 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUI-360$^\circ$: A Comprehensive Dataset and Benchmark for Computer-Using Agents
Nov 10, 2025We introduce GUI-360$^\circ$, a large-scale, comprehensive dataset and benchmark suite designed to advance computer-using agents (CUAs). CUAs present unique challenges and is constrained by three persistent gaps: a scarcity of real-world CUA tasks, the lack of automated collection-and-annotation pipelines for multi-modal trajectories, and the absence of a unified benchmark that jointly evaluates GUI grounding, screen parsing, and action prediction. GUI-360$^\circ$ addresses these gaps with an LLM-augmented, largely automated pipeline for query sourcing, environment-template construction, task instantiation, batched execution, and LLM-driven quality filtering. The released corpus contains over 1.2M executed action steps across thousands of trajectories in popular Windows office applications, and includes full-resolution screenshots, accessibility metadata when available, instantiated goals, intermediate reasoning traces, and both successful and failed action trajectories. The dataset supports three canonical tasks, GUI grounding, screen parsing, and action prediction, and a hybrid GUI+API action space that reflects modern agent designs. Benchmarking state-of-the-art vision--language models on GUI-360$^\circ$ reveals substantial out-of-the-box shortcomings in grounding and action prediction; supervised fine-tuning and reinforcement learning yield significant gains but do not close the gap to human-level reliability. We release GUI-360$^\circ$ and accompanying code to facilitate reproducible research and accelerate progress on robust desktop CUAs. The full dataset has been made public on https://huggingface.co/datasets/vyokky/GUI-360.
GUI-360: A Comprehensive Dataset and Benchmark for Computer-Using Agents
Nov 06, 2025We introduce GUI-360$^\circ$, a large-scale, comprehensive dataset and benchmark suite designed to advance computer-using agents (CUAs). CUAs present unique challenges and is constrained by three persistent gaps: a scarcity of real-world CUA tasks, the lack of automated collection-and-annotation pipelines for multi-modal trajectories, and the absence of a unified benchmark that jointly evaluates GUI grounding, screen parsing, and action prediction. GUI-360$^\circ$ addresses these gaps with an LLM-augmented, largely automated pipeline for query sourcing, environment-template construction, task instantiation, batched execution, and LLM-driven quality filtering. The released corpus contains over 1.2M executed action steps across thousands of trajectories in popular Windows office applications, and includes full-resolution screenshots, accessibility metadata when available, instantiated goals, intermediate reasoning traces, and both successful and failed action trajectories. The dataset supports three canonical tasks, GUI grounding, screen parsing, and action prediction, and a hybrid GUI+API action space that reflects modern agent designs. Benchmarking state-of-the-art vision--language models on GUI-360$^\circ$ reveals substantial out-of-the-box shortcomings in grounding and action prediction; supervised fine-tuning and reinforcement learning yield significant gains but do not close the gap to human-level reliability. We release GUI-360$^\circ$ and accompanying code to facilitate reproducible research and accelerate progress on robust desktop CUAs. The full dataset has been made public on https://huggingface.co/datasets/vyokky/GUI-360.
LiveOIBench: Can Large Language Models Outperform Human Contestants in Informatics Olympiads?
Oct 10, 2025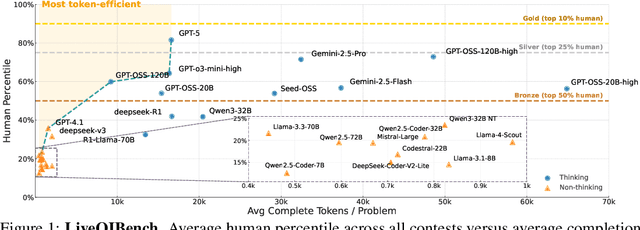
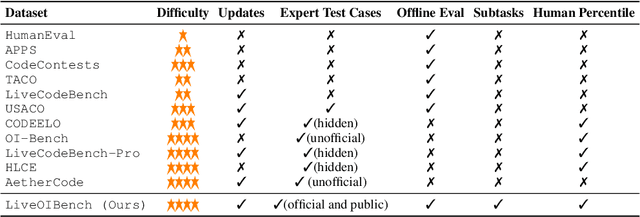
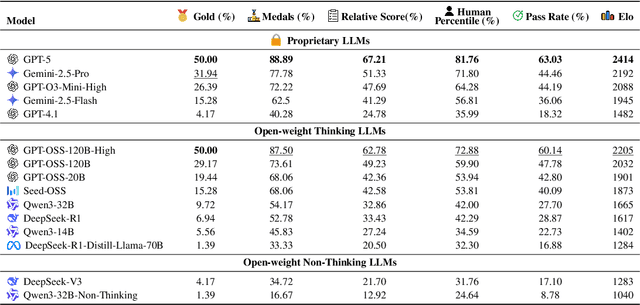
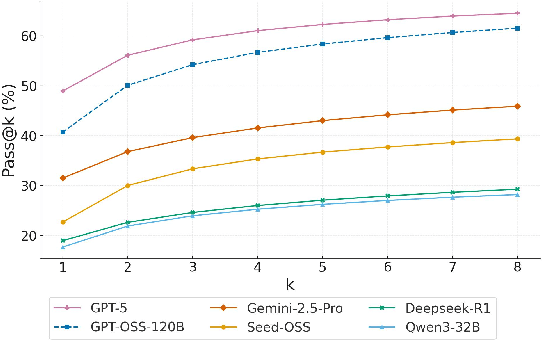
Competitive programming problems increasingly serve as valuable benchmarks to evaluate the coding capabilities of large language models (LLMs) due to their complexity and ease of verification. Yet, current coding benchmarks face limitations such as lack of exceptionally challenging problems, insufficient test case coverage, reliance on online platform APIs that limit accessibility. To address these issues, we introduce LiveOIBench, a comprehensive benchmark featuring 403 expert-curated Olympiad-level competitive programming problems, each with an average of 60 expert-designed test cases. The problems are sourced directly from 72 official Informatics Olympiads in different