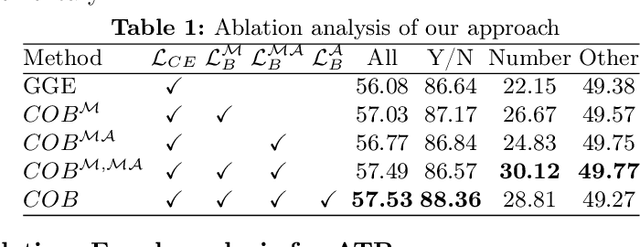
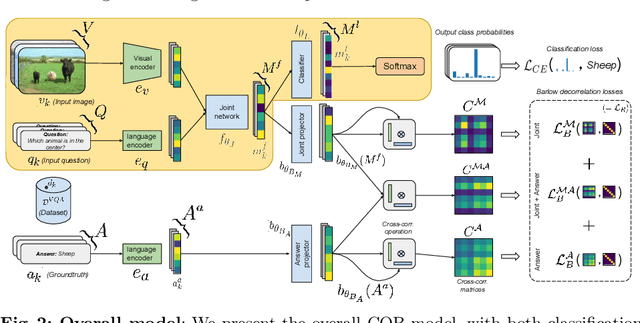
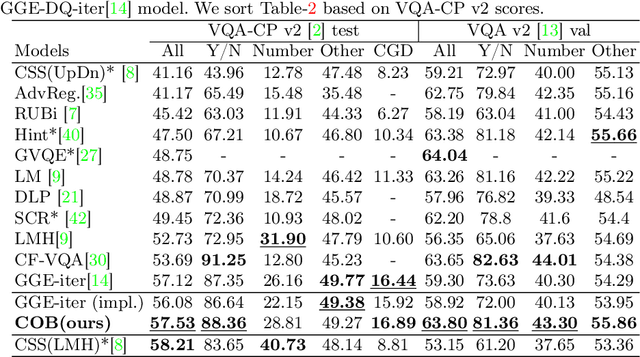
Visual question answering is a vision-and-language multimodal task, that aims at predicting answers given samples from the question and image modalities. Most recent methods focus on learning a good joint embedding space of images and questions, either by improving the interaction between these two modalities, or by making it a more discriminant space. However, how informative this joint space is, has not been well explored. In this paper, we propose a novel regularization for VQA models, Constrained Optimization using Barlow's theory (COB), that improves the information content of the joint space by minimizing the redundancy. It reduces the correlation between the learned feature components and thereby disentangles semantic concepts. Our model also aligns the joint space with the answer embedding space, where we consider the answer and image+question as two different `views' of what in essence is the same semantic information. We propose a constrained optimization policy to balance the categorical and redundancy minimization forces. When built on the state-of-the-art GGE model, the resulting model improves VQA accuracy by 1.4% and 4% on the VQA-CP v2 and VQA v2 datasets respectively. The model also exhibits better interpretability.
