 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Structured Pruning on Multilingual Pre-trained Models: Settings, Algorithms, and Efficiency
Apr 06, 2022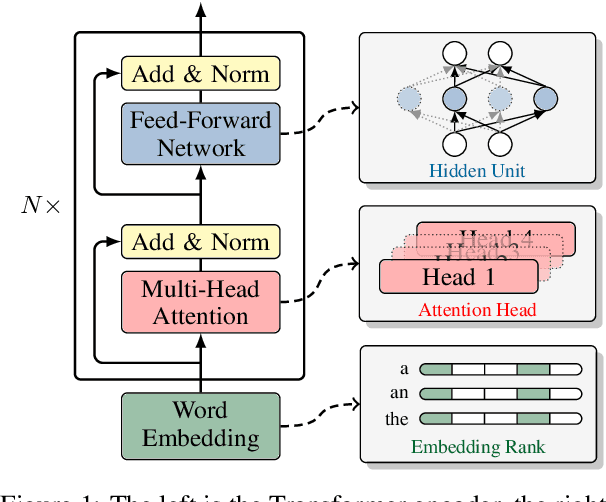
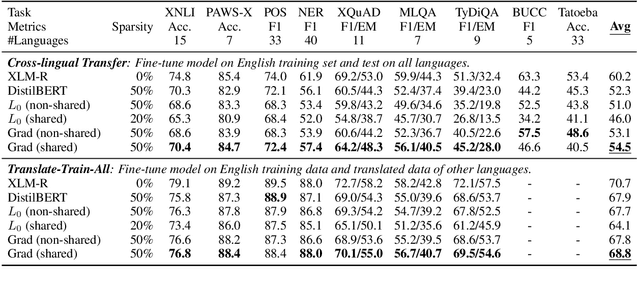
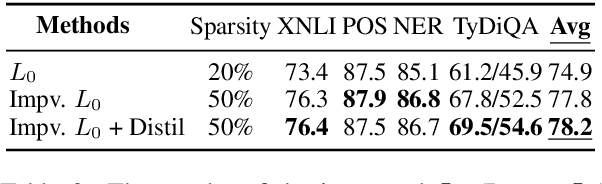
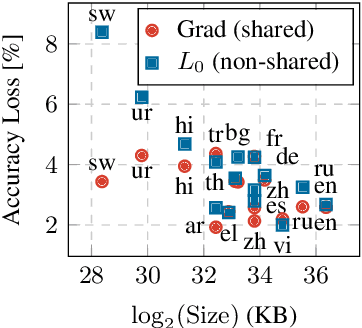
Structured pruning has been extensively studied on monolingual pre-trained language models and is yet to be fully evaluated on their multilingual counterparts. This work investigates three aspects of structured pruning on multilingual pre-trained language models: settings, algorithms, and efficiency. Experiments on nine downstream tasks show several counter-intuitive phenomena: for settings, individually pruning for each language does not induce a better result; for algorithms, the simplest method performs the best; for efficiency, a fast model does not imply that it is also small. To facilitate the comparison on all sparsity levels, we present Dynamic Sparsification, a simple approach that allows training the model once and adapting to different model sizes at inference. We hope this work fills the gap in the study of structured pruning on multilingual pre-trained models and sheds light on future research.
