 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveOIBench: Can Large Language Models Outperform Human Contestants in Informatics Olympiads?
Oct 10, 2025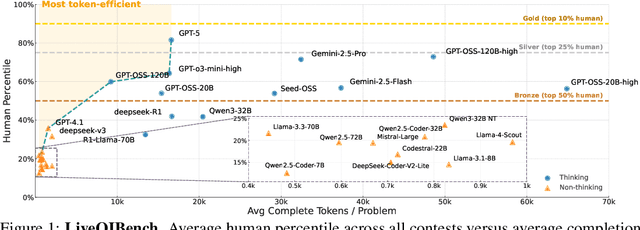
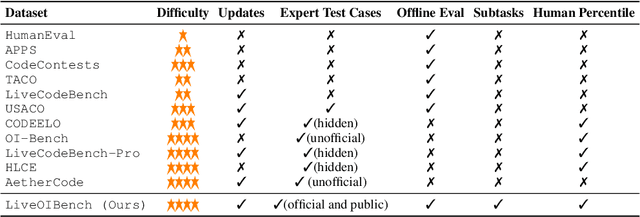
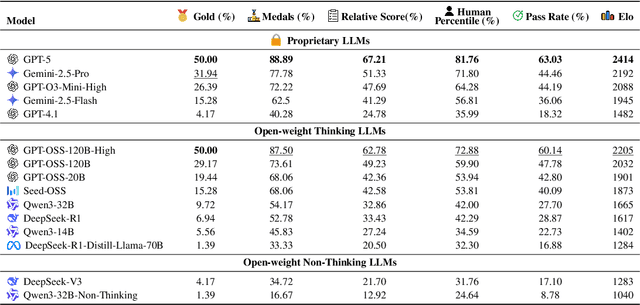
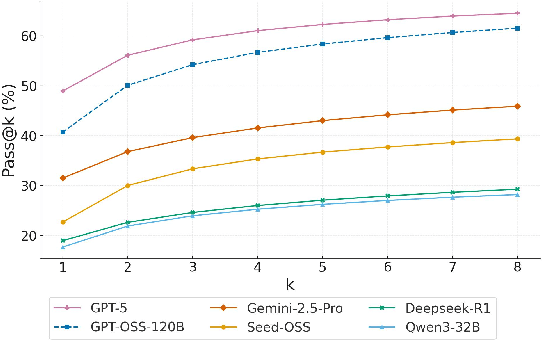
Competitive programming problems increasingly serve as valuable benchmarks to evaluate the coding capabilities of large language models (LLMs) due to their complexity and ease of verification. Yet, current coding benchmarks face limitations such as lack of exceptionally challenging problems, insufficient test case coverage, reliance on online platform APIs that limit accessibility. To address these issues, we introduce LiveOIBench, a comprehensive benchmark featuring 403 expert-curated Olympiad-level competitive programming problems, each with an average of 60 expert-designed test cases. The problems are sourced directly from 72 official Informatics Olympiads in different regions conducted between 2023 and 2025. LiveOIBench distinguishes itself through four key features: (1) meticulously curated high-quality tasks with detailed subtask rubrics and extensive private test cases; (2) direct integration of elite contestant performance data to enable informative comparison against top-performing humans; (3) planned continuous, contamination-free updates from newly released Olympiad problems; and (4) a self-contained evaluation system facilitating offline and easy-to-reproduce assessments. Benchmarking 32 popular general-purpose and reasoning LLMs, we find that GPT-5 achieves a notable 81.76th percentile, a strong result that nonetheless falls short of top human contestant performance, who usually place above 90th. In contrast, among open-weight reasoning models, GPT-OSS-120B achieves only a 60th percentile, underscoring significant capability disparities from frontier closed models. Detailed analyses indicate that robust reasoning models prioritize precise problem analysis over excessive exploration, suggesting future models should emphasize structured analysis and minimize unnecessary exploration. All data, code, and leaderboard results will be made publicly available on our website.
CLASH: Evaluating Language Models on Judging High-Stakes Dilemmas from Multiple Perspectives
Apr 15, 2025



Navigating high-stakes dilemmas involving conflicting values is challenging even for humans, let alone for AI. Yet prior work in evaluating the reasoning capabilities of large language models (LLMs) in such situations has been limited to everyday scenarios. To close this gap, this work first introduces CLASH (Character perspective-based LLM Assessments in Situations with High-stakes), a meticulously curated dataset consisting of 345 high-impact dilemmas along with 3,795 individual perspectives of diverse values. In particular, we design CLASH in a way to support the study of critical aspects of value-based decision-making processes which are missing from prior work, including understanding decision ambivalence and psychological discomfort as well as capturing the temporal shifts of values in characters' perspectives. By benchmarking 10 open and closed frontier models, we uncover several key findings. (1) Even the strongest models, such as GPT-4o and Claude-Sonnet, achieve less than 50% accuracy in identifying situations where the decision should be ambivalent, while they perform significantly better in clear-cut scenarios. (2) While LLMs reasonably predict psychological discomfort as marked by human, they inadequately comprehend perspectives involving value shifts, indicating a need for LLMs to reason over complex values. (3) Our experiments also reveal a significant correlation between LLMs' value preferences and their steerability towards a given value. (4) Finally, LLMs exhibit greater steerability when engaged in value reasoning from a third-party perspective, compared to a first-person setup, though certain value pairs benefit uniquely from the first-person framing.