ZippyPoint: Fast Interest Point Detection, Description, and Matching through Mixed Precision Discretization
Mar 07, 2022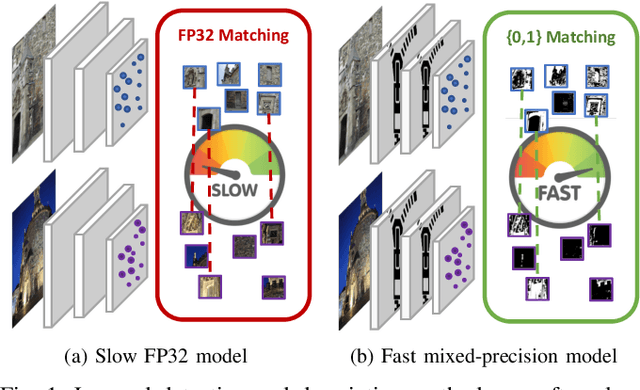
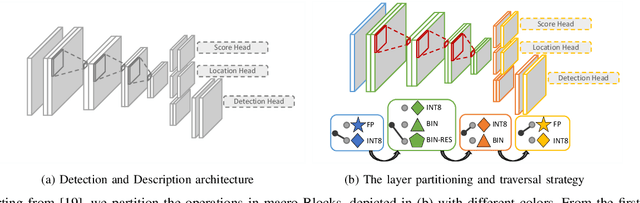
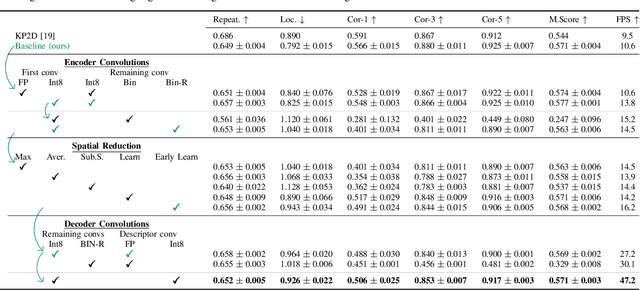

The design of more complex and powerful neural network models has significantly advanced the state-of-the-art in local feature detection and description. These advances can be attributed to deeper networks, improved training methodologies through self-supervision, or the introduction of new building blocks, such as graph neural networks for feature matching. However, in the pursuit of increased performance, efficient architectures that generate lightweight descriptors have received surprisingly little attention. In this paper, we investigate the adaptations neural networks for detection and description require in order to enable their use in embedded platforms. To that end, we investigate and adapt network quantization techniques for use in real-time applications. In addition, we revisit common practices in descriptor quantization and propose the use of a binary descriptor normalization layer, enabling the generation of distinctive length-invariant binary descriptors. ZippyPoint, our efficient network, runs at 47.2 fps on the Apple M1 CPU. This is up to 5x faster than other learned detection and description models, making it the only real-time learned network. ZippyPoint consistently outperforms all other binary detection and descriptor methods in visual localization and homography estimation tasks. Code and trained models will be released upon publication.
HDNet: High-resolution Dual-domain Learning for Spectral Compressive Imaging
Mar 04, 2022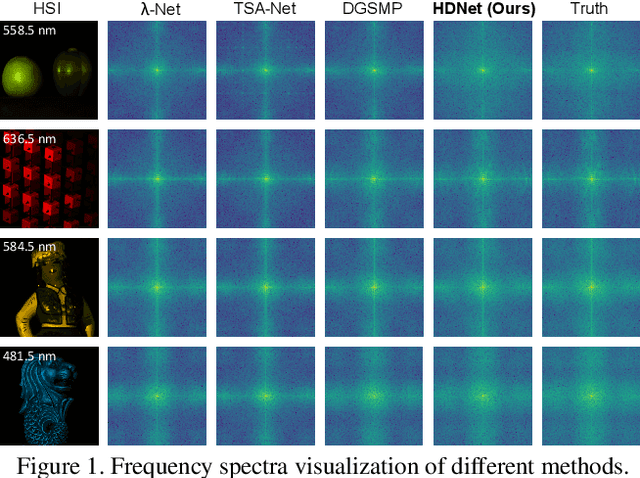
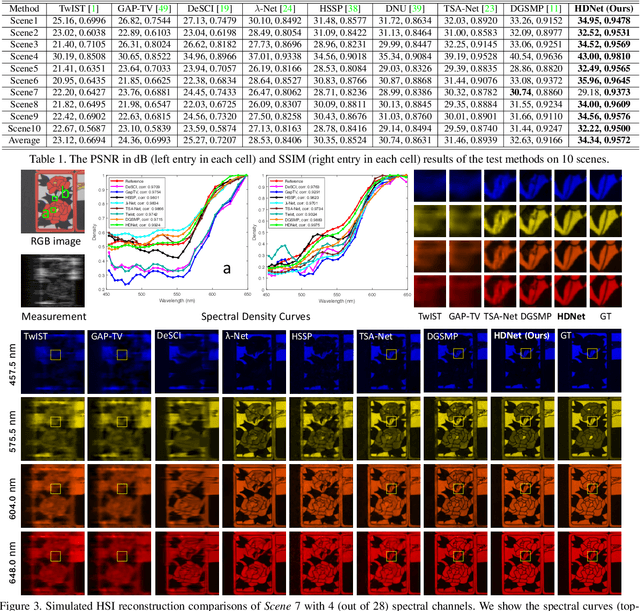
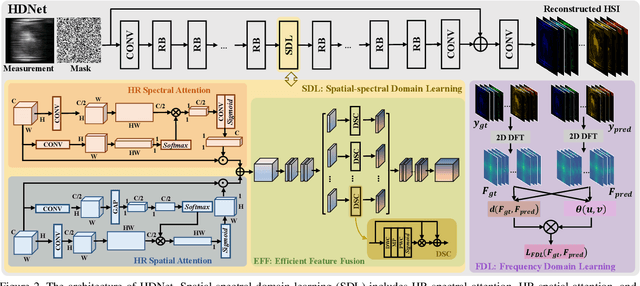

The rapid development of deep learning provides a better solution for the end-to-end reconstruction of hyperspectral image (HSI). However, existing learning-based methods have two major defects. Firstly, networks with self-attention usually sacrifice internal resolution to balance model performance against complexity, losing fine-grained high-resolution (HR) features. Secondly, even if the optimization focusing on spatial-spectral