RBGNet: Ray-based Grouping for 3D Object Detection
Apr 05, 2022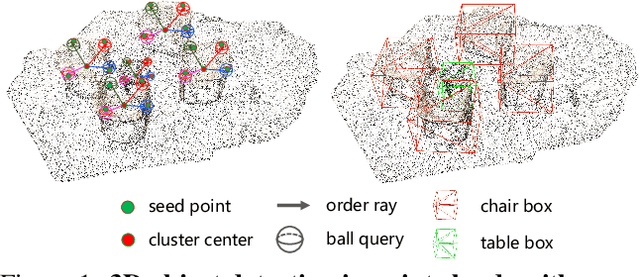

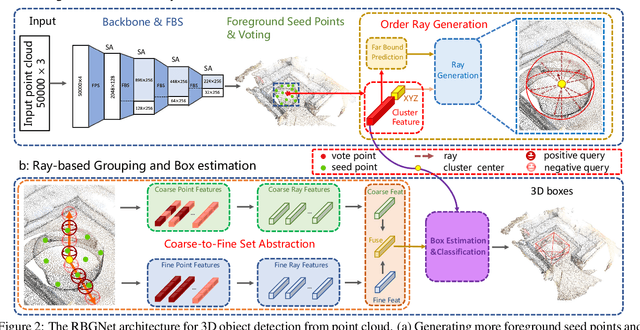
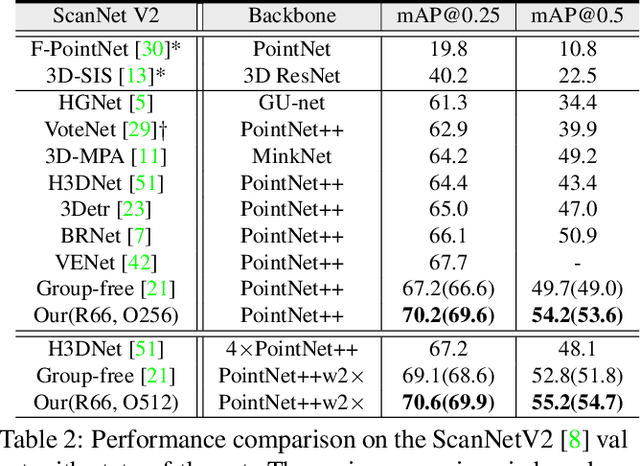
As a fundamental problem in computer vision, 3D object detection is experiencing rapid growth. To extract the point-wise features from the irregularly and sparsely distributed points, previous methods usually take a feature grouping module to aggregate the point features to an object candidate. However, these methods have not yet leveraged the surface geometry of foreground objects to enhance grouping and 3D box generation. In this paper, we propose the RBGNet framework, a voting-based 3D detector for accurate 3D object detection from point clouds. In order to learn better representations of object shape to enhance cluster features for predicting 3D boxes, we propose a ray-based feature grouping module, which aggregates the point-wise features on object surfaces using a group of determined rays uniformly emitted from cluster centers. Considering the fact that foreground points are more meaningful for box estimation, we design a novel foreground biased sampling strategy in downsample process to sample more points on object surfaces and further boost the detection performance. Our model achieves state-of-the-art 3D detection performance on ScanNet V2 and SUN RGB-D with remarkable performance gains. Code will be available at https://github.com/Haiyang-W/RBGNet.
Multi-View Transformer for 3D Visual Grounding
Apr 05, 2022
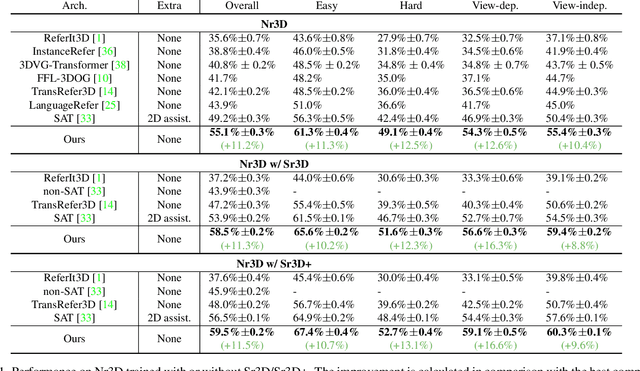
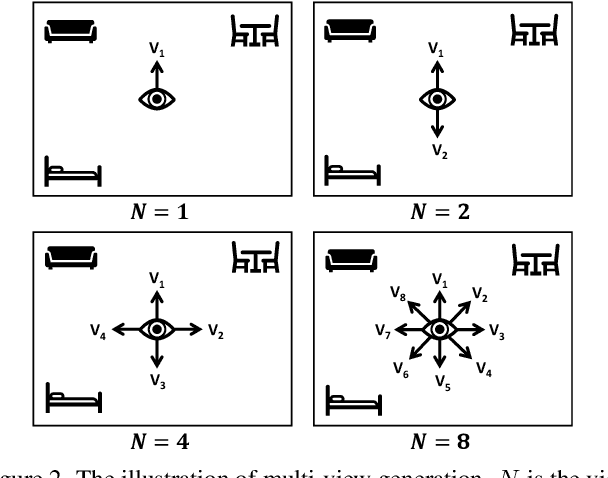
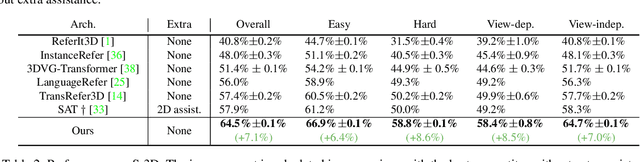
