 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegionCLIP: Region-based Language-Image Pretraining
Dec 16, 2021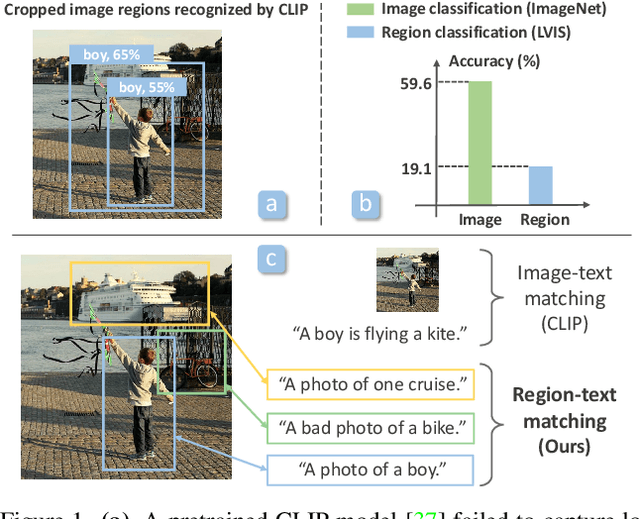
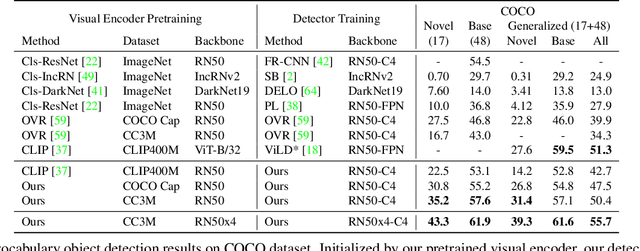
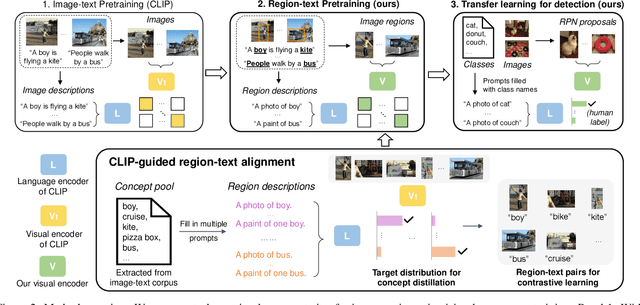
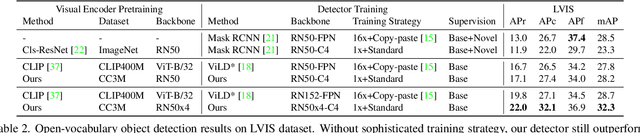
Contrastive language-image pretraining (CLIP) using image-text pairs has achieved impressive results on image classification in both zero-shot and transfer learning settings. However, we show that directly applying such models to recognize image regions for object detection leads to poor performance due to a domain shift: CLIP was trained to match an image as a whole to a text description, without capturing the fine-grained alignment between image regions and text spans. To mitigate this issue, we propose a new method called RegionCLIP that significantly extends CLIP to learn region-level visual representations, thus enabling fine-grained alignment between image regions and textual concepts. Our method leverages a CLIP model to match image regions with template captions and then pretrains our model to align these region-text pairs in the feature space. When transferring our pretrained model to the open-vocabulary object detection tasks, our method significantly outperforms the state of the art by 3.8 AP50 and 2.2 AP for novel categories on COCO and LVIS datasets, respectively. Moreoever, the learned region representations support zero-shot inference for object detection, showing promising results on both COCO and LVIS datasets. Our code is available at https://github.com/microsoft/RegionCLIP.
