 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiP-GO: A Diffusion Pruner via Few-step Gradient Optimization
Oct 22, 2024



Diffusion models have achieved remarkable progress in the field of image generation due to their outstanding capabilities. However, these models require substantial computing resources because of the multi-step denoising process during inference. While traditional pruning methods have been employed to optimize these models, the retraining process necessitates large-scale training datasets and extensive computational costs to maintain generalization ability, making it neither convenient nor efficient. Recent studies attempt to utilize the similarity of features across adjacent denoising stages to reduce computational costs through simple and static strategies. However, these strategies cannot fully harness the potential of the similar feature patterns across adjacent timesteps. In this work, we propose a novel pruning method that derives an efficient diffusion model via a more intelligent and differentiable pruner. At the core of our approach is casting the model pruning process into a SubNet search process. Specifically, we first introduce a SuperNet based on standard diffusion via adding some backup connections built upon the similar features. We then construct a plugin pruner network and design optimization losses to identify redundant computation. Finally, our method can identify an optimal SubNet through few-step gradient optimization and a simple post-processing procedure. We conduct extensive experiments on various diffusion models including Stable Diffusion series and DiTs. Our DiP-GO approach achieves 4.4 x speedup for SD-1.5 without any loss of accuracy, significantly outperforming the previous state-of-the-art methods.
Diagram Formalization Enhanced Multi-Modal Geometry Problem Solver
Sep 09, 2024



Mathematical reasoning remains an ongoing challenge for AI models, especially for geometry problems that require both linguistic and visual signals. As the vision encoders of most MLLMs are trained on natural scenes, they often struggle to understand geometric diagrams, performing no better in geometry problem solving than LLMs that only process text. This limitation is amplified by the lack of effective methods for representing geometric relationships. To address these issues, we introduce the Diagram Formalization Enhanced Geometry Problem Solver (DFE-GPS), a new framework that integrates visual features, geometric formal language, and natural language representations. We propose a novel synthetic data approach and create a large-scale geometric dataset, SynthGeo228K, annotated with both formal and natural language captions, designed to enhance the vision encoder for a better understanding of geometric structures. Our framework improves MLLMs' ability to process geometric diagrams and extends their application to open-ended tasks on the formalgeo7k dataset.
Enhancing One-shot Pruned Pre-trained Language Models through Sparse-Dense-Sparse Mechanism
Aug 20, 2024



Pre-trained language models (PLMs) are engineered to be robust in contextual understanding and exhibit outstanding performance in various natural language processing tasks. However, their considerable size incurs significant computational and storage costs. Modern pruning strategies employ one-shot techniques to compress PLMs without the need for retraining on task-specific or otherwise general data; however, these approaches often lead to an indispensable reduction in performance. In this paper, we propose SDS, a Sparse-Dense-Sparse pruning framework to enhance the performance of the pruned PLMs from a weight distribution optimization perspective. We outline the pruning process in three steps. Initially, we prune less critical connections in the model using conventional one-shot pruning methods. Next, we reconstruct a dense model featuring a pruning-friendly weight distribution by reactivating pruned connections with sparse regularization. Finally, we perform a second pruning round, yielding a superior pruned model compared to the initial pruning. Experimental results demonstrate that SDS outperforms the state-of-the-art pruning techniques SparseGPT and Wanda under an identical sparsity configuration. For instance, SDS reduces perplexity by 9.13 on Raw-Wikitext2 and improves accuracy by an average of 2.05% across multiple zero-shot benchmarks for OPT-125M with 2:4 sparsity.
Towards Scale-Aware Full Surround Monodepth with Transformers
Jul 15, 2024



Full surround monodepth (FSM) methods can learn from multiple camera views simultaneously in a self-supervised manner to predict the scale-aware depth, which is more practical for real-world applications in contrast to scale-ambiguous depth from a standalone monocular camera. In this work, we focus on enhancing the scale-awareness of FSM methods for depth estimation. To this end, we propose to improve FSM from two perspectives: depth network structure optimization and training pipeline optimization. First, we construct a transformer-based depth network with neighbor-enhanced cross-view attention (NCA). The cross-attention modules can better aggregate the cross-view context in both global and neighboring views. Second, we formulate a transformer-based feature matching scheme with progressive training to improve the structure-from-motion (SfM) pipeline. That allows us to learn scale-awareness with sufficient matches and further facilitate network convergence by removing mismatches based on SfM loss. Experiments demonstrate that the resulting Scale-aware full surround monodepth (SA-FSM) method largely improves the scale-aware depth predictions without median-scaling at the test time, and performs favorably against the state-of-the-art FSM methods, e.g., surpassing SurroundDepth by 3.8% in terms of accuracy at delta<1.25 on the DDAD benchmark.
VIPS-Odom: Visual-Inertial Odometry Tightly-coupled with Parking Slots for Autonomous Parking
Jul 06, 2024Precise localization is of great importance for autonomous parking task since it provides service for the downstream planning and control modules, which significantly affects the system performance. For parking scenarios, dynamic lighting, sparse textures, and the instability of global positioning system (GPS) signals pose challenges for most traditional localization methods. To address these difficulties, we propose VIPS-Odom, a novel semantic visual-inertial odometry framework for underground autonomous parking, which adopts tightly-coupled optimization to fuse measurements from multi-modal sensors and solves odometry. Our VIPS-Odom integrates parking slots detected from the synthesized bird-eye-view (BEV) image with traditional feature points in the frontend, and conducts tightly-coupled optimization with joint constraints introduced by measurements from the inertial measurement unit, wheel speed sensor and parking slots in the backend. We develop a multi-object tracking framework to robustly track parking slots' states. To prove the superiority of our method, we equip an electronic vehicle with related sensors and build an experimental platform based on ROS2 system. Extensive experiments demonstrate the efficacy and advantages of our method compared with other baselines for parking scenarios.
Amphista: Accelerate LLM Inference with Bi-directional Multiple Drafting Heads in a Non-autoregressive Style
Jun 19, 2024