The 3D visual grounding task aims to ground a natural language description to the targeted object in a 3D scene, which is usually represented in 3D point clouds. Previous works studied visual grounding under specific views. The vision-language correspondence learned by this way can easily fail once the view changes. In this paper, we propose a Multi-View Transformer (MVT) for 3D visual grounding. We project the 3D scene to a multi-view space, in which the position information of the 3D scene under different views are modeled simultaneously and aggregated together. The multi-view space enables the network to learn a more robust multi-modal representation for 3D visual grounding and eliminates the dependence on specific views. Extensive experiments show that our approach significantly outperforms all state-of-the-art methods. Specifically, on Nr3D and Sr3D datasets, our method outperforms the best competitor by 11.2% and 7.1% and even surpasses recent work with extra 2D assistance by 5.9% and 6.6%. Our code is available at https://github.com/sega-hsj/MVT-3DVG.
Diverse Text Generation via Variational Encoder-Decoder Models with Gaussian Process Priors
Apr 04, 2022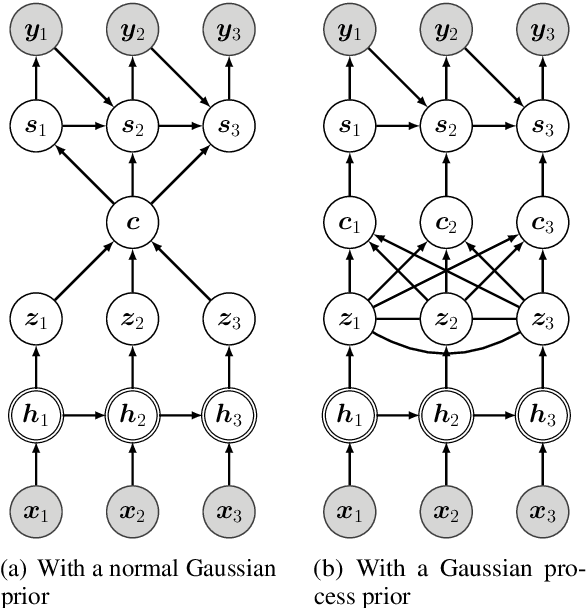

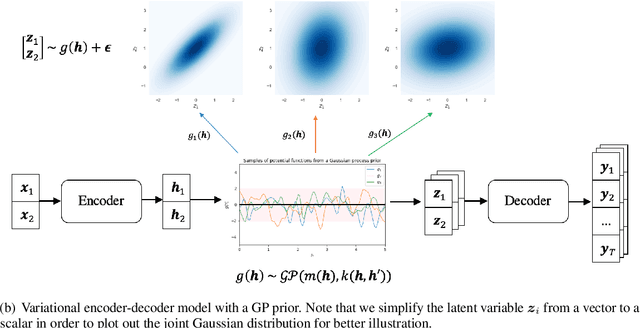
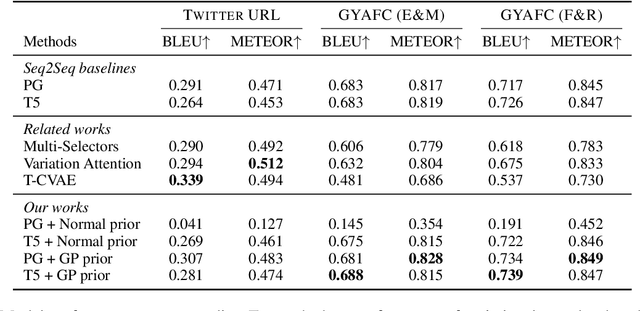
Generating high quality texts with high diversity is important for many NLG applications, but current methods mostly focus on building deterministic models to generate higher quality texts and do not provide many options for promoting diversity. In this work, we present a novel latent structured variable model to generate high quality texts by enriching contextual representation learning of encoder-decoder models. Specifically, we introduce a stochastic function to map deterministic encoder hidden states into random