 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Improved Proxy-based Deep Metric Learning via Data-Augmented Domain Adaptation
Jan 01, 2024



Deep Metric Learning (DML) plays an important role in modern computer vision research, where we learn a distance metric for a set of image representations. Recent DML techniques utilize the proxy to interact with the corresponding image samples in the embedding space. However, existing proxy-based DML methods focus on learning individual proxy-to-sample distance while the overall distribution of samples and proxies lacks attention. In this paper, we present a novel proxy-based DML framework that focuses on aligning the sample and proxy distributions to improve the efficiency of proxy-based DML losses. Specifically, we propose the Data-Augmented Domain Adaptation (DADA) method to adapt the domain gap between the group of samples and proxies. To the best of our knowledge, we are the first to leverage domain adaptation to boost the performance of proxy-based DML. We show that our method can be easily plugged into existing proxy-based DML losses. Our experiments on benchmarks, including the popular CUB-200-2011, CARS196, Stanford Online Products, and In-Shop Clothes Retrieval, show that our learning algorithm significantly improves the existing proxy losses and achieves superior results compared to the existing methods.
SE-LIO: Semantics-enhanced Solid-State-LiDAR-Inertial Odometry for Tree-rich Environments
Dec 04, 2023



In this letter, we propose a semantics-enhanced solid-state-LiDAR-inertial odometry (SE-LIO) in tree-rich environments. Multiple LiDAR frames are first merged and compensated with the inertial navigation system (INS) to increase the point-cloud coverage, thus improving the accuracy of semantic segmentation. The unstructured point clouds, such as tree leaves and dynamic objects, are then removed with the semantic information. Furthermore, the pole-like point clouds, primarily tree trunks, are modeled as cylinders to improve positioning accuracy. An adaptive piecewise cylinder-fitting method is proposed to accommodate environments with a high prevalence of curved tree trunks. Finally, the iterated error-state Kalman filter (IESKF) is employed for state estimation. Point-to-cylinder and point-to-plane constraints are tightly coupled with the prior constraints provided by the INS to obtain the maximum a posteriori estimation. Targeted experiments are conducted in complex campus and park environments to evaluate the performance of SE-LIO. The proposed methods, including removing the unstructured point clouds and the adaptive cylinder fitting, yield improved accuracy. Specifically, the positioning accuracy of the proposed SE-LIO is improved by 43.1% compared to the plane-based LIO.
Multi-modal Domain Adaptation for REG via Relation Transfer
Sep 23, 2023Domain adaptation, which aims to transfer knowledge between domains, has been well studied in many areas such as image classification and object detection. However, for multi-modal tasks, conventional approaches rely on large-scale pre-training. But due to the difficulty of acquiring multi-modal data, large-scale pre-training is often impractical. Therefore, domain adaptation, which can efficiently utilize the knowledge from different datasets (domains), is crucial for multi-modal tasks. In this paper, we focus on the Referring Expression Grounding (REG) task, which is to localize an image region described by a natural language expression. Specifically, we propose a novel approach to effectively transfer multi-modal knowledge through a specially relation-tailored approach for the REG problem. Our approach tackles the multi-modal domain adaptation problem by simultaneously enriching inter-domain relations and transferring relations between domains. Experiments show that our proposed approach significantly improves the transferability of multi-modal domains and enhances adaptation performance in the REG problem.
FF-LINS: A Consistent Frame-to-Frame Solid-State-LiDAR-Inertial State Estimator
Jul 13, 2023



Most of the existing LiDAR-inertial navigation systems are based on frame-to-map registrations, leading to inconsistency in state estimation. The newest solid-state LiDAR with a non-repetitive scanning pattern makes it possible to achieve a consistent LiDAR-inertial estimator by employing a frame-to-frame data association. In this letter, we propose a robust and consistent frame-to-frame LiDAR-inertial navigation system (FF-LINS) for solid-state LiDARs. With the INS-centric LiDAR frame processing, the keyframe point-cloud map is built using the accumulated point clouds to construct the frame-to-frame data association. The LiDAR frame-to-frame and the inertial measurement unit (IMU) preintegration measurements are tightly integrated using the factor graph optimization, with online calibration of the LiDAR-IMU extrinsic and time-delay parameters. The experiments on the public and private datasets demonstrate that the proposed FF-LINS achieves superior accuracy and robustness than the state-of-the-art systems. Besides, the LiDAR-IMU extrinsic and time-delay parameters are estimated effectively, and the online calibration notably improves the pose accuracy. The proposed FF-LINS and the employed datasets are open-sourced on GitHub (https://github.com/i2Nav-WHU/FF-LINS).