domain learning (SDL) converges to the ideal solution, there is still a significant visual difference between the reconstructed HSI and the truth. Therefore, we propose a high-resolution dual-domain learning network (HDNet) for HSI reconstruction. On the one hand, the proposed HR spatial-spectral attention module with its efficient feature fusion provides continuous and fine pixel-level features. On the other hand, frequency domain learning (FDL) is introduced for HSI reconstruction to narrow the frequency domain discrepancy. Dynamic FDL supervision forces the model to reconstruct fine-grained frequencies and compensate for excessive smoothing and distortion caused by pixel-level losses. The HR pixel-level attention and frequency-level refinement in our HDNet mutually promote HSI perceptual quality. Extensive quantitative and qualitative evaluation experiments show that our method achieves SOTA performance on simulated and real HSI datasets. Code and models will be released.
Pix2NeRF: Unsupervised Conditional $π$-GAN for Single Image to Neural Radiance Fields Translation
Feb 26, 2022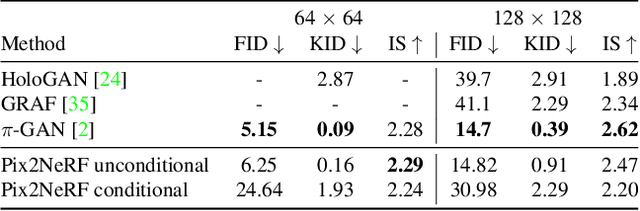
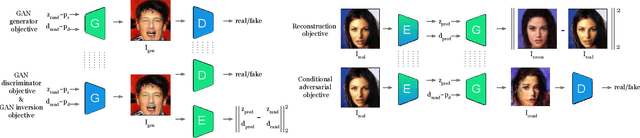
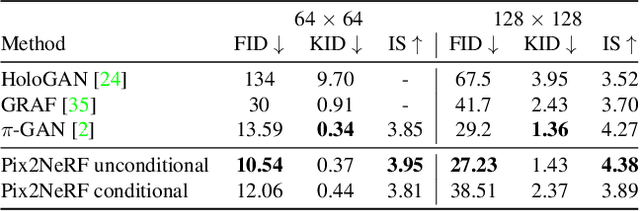

We propose a pipeline to generate Neural Radiance Fields~(NeRF) of an object or a scene of a specific class, conditioned on a single input image. This is a challenging task, as training NeRF requires multiple views of the same scene, coupled with corresponding poses, which are hard to obtain. Our method is based on $\pi$-GAN, a generative model for unconditional 3D-aware image synthesis, which maps random latent codes to radiance fields of a class of objects. We jointly optimize (1) the $\pi$-GAN objective to utilize its high-fidelity 3D-aware generation and (2) a carefully designed reconstruction objective. The latter includes an encoder coupled with $\pi$-GAN generator to form an auto-encoder. Unlike previous few-shot NeRF approaches, our pipeline is unsupervised, capable of being trained with independent images without 3D, multi-view, or pose supervision. Applications of our pipeline include 3d avatar generation, object-centric novel view synthesis with a single input image, and 3d-aware super-resolution, to name a few.