SGEITL: Scene Graph Enhanced Image-Text Learning for Visual Commonsense Reasoning
Dec 16, 2021

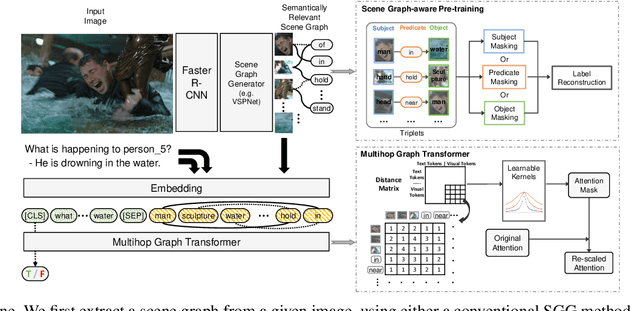

Answering complex questions about images is an ambitious goal for machine intelligence, which requires a joint understanding of images, text, and commonsense knowledge, as well as a strong reasoning ability. Recently, multimodal Transformers have made great progress in the task of Visual Commonsense Reasoning (VCR), by jointly understanding visual objects and text tokens through layers of cross-modality attention. However, these approaches do not utilize the rich structure of the scene and the interactions between objects which are essential in answering complex commonsense questions. We propose a Scene Graph Enhanced Image-Text Learning (SGEITL) framework to incorporate visual scene graphs in commonsense reasoning. To exploit the scene graph structure, at the model structure level, we propose a multihop graph transformer for regularizing attention interaction among hops. As for pre-training, a scene-graph-aware pre-training method is proposed to leverage structure knowledge extracted in the visual scene graph. Moreover, we introduce a method to train and generate domain-relevant visual scene graphs using textual annotations in a weakly-supervised manner. Extensive experiments on VCR and other tasks show a significant performance boost compared with the state-of-the-art methods and prove the efficacy of each proposed component.
* AAAI 2022
Grounded Language-Image Pre-training
Dec 07, 2021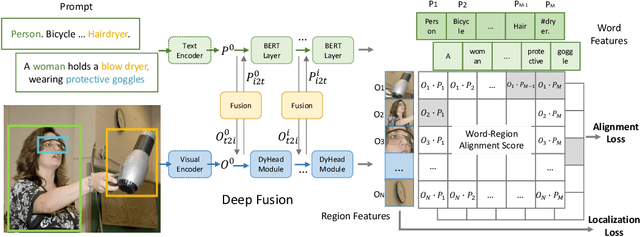
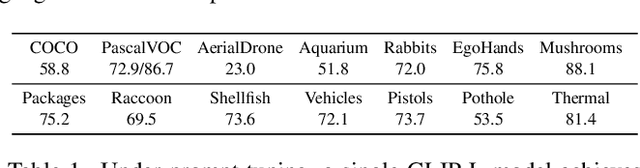
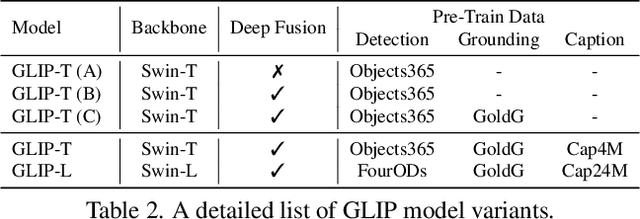
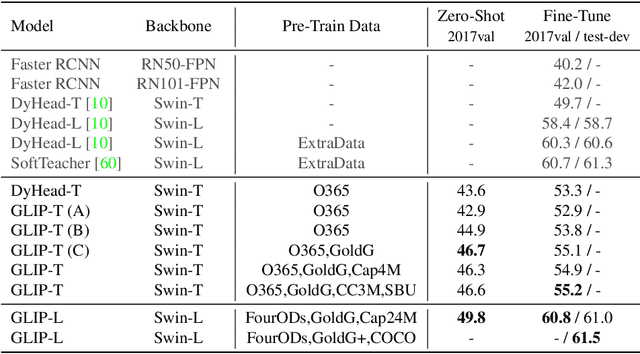
This paper presents a grounded language-image pre-training (GLIP) model for learning object-level, language-aware, and semantic-rich visual representations. GLIP unifies object detection and phrase grounding for pre-training. The unification brings two benefits: 1) it allows GLIP to learn from both detection and grounding data to improve both tasks and bootstrap a good grounding model; 2) GLIP can leverage massive image-text pairs by generating grounding boxes in a self-training fashion, making the learned representation semantic-rich. In our experiments, we pre-train GLIP on 27M grounding data, including 3M human-annotated and 24M web-crawled image-text pairs. The learned representations demonstrate strong zero-shot and few-shot transferability to various object-level recognition tasks. 1) When directly evaluated on COCO and LVIS (without seeing any images in COCO during pre-training), GLIP achieves 49.8 AP and 26.9 AP, respectively, surpassing many supervised baselines. 2) After fine-tuned on COCO, GLIP achieves 60.8 AP on val and 61.5 AP on test-dev, surpassing prior SoTA. 3) When transferred to 13 downstream object detection tasks, a 1-shot GLIP rivals with a fully-supervised Dynamic Head. Code will be released at https://github.com/microsoft/GLIP.
Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning
Sep 14, 2021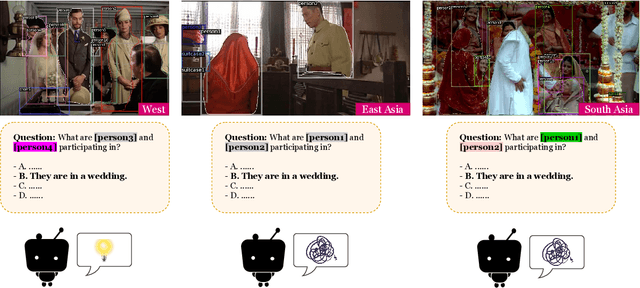

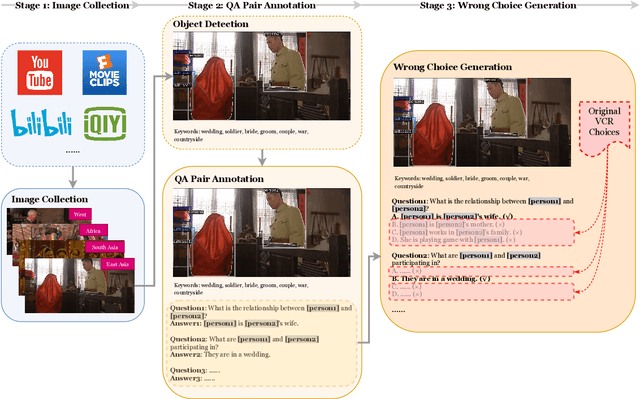
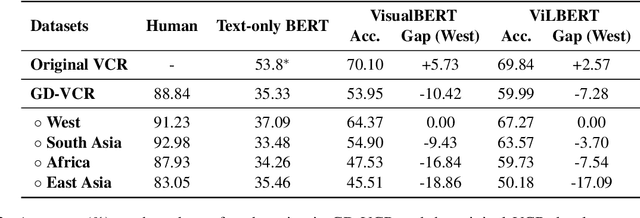
Commonsense is defined as the knowledge that is shared by everyone. However, certain types of commonsense knowledge are correlated with culture and geographic locations and they are only shared locally. For example, the scenarios of wedding ceremonies vary across regions due to different customs influenced by historical and religious factors. Such regional characteristics, however, are generally omitted in prior work. In this paper, we construct a Geo-Diverse Visual Commonsense Reasoning dataset (GD-VCR) to test vision-and-language models' ability to understand cultural and geo-location-specific commonsense. In particular, we study two state-of-the-art Vision-and-Language models, VisualBERT and ViLBERT trained on VCR, a standard multimodal commonsense benchmark with images primarily from Western regions. We then evaluate how well the trained models can generalize to answering the questions in GD-VCR. We find that the performance of both models for non-Western regions including East Asia, South Asia, and Africa is significantly lower than that for Western region. We analyze the reasons behind the performance disparity and find that the performance gap is larger on QA pairs that: 1) are concerned with culture-related scenarios, e.g., weddings, religious activities, and festivals; 2) require high-level geo-diverse commonsense reasoning rather than low-order perception and recognition. Dataset and code are released at https://github.com/WadeYin9712/GD-VCR.