PO-VINS: An Efficient Pose-Only LiDAR-Enhanced Visual-Inertial State Estimator
May 22, 2023



The pose-only (PO) visual representation has been proven to be equivalent to the classical multiple-view geometry, while significantly improving computational efficiency. However, its applicability for real-world navigation in large-scale complex environments has not yet been demonstrated. In this study, we present an efficient pose-only LiDAR-enhanced visual-inertial navigation system (PO-VINS) to enhance the real-time performance of the state estimator. In the visual-inertial state estimator (VISE), we propose a pose-only visual-reprojection measurement model that only contains the inertial measurement unit (IMU) pose and extrinsic-parameter states. We further integrated the LiDAR-enhanced method to construct a pose-only LiDAR-depth measurement model. Real-world experiments were conducted in large-scale complex environments, demonstrating that the proposed PO-VISE and LiDAR-enhanced PO-VISE reduce computational complexity by more than 50% and over 20%, respectively. Additionally, the PO-VINS yields the same accuracy as conventional methods. These results indicate that the pose-only solution is efficient and applicable for real-time visual-inertial state estimation.
On Calibrating Semantic Segmentation Models: Analysis and An Algorithm
Dec 22, 2022



We study the problem of semantic segmentation calibration. For image classification, lots of existing solutions are proposed to alleviate model miscalibration of confidence. However, to date, confidence calibration research on semantic segmentation is still limited. We provide a systematic study on the calibration of semantic segmentation models and propose a simple yet effective approach. First, we find that model capacity, crop size, multi-scale testing, and prediction correctness have impact on calibration. Among them, prediction correctness, especially misprediction, is more important to miscalibration due to over-confidence. Next, we propose a simple, unifying, and effective approach, namely selective scaling, by separating correct/incorrect prediction for scaling and more focusing on misprediction logit smoothing. Then, we study popular existing calibration methods and compare them with selective scaling on semantic segmentation calibration. We conduct extensive experiments with a variety of benchmarks on both in-domain and domain-shift calibration, and show that selective scaling consistently outperforms other methods.
CTIN: Robust Contextual Transformer Network for Inertial Navigation
Dec 20, 2021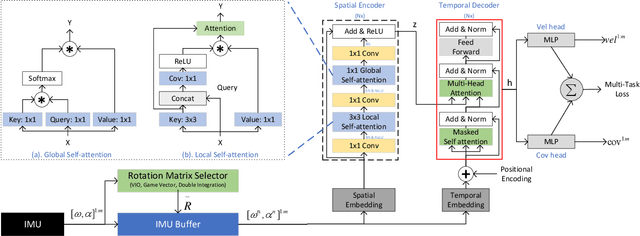

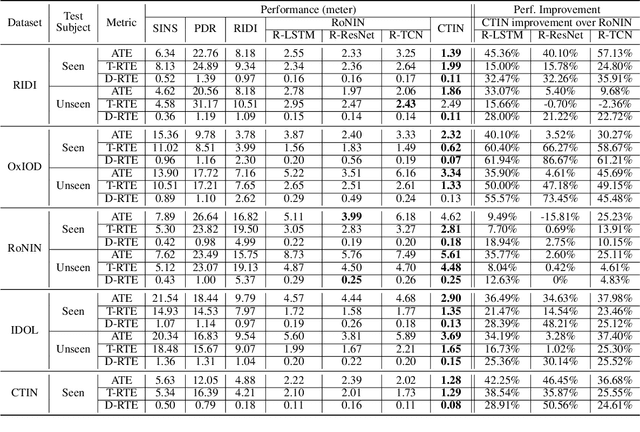
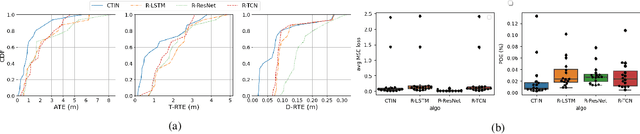
Recently, data-driven inertial navigation approaches have demonstrated their capability of using well-trained neural networks to obtain accurate position estimates from inertial measurement units (IMU) measurements. In this paper, we propose a novel robust Contextual Transformer-based network for Inertial Navigation~(CTIN) to accurately predict velocity and trajectory. To this end, we first design a ResNet-based encoder enhanced by local and global multi-head self-attention to capture spatial contextual information from IMU measurements. Then we fuse these spatial representations with temporal knowledge by leveraging multi-head attention in the Transformer decoder. Finally, multi-task learning with uncertainty reduction is leveraged to improve learning efficiency and prediction accuracy of velocity and trajectory. Through extensive experiments over a wide range of inertial datasets~(e.g. RIDI, OxIOD, RoNIN, IDOL, and our own), CTIN is very robust and outperforms state-of-the-art models.