regions conducted between 2023 and 2025. LiveOIBench distinguishes itself through four key features: (1) meticulously curated high-quality tasks with detailed subtask rubrics and extensive private test cases; (2) direct integration of elite contestant performance data to enable informative comparison against top-performing humans; (3) planned continuous, contamination-free updates from newly released Olympiad problems; and (4) a self-contained evaluation system facilitating offline and easy-to-reproduce assessments. Benchmarking 32 popular general-purpose and reasoning LLMs, we find that GPT-5 achieves a notable 81.76th percentile, a strong result that nonetheless falls short of top human contestant performance, who usually place above 90th. In contrast, among open-weight reasoning models, GPT-OSS-120B achieves only a 60th percentile, underscoring significant capability disparities from frontier closed models. Detailed analyses indicate that robust reasoning models prioritize precise problem analysis over excessive exploration, suggesting future models should emphasize structured analysis and minimize unnecessary exploration. All data, code, and leaderboard results will be made publicly available on our website.
SimCast: Enhancing Precipitation Nowcasting with Short-to-Long Term Knowledge Distillation
Oct 09, 2025



Precipitation nowcasting predicts future radar sequences based on current observations, which is a highly challenging task driven by the inherent complexity of the Earth system. Accurate nowcasting is of utmost importance for addressing various societal needs, including disaster management, agriculture, transportation, and energy optimization. As a complementary to existing non-autoregressive nowcasting approaches, we investigate the impact of prediction horizons on nowcasting models and propose SimCast, a novel training pipeline featuring a short-to-long term knowledge distillation technique coupled with a weighted MSE loss to prioritize heavy rainfall regions. Improved nowcasting predictions can be obtained without introducing additional overhead during inference. As SimCast generates deterministic predictions, we further integrate it into a diffusion-based framework named CasCast, leveraging the strengths from probabilistic models to overcome limitations such as blurriness and distribution shift in deterministic outputs. Extensive experimental results on three benchmark datasets validate the effectiveness of the proposed framework, achieving mean CSI scores of 0.452 on SEVIR, 0.474 on HKO-7, and 0.361 on MeteoNet, which outperforms existing approaches by a significant margin.
* accepted by ICME 2025
Do LLMs Really Need 10+ Thoughts for "Find the Time 1000 Days Later"? Towards Structural Understanding of LLM Overthinking
Oct 09, 2025Models employing long chain-of-thought (CoT) reasoning have shown superior performance on complex reasoning tasks. Yet, this capability introduces a critical and often overlooked inefficiency -- overthinking -- models often engage in unnecessarily extensive reasoning even for simple queries, incurring significant computations without accuracy improvements. While prior work has explored solutions to mitigate overthinking, a fundamental gap remains in our understanding of its underlying causes. Most existing analyses are limited to superficial, profiling-based observations, failing to delve into LLMs' inner workings. This study introduces a systematic, fine-grained analyzer of LLMs' thought process to bridge the gap, TRACE. We first benchmark the overthinking issue, confirming that long-thinking models are five to twenty times slower on simple tasks with no substantial gains. We then use TRACE to first decompose the thought process into minimally complete sub-thoughts. Next, by inferring discourse relationships among sub-thoughts, we construct granular thought progression graphs and subsequently identify common thinking patterns for topically similar queries. Our analysis reveals two major patterns for open-weight thinking models -- Explorer and Late Landing. This finding provides evidence that over-verification and over-exploration are the primary drivers of overthinking in LLMs. Grounded in thought structures, we propose a utility-based definition of overthinking, which moves beyond length-based metrics. This revised definition offers a more insightful understanding of LLMs' thought progression, as well as practical guidelines for principled overthinking management.