Adiabatic Quantum Computing for Multi Object Tracking
Feb 17, 2022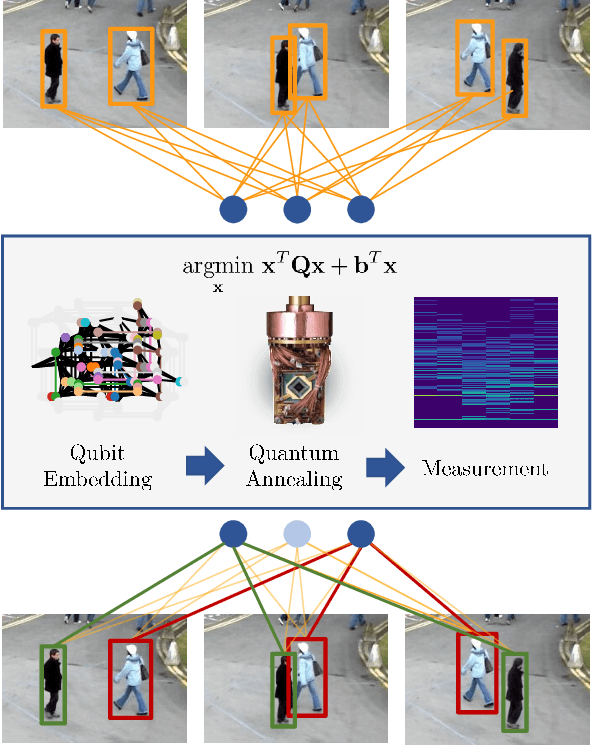
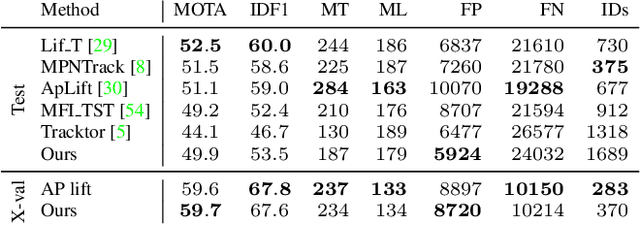
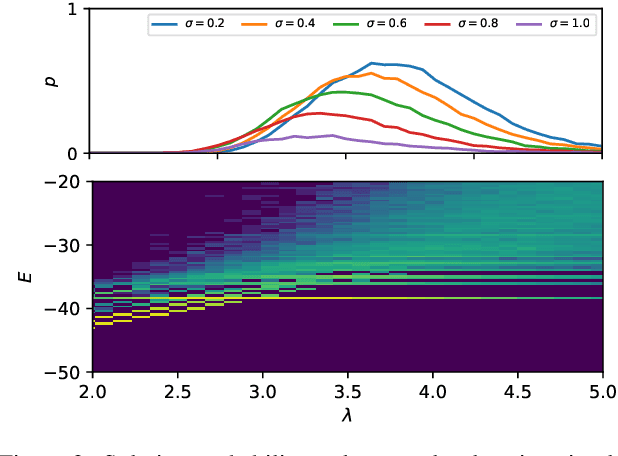
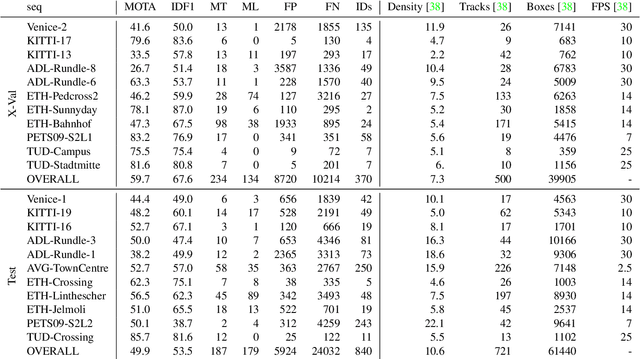
Multi-Object Tracking (MOT) is most often approached in the tracking-by-detection paradigm, where object detections are associated through time. The association step naturally leads to discrete optimization problems. As these optimization problems are often NP-hard, they can only be solved exactly for small instances on current hardware. Adiabatic quantum computing (AQC) offers a solution for this, as it has the potential to provide a considerable speedup on a range of NP-hard optimization problems in the near future. However, current MOT formulations are unsuitable for quantum computing due to their scaling properties. In this work, we therefore propose the first MOT formulation designed to be solved with AQC. We employ an Ising model that represents the quantum mechanical system implemented on the AQC. We show that our approach is competitive compared with state-of-the-art optimization-based approaches, even when using of-the-shelf integer programming solvers. Finally, we demonstrate that our MOT problem is already solvable on the current generation of real quantum computers for small examples, and analyze the properties of the measured solutions.