Rapid Assessments of Light-Duty Gasoline Vehicle Emissions Using On-Road Remote Sensing and Machine Learning
Oct 01, 2021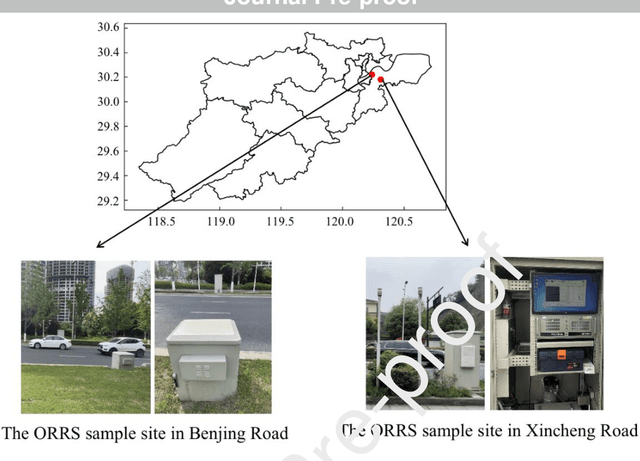
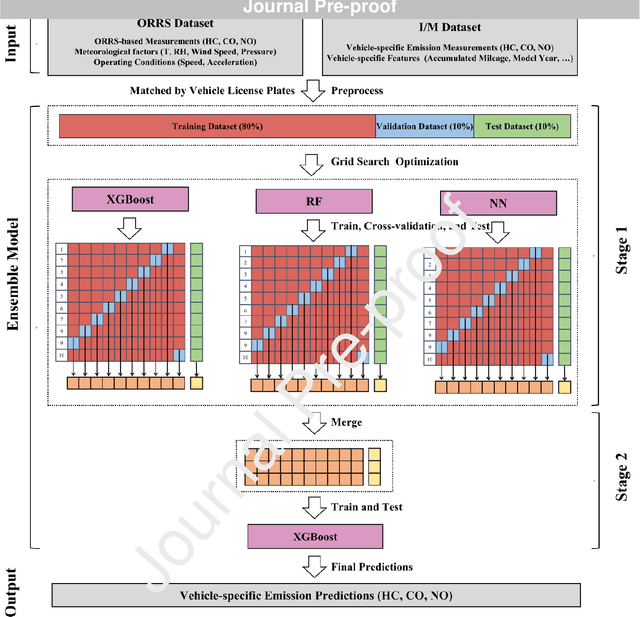
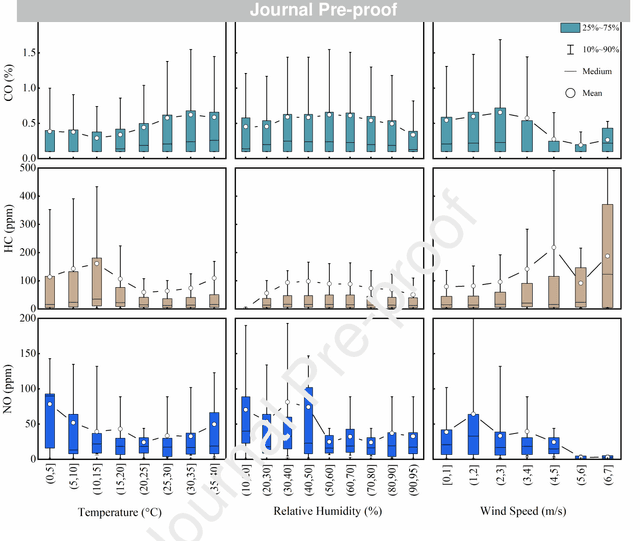
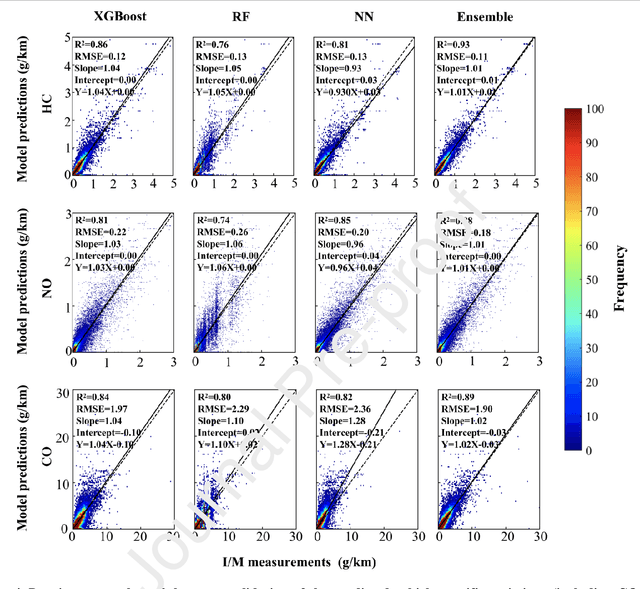
In-time and accurate assessments of on-road vehicle emissions play a central role in urban air quality and health policymaking. However, official insight is hampered by the Inspection/Maintenance (I/M) procedure conducted in the laboratory annually. It not only has a large gap to real-world situations (e.g., meteorological conditions) but also is incapable of regular supervision. Here we build a unique dataset including 103831 light-duty gasoline vehicles, in which on-road remote sensing (ORRS) measurements are linked to the I/M records based on the vehicle identification numbers and license plates. On this basis, we develop an ensemble model framework that integrates three machining learning algorithms, including neural network (NN), extreme gradient boosting (XGBoost), and random forest (RF). We demonstrate that this ensemble model could rapidly assess the vehicle-specific emissions (i.e., CO, HC, and NO). In particular, the model performs quite well for the passing vehicles under normal conditions (i.e., lower VSP (< 18 kw/t), temperature (6 ~ 32 {\deg}C), relative humidity (< 80%), and wind speed (< 5m/s)). Together with the current emission standard, we identify a large number of the dirty (2.33%) or clean (74.92%) vehicles in the real world. Our results show that the ORRS measurements, assisted by the machine-learning-based ensemble model developed here, can realize day-to-day supervision of on-road vehicle-specific emissions. This approach framework provides a valuable opportunity to reform the I/M procedures globally and mitigate urban air pollution deeply.