BERTHop: An Effective Vision-and-Language Model for Chest X-ray Disease Diagnosis
Aug 10, 2021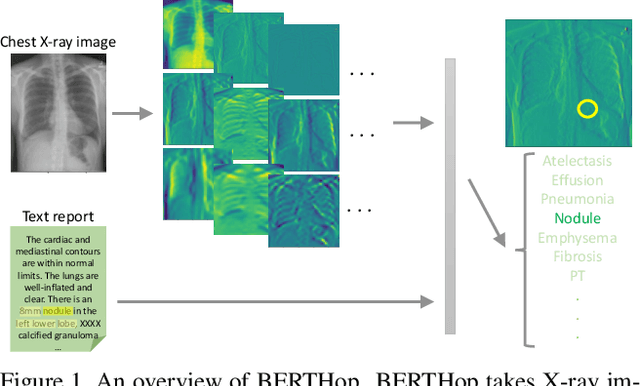
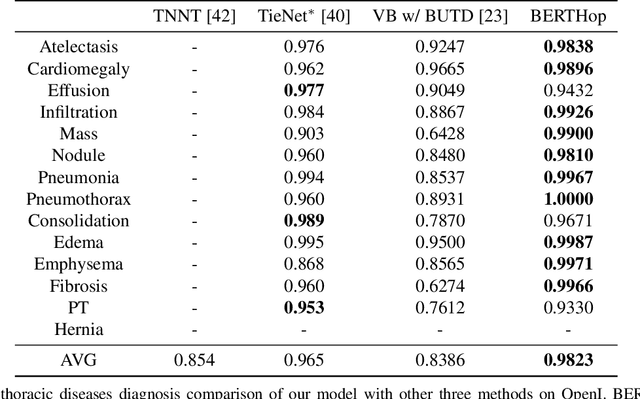
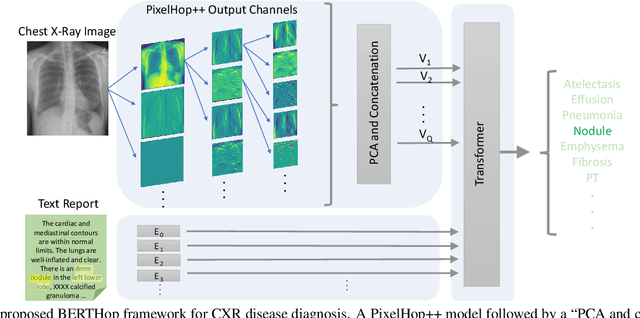
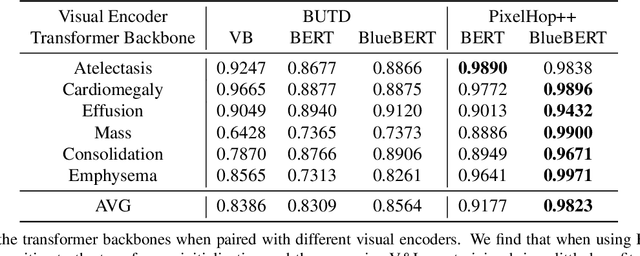
Vision-and-language(V&L) models take image and text as input and learn to capture the associations between them. Prior studies show that pre-trained V&L models can significantly improve the model performance for downstream tasks such as Visual Question Answering (VQA). However, V&L models are less effective when applied in the medical domain (e.g., on X-ray images and clinical notes) due to the domain gap. In this paper, we investigate the challenges of applying pre-trained V&L models in medical applications. In particular, we identify that the visual representation in general V&L models is not suitable for processing medical data. To overcome this limitation, we propose BERTHop, a transformer-based model based on PixelHop++ and VisualBERT, for better capturing the associations between the two modalities. Experiments on the OpenI dataset, a commonly used thoracic disease diagnosis benchmark, show that BERTHop achieves an average Area Under the Curve (AUC) of 98.12% which is 1.62% higher than state-of-the-art (SOTA) while it is trained on a 9 times smaller dataset.
How Much Can CLIP Benefit Vision-and-Language Tasks?
Jul 13, 2021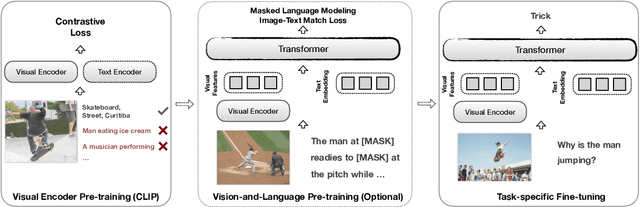
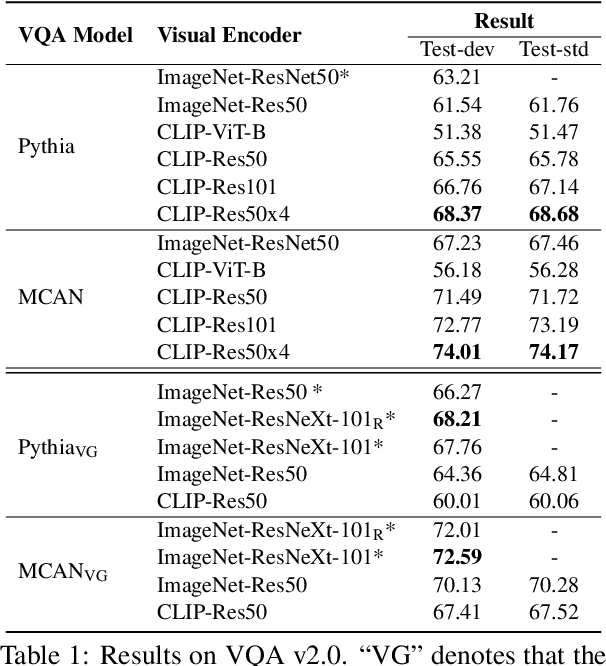
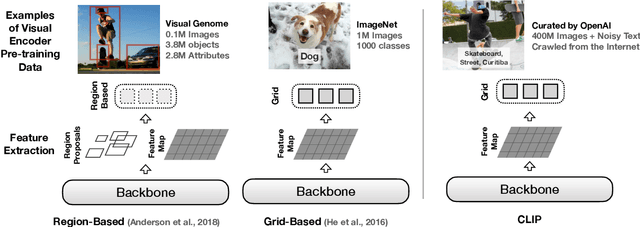
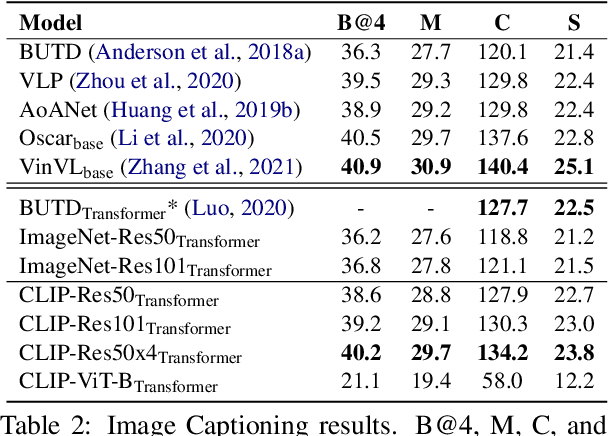
Most existing Vision-and-Language (V&L) models rely on pre-trained visual encoders, using a relatively small set of manually-annotated data (as compared to web-crawled data), to perceive the visual world. However, it has been observed that large-scale pretraining usually can result in better generalization performance, e.g., CLIP (Contrastive Language-Image