context variables. The proposed stochastic function is sampled from a Gaussian process prior to (1) provide infinite number of joint Gaussian distributions of random context variables (diversity-promoting) and (2) explicitly model dependency between context variables (accurate-encoding). To address the learning challenge of Gaussian processes, we propose an efficient variational inference approach to approximate the posterior distribution of random context variables. We evaluate our method in two typical text generation tasks: paraphrase generation and text style transfer. Experimental results on benchmark datasets demonstrate that our method improves the generation quality and diversity compared with other baselines.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
Stratified Transformer for 3D Point Cloud Segmentation
Mar 28, 2022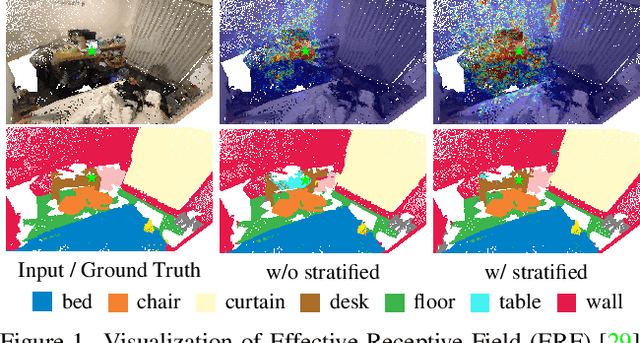
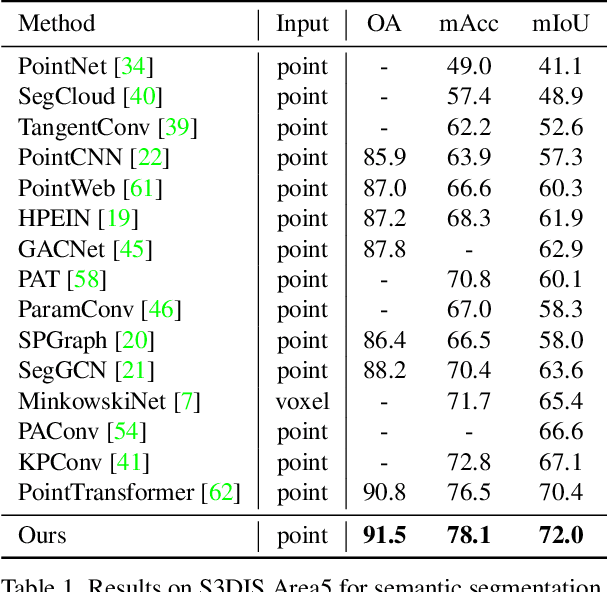
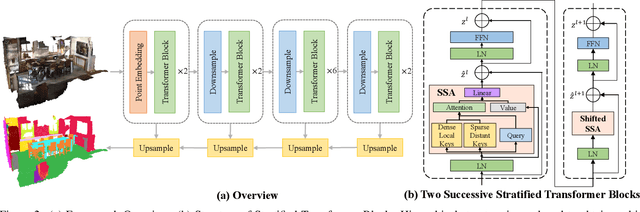
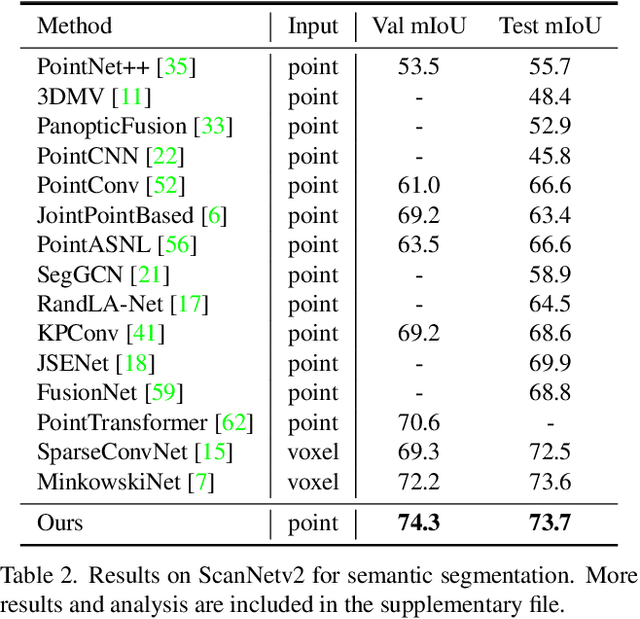
3D point cloud segmentation has made tremendous progress in recent years. Most current methods focus on aggregating local features, but fail to directly model long-range dependencies. In this paper, we propose Stratified Transformer that is able to capture long-range contexts and demonstrates strong generalization ability and high performance. Specifically, we first put forward a novel key sampling strategy. For each query point, we sample nearby points densely and distant points sparsely as its keys in a stratified way, which enables the model to enlarge the effective receptive field and enjoy long-range contexts at a low computational cost. Also, to combat the challenges posed by irregular point arrangements, we