Anti-Neuron Watermarking: Protecting Personal Data Against Unauthorized Neural Model Training
Sep 18, 2021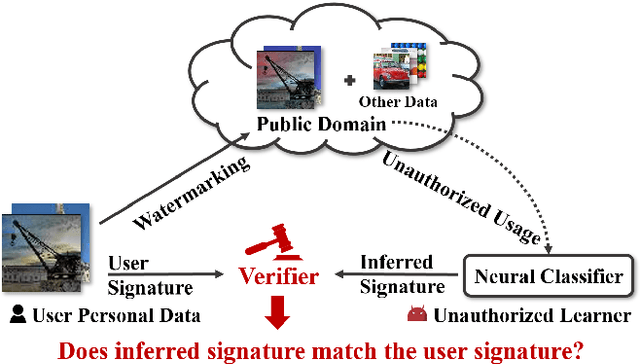
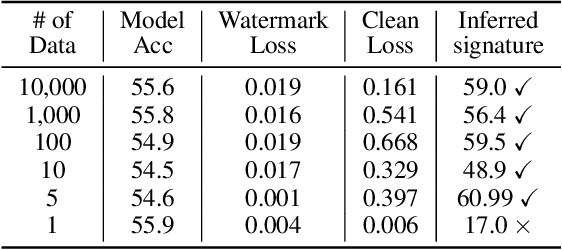
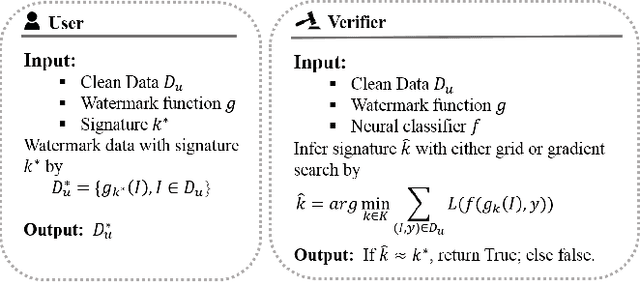
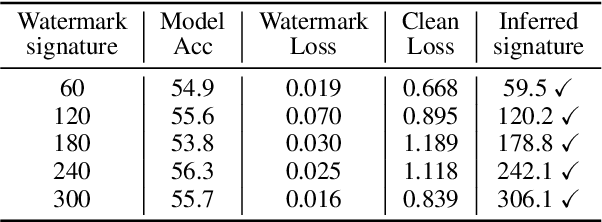
In this paper, we raise up an emerging personal data protection problem where user personal data (e.g. images) could be inappropriately exploited to train deep neural network models without authorization. To solve this problem, we revisit traditional watermarking in advanced machine learning settings. By embedding a watermarking signature using specialized linear color transformation to user images, neural models will be imprinted with such a signature if training data include watermarked images. Then, a third-party verifier can verify potential unauthorized usage by inferring the watermark signature from neural models. We further explore the desired properties of watermarking and signature space for convincing verification. Through extensive experiments, we show empirically that linear color transformation is effective in protecting user's personal images for various realistic settings. To the best of our knowledge, this is the first work to protect users' personal data from unauthorized usage in neural network training.
Deep Epidemiological Modeling by Black-box Knowledge Distillation: An Accurate Deep Learning Model for COVID-19
Jan 20, 2021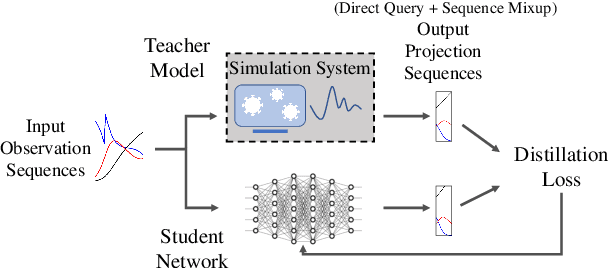
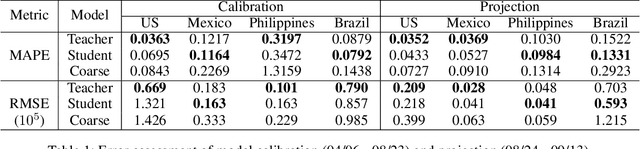
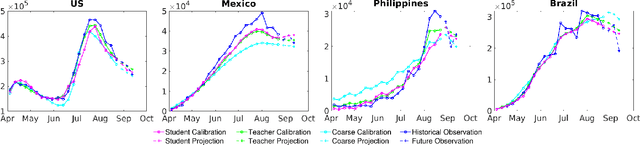

An accurate and efficient forecasting system is imperative to the prevention of emerging infectious diseases such as COVID-19 in public health. This system requires accurate transient modeling, lower computation cost, and fewer observation data. To tackle these three challenges, we propose a novel deep learning approach using black-box knowledge distillation for both accurate and efficient transmission dynamics prediction in a practical manner. First, we leverage mixture models to develop an accurate, comprehensive, yet impractical simulation system. Next, we use simulated observation sequences to query the simulation system to retrieve simulated projection sequences as knowledge. Then, with the obtained query data, sequence mixup is proposed to improve query efficiency, increase knowledge diversity, and boost distillation model accuracy. Finally, we train a student deep neural network with the retrieved and mixed observation-projection sequences for practical use. The case study on COVID-19 justifies that our approach accurately projects infections with much lower computation cost when observation data are limited.