Pre-training), trained on a massive amount of image-caption pairs, has shown a strong zero-shot capability on various vision tasks. To further study the advantage brought by CLIP, we propose to use CLIP as the visual encoder in various V&L models in two typical scenarios: 1) plugging CLIP into task-specific fine-tuning; 2) combining CLIP with V&L pre-training and transferring to downstream tasks. We show that CLIP significantly outperforms widely-used visual encoders trained with in-domain annotated data, such as BottomUp-TopDown. We achieve competitive or better results on diverse V&L tasks, while establishing new state-of-the-art results on Visual Question Answering, Visual Entailment, and V&L Navigation tasks. We release our code at https://github.com/clip-vil/CLIP-ViL.
Weakly-supervised VisualBERT: Pre-training without Parallel Images and Captions
Oct 24, 2020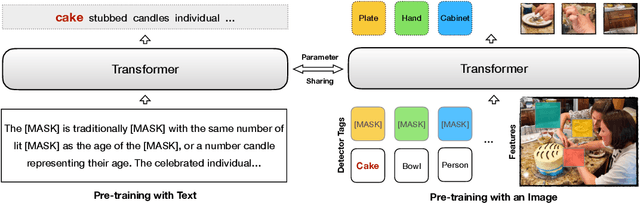
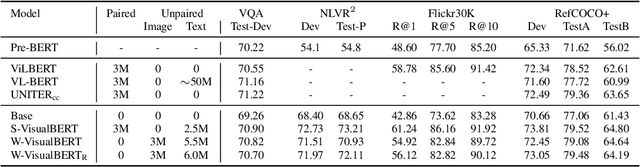

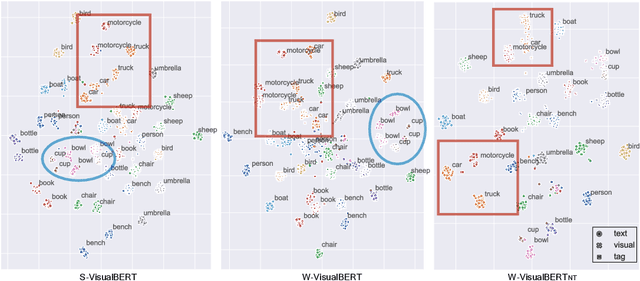
Pre-trained contextual vision-and-language (V&L) models have brought impressive performance improvement on various benchmarks. However, the paired text-image data required for pre-training are hard to collect and scale up. We investigate if a strong V&L representation model can be learned without text-image pairs. We propose Weakly-supervised VisualBERT with the key idea of conducting "mask-and-predict" pre-training on language-only and image-only corpora. Additionally, we introduce the object tags detected by an object recognition model as anchor points to bridge two modalities. Evaluation on four V&L benchmarks shows that Weakly-supervised VisualBERT achieves similar performance with a model pre-trained with paired data. Besides, pre-training on more image-only data further improves a model that already has access to aligned data, suggesting the possibility of utilizing billions of raw images available to enhance V&L models.