propose first-layer point embedding to aggregate local information, which facilitates convergence and boosts performance. Besides, we adopt contextual relative position encoding to adaptively capture position information. Finally, a memory-efficient implementation is introduced to overcome the issue of varying point numbers in each window. Extensive experiments demonstrate the effectiveness and superiority of our method on S3DIS, ScanNetv2 and ShapeNetPart datasets. Code is available at https://github.com/dvlab-research/Stratified-Transformer.
Reconstruction Task Finds Universal Winning Tickets
Feb 23, 2022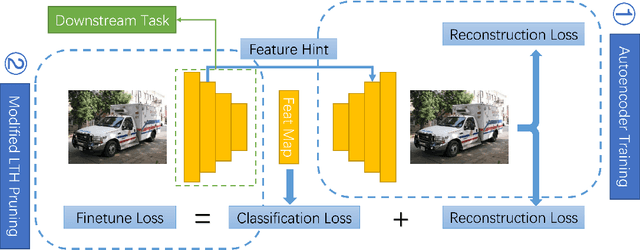
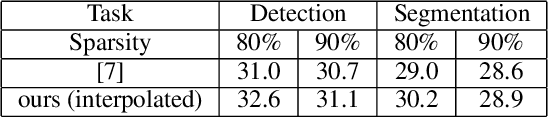
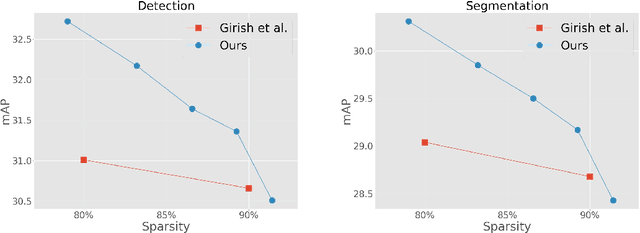
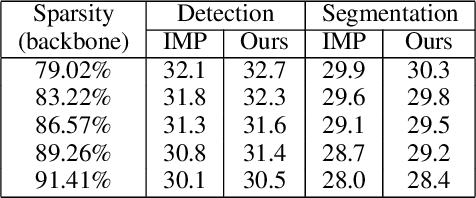
Pruning well-trained neural networks is effective to achieve a promising accuracy-efficiency trade-off in computer vision regimes. However, most of existing pruning algorithms only focus on the classification task defined on the source domain. Different from the strong transferability of the original model, a pruned network is hard to transfer to complicated downstream tasks such as object detection arXiv:arch-ive/2012.04643. In this paper, we show that the image-level pretrain task is not capable of pruning models for diverse downstream tasks. To mitigate this problem, we introduce image reconstruction, a pixel-level task, into the traditional pruning framework. Concretely, an autoencoder is trained based on the original model, and then the pruning process is optimized with both autoencoder and classification losses. The empirical study on benchmark downstream tasks shows that the proposed method can outperform state-of-the-art results explicitly.
