 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
LiveOIBench: Can Large Language Models Outperform Human Contestants in Informatics Olympiads?
Oct 10, 2025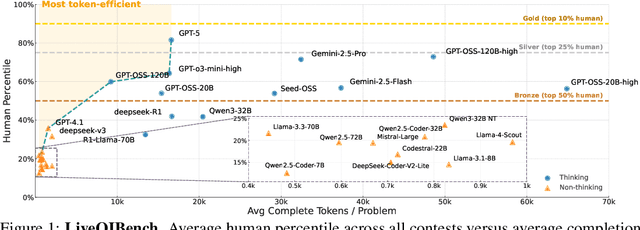
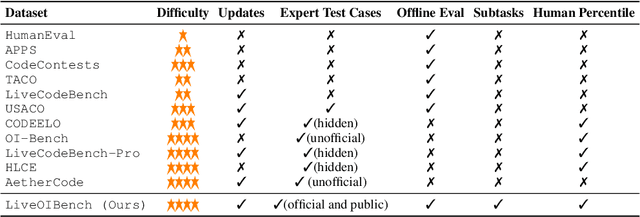
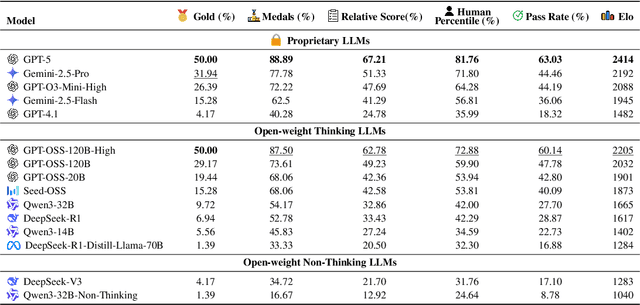
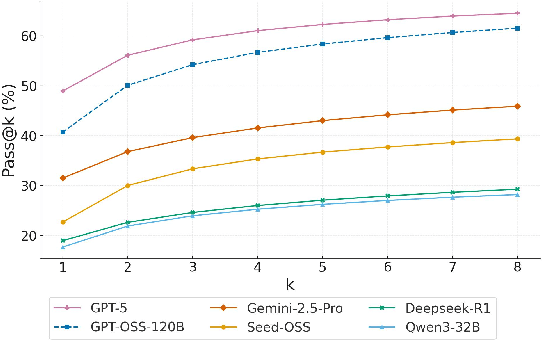
Competitive programming problems increasingly serve as valuable benchmarks to evaluate the coding capabilities of large language models (LLMs) due to their complexity and ease of verification. Yet, current coding benchmarks face limitations such as lack of exceptionally challenging problems, insufficient test case coverage, reliance on online platform APIs that limit accessibility. To address these issues, we introduce LiveOIBench, a comprehensive benchmark featuring 403 expert-curated Olympiad-level competitive programming problems, each with an average of 60 expert-designed test cases. The problems are sourced directly from 72 official Informatics Olympiads in different regions conducted between 2023 and 2025. LiveOIBench distinguishes itself through four key features: (1) meticulously curated high-quality tasks with detailed subtask rubrics and extensive private test cases; (2) direct integration of elite contestant performance data to enable informative comparison against top-performing humans; (3) planned continuous, contamination-free updates from newly released Olympiad problems; and (4) a self-contained evaluation system facilitating offline and easy-to-reproduce assessments. Benchmarking 32 popular general-purpose and reasoning LLMs, we find that GPT-5 achieves a notable 81.76th percentile, a strong result that nonetheless falls short of top human contestant performance, who usually place above 90th. In contrast, among open-weight reasoning models, GPT-OSS-120B achieves only a 60th percentile, underscoring significant capability disparities from frontier closed models. Detailed analyses indicate that robust reasoning models prioritize precise problem analysis over excessive exploration, suggesting future models should emphasize structured analysis and minimize unnecessary exploration. All data, code, and leaderboard results will be made publicly available on our website.
Toward LLM-Agent-Based Modeling of Transportation Systems: A Conceptual Framework
Dec 09, 2024In transportation system demand modeling and simulation, agent-based models and microsimulations are current state-of-the-art approaches. However, existing agent-based models still have some limitations on behavioral realism and resource demand that limit their applicability. In this study, leveraging the emerging technology of large language models (LLMs) and LLM-based agents, we propose a general LLM-agent-based modeling framework for transportation systems. We argue that LLM agents not only possess the essential capabilities to function as agents but also offer promising solutions to overcome some limitations of existing agent-based models. Our conceptual framework design closely replicates the decision-making and interaction processes and traits of human travelers within transportation networks, and we demonstrate that the proposed systems can meet critical behavioral criteria for decision-making and learning behaviors using related studies and a demonstrative example of LLM agents' learning and adjustment in the bottleneck setting. Although further refinement of the LLM-agent-based modeling framework is necessary, we believe that this approach has the potential to improve transportation system modeling and simulation.