VisualBERT: A Simple and Performant Baseline for Vision and Language
Aug 09, 2019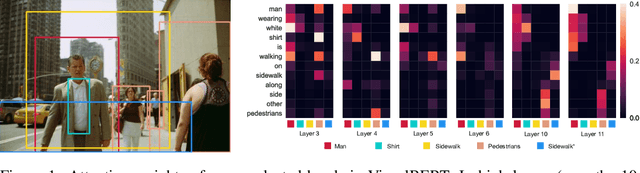
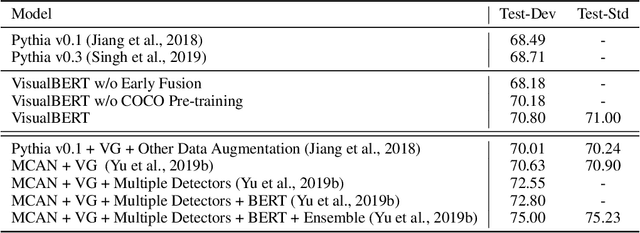
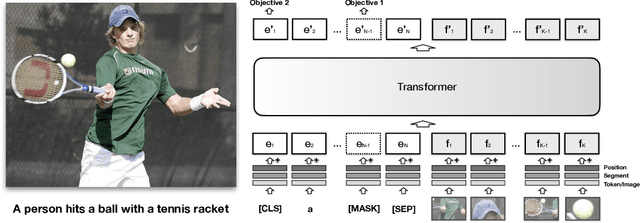
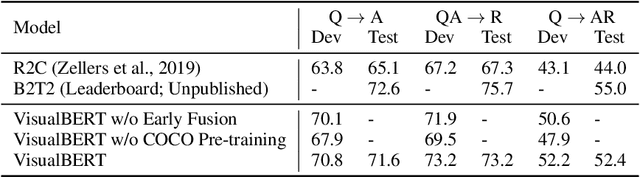
We propose VisualBERT, a simple and flexible framework for modeling a broad range of vision-and-language tasks. VisualBERT consists of a stack of Transformer layers that implicitly align elements of an input text and regions in an associated input image with self-attention. We further propose two visually-grounded language model objectives for pre-training VisualBERT on image caption data. Experiments on four vision-and-language tasks including VQA, VCR, NLVR2, and Flickr30K show that VisualBERT outperforms or rivals with state-of-the-art models while being significantly simpler. Further analysis demonstrates that VisualBERT can ground elements of language to image regions without any explicit supervision and is even sensitive to syntactic relationships, tracking, for example, associations between verbs and image regions corresponding to their arguments.
Efficient Contextual Representation Learning Without Softmax Layer
Feb 28, 2019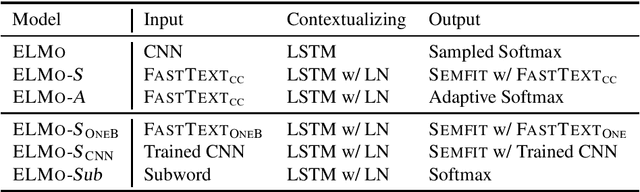



Contextual representation models have achieved great success in improving various downstream tasks. However, these language-model-based encoders are difficult to train due to the large parameter sizes and high computational complexity. By carefully examining the training procedure, we find that the softmax layer (the output layer) causes significant inefficiency due to the large vocabulary size. Therefore, we redesign the learning objective and propose an efficient framework for training contextual representation models. Specifically, the proposed approach bypasses the softmax layer by performing language modeling with dimension reduction, and allows the models to leverage pre-trained word embeddings. Our framework reduces the time spent on the output layer to a negligible level, eliminates almost all the trainable parameters of the softmax layer and performs language modeling without truncating the vocabulary. When applied to ELMo, our method achieves a 4 times speedup and eliminates 80% trainable parameters while achieving competitive performance on downstream tasks.