RePaint: Inpainting using Denoising Diffusion Probabilistic Models
Feb 07, 2022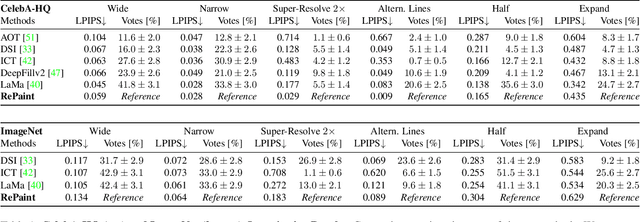
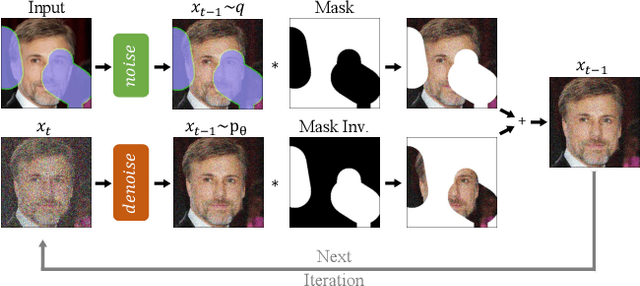


Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks. RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions. Github Repository: git.io/RePaint
Fast Online Video Super-Resolution with Deformable Attention Pyramid
Feb 03, 2022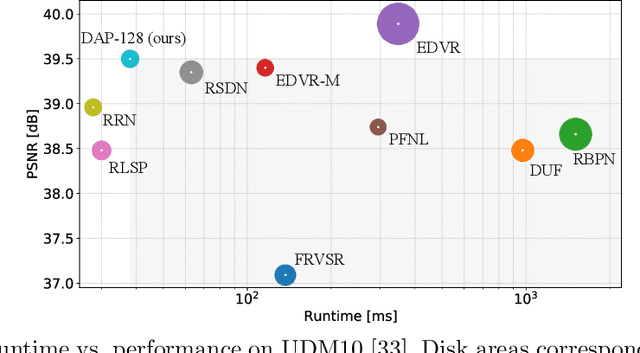

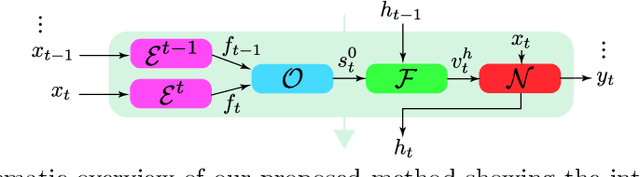

Video super-resolution (VSR) has many applications that pose strict causal, real-time, and latency constraints, including video streaming and TV. We address the VSR problem under these settings, which poses additional important challenges since information from future frames are unavailable. Importantly, designing efficient, yet effective frame alignment and fusion modules remain central problems. In this work, we propose a recurrent VSR architecture based on a deformable attention pyramid (DAP). Our DAP aligns and integrates information from the recurrent state into the current frame prediction. To circumvent the computational cost of traditional attention-based methods, we only attend to a limited number of spatial locations, which are dynamically predicted by the DAP. Comprehensive experiments and analysis of the proposed key innovations show the effectiveness of our approach. We significantly reduce processing time in comparison to state-of-the-art methods, while maintaining a high performance. We surpass state-of-the-art method EDVR-M on two standard benchmarks with a speed-up of over 3x.