T-METASET: Task-Aware Generation of Metamaterial Datasets by Diversity-Based Active Learning
Feb 21, 2022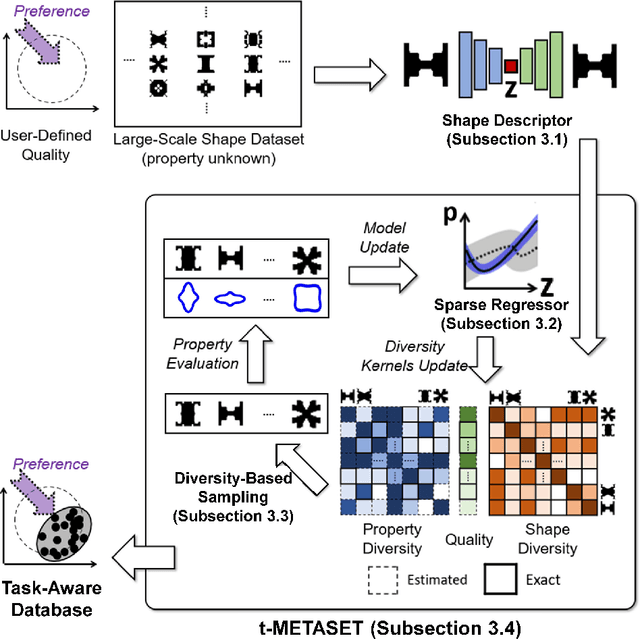

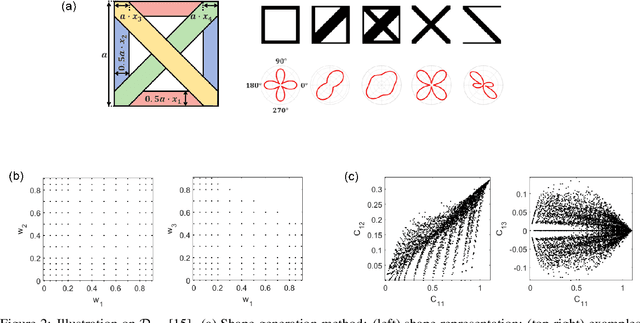
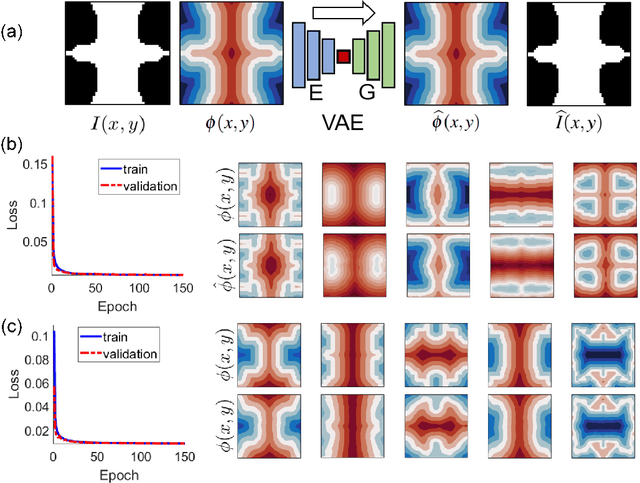
Inspired by the recent success of deep learning in diverse domains, data-driven metamaterials design has emerged as a compelling design paradigm to unlock the potential of multiscale architecture. However, existing model-centric approaches lack principled methodologies dedicated to high-quality data generation. Resorting to space-filling design in shape descriptor space, existing metamaterial datasets suffer from property distributions that are either highly imbalanced or at odds with design tasks of interest. To this end, we propose t-METASET: an intelligent data acquisition framework for task-aware dataset generation. We seek a solution to a commonplace yet frequently overlooked scenario at early design stages: when a massive ($~\sim O(10^4)$) shape library has been prepared with no properties evaluated. The key idea is to exploit a data-driven shape descriptor learned from generative models, fit a sparse regressor as the start-up agent, and leverage diversity-related metrics to drive data acquisition to areas that help designers fulfill design goals. We validate the proposed framework in three hypothetical deployment scenarios, which encompass general use, task-aware use, and tailorable use. Two large-scale shape-only mechanical metamaterial datasets are used as test datasets. The results demonstrate that t-METASET can incrementally grow task-aware datasets. Applicable to general design representations, t-METASET can boost future advancements of not only metamaterials but data-driven design in other domains.