Linear-Time Demonstration Selection for In-Context Learning via Gradient Estimation
Aug 27, 2025



This paper introduces an algorithm to select demonstration examples for in-context learning of a query set. Given a set of $n$ examples, how can we quickly select $k$ out of $n$ to best serve as the conditioning for downstream inference? This problem has broad applications in prompt tuning and chain-of-thought reasoning. Since model weights remain fixed during in-context learning, previous work has sought to design methods based on the similarity of token embeddings. This work proposes a new approach based on gradients of the output taken in the input embedding space. Our approach estimates model outputs through a first-order approximation using the gradients. Then, we apply this estimation to multiple randomly sampled subsets. Finally, we aggregate the sampled subset outcomes to form an influence score for each demonstration, and select $k$ most relevant examples. This procedure only requires pre-computing model outputs and gradients once, resulting in a linear-time algorithm relative to model and training set sizes. Extensive experiments across various models and datasets validate the efficiency of our approach. We show that the gradient estimation procedure yields approximations of full inference with less than $\mathbf{1}\%$ error across six datasets. This allows us to scale up subset selection that would otherwise run full inference by up to $\mathbf{37.7}\times$ on models with up to $34$ billion parameters, and outperform existing selection methods based on input embeddings by $\mathbf{11}\%$ on average.
Explainable Counterfactual Reasoning in Depression Medication Selection at Multi-Levels (Personalized and Population)
Aug 24, 2025Background: This study investigates how variations in Major Depressive Disorder (MDD) symptoms, quantified by the Hamilton Rating Scale for Depression (HAM-D), causally influence the prescription of SSRIs versus SNRIs. Methods: We applied explainable counterfactual reasoning with counterfactual explanations (CFs) to assess the impact of specific symptom changes on antidepressant choice. Results: Among 17 binary classifiers, Random Forest achieved highest performance (accuracy, F1, precision, recall, ROC-AUC near 0.85). Sample-based CFs revealed both local and global feature importance of individual symptoms in medication selection. Conclusions: Counterfactual reasoning elucidates which MDD symptoms most strongly drive SSRI versus SNRI selection, enhancing interpretability of AI-based clinical decision support systems. Future work should validate these findings on more diverse cohorts and refine algorithms for clinical deployment.
Reinforcement Learning enhanced Online Adaptive Clinical Decision Support via Digital Twin powered Policy and Treatment Effect optimized Reward
Aug 24, 2025Clinical decision support must adapt online under safety constraints. We present an online adaptive tool where reinforcement learning provides the policy, a patient digital twin provides the environment, and treatment effect defines the reward. The system initializes a batch-constrained policy from retrospective data and then runs a streaming loop that selects actions, checks safety, and queries experts only when uncertainty is high. Uncertainty comes from a compact ensemble of five Q-networks via the coefficient of variation of action values with a $\tanh$ compression. The digital twin updates the patient state with a bounded residual rule. The outcome model estimates immediate clinical effect, and the reward is the treatment effect relative to a conservative reference with a fixed z-score normalization from the training split. Online updates operate on recent data with short runs and exponential moving averages. A rule-based safety gate enforces vital ranges and contraindications before any action is applied. Experiments in a synthetic clinical simulator show low latency, stable throughput, a low expert query rate at fixed safety, and improved return against standard value-based baselines. The design turns an offline policy into a continuous, clinician-supervised system with clear controls and fast adaptation.
AdaptFlow: Adaptive Workflow Optimization via Meta-Learning
Aug 11, 2025Recent advances in large language models (LLMs) have sparked growing interest in agentic workflows, which are structured sequences of LLM invocations intended to solve complex tasks. However, existing approaches often rely on static templates or manually designed workflows, which limit adaptability to diverse tasks and hinder scalability. We propose AdaptFlow, a natural language-based meta-learning framework inspired by model-agnostic meta-learning (MAML). AdaptFlow learns a generalizable workflow initialization that enables rapid subtask-level adaptation. It employs a bi-level optimization scheme: the inner loop refines the workflow for a specific subtask using LLM-generated feedback, while the outer loop updates the shared initialization to perform well across tasks. This setup allows AdaptFlow to generalize effectively to unseen tasks by adapting the initialized workflow through language-guided modifications. Evaluated across question answering, code generation, and mathematical reasoning benchmarks, AdaptFlow consistently outperforms both manually crafted and automatically searched baselines, achieving state-of-the-art results with strong generalization across tasks and models. The source code and data are available at https://github.com/microsoft/DKI_LLM/tree/AdaptFlow/AdaptFlow.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.