Large Language Models (LLMs) inherently use autoregressive decoding, which lacks parallelism in inference and results in significantly slow inference speeds, especially when hardware parallel accelerators and memory bandwidth are not fully utilized. In this work, we propose Amphista, a speculative decoding algorithm that adheres to a non-autoregressive decoding paradigm. Owing to the increased parallelism, our method demonstrates higher efficiency in inference compared to autoregressive methods. Specifically, Amphista models an Auto-embedding Block capable of parallel inference, incorporating bi-directional attention to enable interaction between different drafting heads. Additionally, Amphista implements Staged Adaptation Layers to facilitate the transition of semantic information from the base model's autoregressive inference to the drafting heads' non-autoregressive speculation, thereby achieving paradigm transformation and feature fusion. We conduct a series of experiments on a suite of Vicuna models using MT-Bench and Spec-Bench. For the Vicuna 33B model, Amphista achieves up to 2.75$\times$ and 1.40$\times$ wall-clock acceleration compared to vanilla autoregressive decoding and Medusa, respectively, while preserving lossless generation quality.
TernaryLLM: Ternarized Large Language Model
Jun 11, 2024



Large language models (LLMs) have achieved remarkable performance on Natural Language Processing (NLP) tasks, but they are hindered by high computational costs and memory requirements. Ternarization, an extreme form of quantization, offers a solution by reducing memory usage and enabling energy-efficient floating-point additions. However, applying ternarization to LLMs faces challenges stemming from outliers in both weights and activations. In this work, observing asymmetric outliers and non-zero means in weights, we introduce Dual Learnable Ternarization (DLT), which enables both scales and shifts to be learnable. We also propose Outlier-Friendly Feature Knowledge Distillation (OFF) to recover the information lost in extremely low-bit quantization. The proposed OFF can incorporate semantic information and is insensitive to outliers. At the core of OFF is maximizing the mutual information between features in ternarized and floating-point models using cosine similarity. Extensive experiments demonstrate that our TernaryLLM surpasses previous low-bit quantization methods on the standard text generation and zero-shot benchmarks for different LLM families. Specifically, for one of the most powerful open-source models, LLaMA-3, our approach (W1.58A16) outperforms the previous state-of-the-art method (W2A16) by 5.8 in terms of perplexity on C4 and by 8.2% in terms of average accuracy on zero-shot tasks.
LADDER: An Efficient Framework for Video Frame Interpolation
Apr 17, 2024



Video Frame Interpolation (VFI) is a crucial technique in various applications such as slow-motion generation, frame rate conversion, video frame restoration etc. This paper introduces an efficient video frame interpolation framework that aims to strike a favorable balance between efficiency and quality. Our framework follows a general paradigm consisting of a flow estimator and a refinement module, while incorporating carefully designed components. First of all, we adopt depth-wise convolution with large kernels in the flow estimator that simultaneously reduces the parameters and enhances the receptive field for encoding rich context and handling complex motion. Secondly, diverging from a common design for the refinement module with a UNet-structure (encoder-decoder structure), which we find redundant, our decoder-only refinement module directly enhances the result from coarse to fine features, offering a more efficient process. In addition, to address the challenge of handling high-definition frames, we also introduce an innovative HD-aware augmentation strategy during training, leading to consistent enhancement on HD images. Extensive experiments are conducted on diverse datasets, Vimeo90K, UCF101, Xiph and SNU-FILM. The results demonstrate that our approach achieves state-of-the-art performance with clear improvement while requiring much less FLOPs and parameters, reaching to a better spot for balancing efficiency and quality.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Sparse Laneformer
Apr 11, 2024
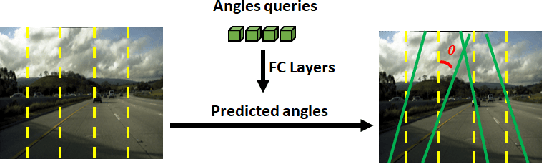


Lane detection is a fundamental task in autonomous driving, and has achieved great progress as deep learning emerges. Previous anchor-based methods often design dense anchors, which highly depend on the training dataset and remain fixed during inference. We analyze that dense anchors are not necessary for lane detection, and propose a transformer-based lane detection framework based on a sparse anchor mechanism. To this end, we generate sparse anchors with position-aware lane queries and angle queries instead of traditional explicit anchors. We adopt Horizontal Perceptual Attention (HPA) to aggregate the lane features along the horizontal direction, and adopt Lane-Angle Cross Attention (LACA) to perform interactions between lane queries and angle queries. We also propose Lane Perceptual Attention (LPA) based on deformable cross attention to further refine the lane predictions. Our method, named Sparse Laneformer, is easy-to-implement and end-to-end trainable. Extensive experiments demonstrate that Sparse Laneformer performs favorably against the state-of-the-art methods, e.g., surpassing Laneformer by 3.0% F1 score and O2SFormer by 0.7% F1 score with fewer MACs on CULane with the same ResNet-34 backbone.