Learning Physics-Informed Neural Networks without Stacked Back-propagation
Feb 18, 2022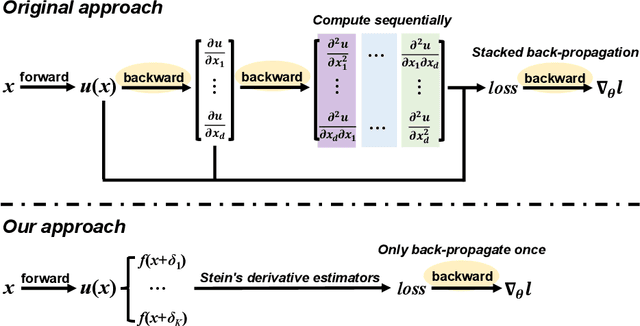
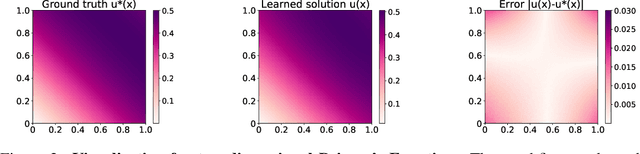
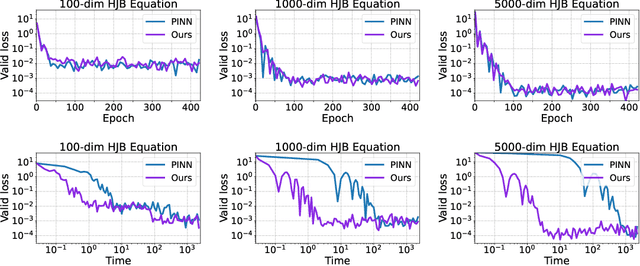
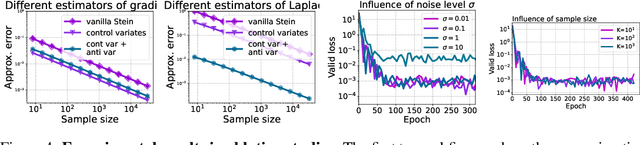
Physics-Informed Neural Network (PINN) has become a commonly used machine learning approach to solve partial differential equations (PDE). But, facing high-dimensional second-order PDE problems, PINN will suffer from severe scalability issues since its loss includes second-order derivatives, the computational cost of which will grow along with the dimension during stacked back-propagation. In this paper, we develop a novel approach that can significantly accelerate the training of Physics-Informed Neural Networks. In particular, we parameterize the PDE solution by the Gaussian smoothed model and show that, derived from Stein's Identity, the second-order derivatives can be efficiently calculated without back-propagation. We further discuss the model capacity and provide variance reduction methods to address key limitations in the derivative estimation. Experimental results show that our proposed method can achieve competitive error compared to standard PINN training but is two orders of magnitude faster.
Pessimistic Minimax Value Iteration: Provably Efficient Equilibrium Learning from Offline Datasets
Feb 15, 2022
We study episodic two-player zero-sum Markov games (MGs) in the offline setting, where the goal is to find an approximate Nash equilibrium (NE) policy pair based on a dataset collected a priori. When the dataset does not have uniform coverage over all policy pairs, finding an approximate NE involves challenges in three aspects: (i) distributional shift between the behavior policy and the optimal policy, (ii) function approximation to handle large state space, and (iii) minimax optimization for equilibrium solving. We propose a pessimism-based algorithm, dubbed as pessimistic minimax value iteration (PMVI), which overcomes the distributional shift by constructing pessimistic estimates of the value functions for both players and outputs a policy pair by solving NEs based on the two value functions. Furthermore, we establish a data-dependent upper bound on the suboptimality which recovers a sublinear rate without the assumption on uniform coverage of the dataset. We also prove an information-theoretical lower bound, which suggests that the data-dependent term in the upper bound is intrinsic. Our theoretical results also highlight a notion of "relative uncertainty", which characterizes the necessary and sufficient condition for achieving sample efficiency in offline MGs. To the best of our knowledge, we provide the first nearly minimax optimal result for offline MGs with function approximation.