 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPE: Task-Agnostic Prior Embedding for Image Restoration
Mar 11, 2022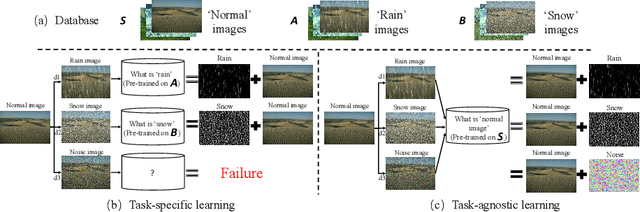

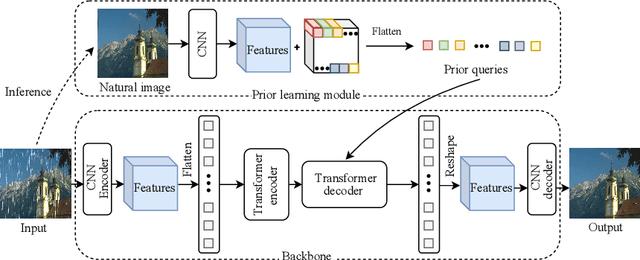

Learning an generalized prior for natural image restoration is an important yet challenging task. Early methods mostly involved handcrafted priors including normalized sparsity, L0 gradients, dark channel priors, etc. Recently, deep neural networks have been used to learn various image priors but do not guarantee to generalize. In this paper, we propose a novel approach that embeds a task-agnostic prior into a transformer. Our approach, named Task-Agnostic Prior Embedding (TAPE), consists of three stages, namely, task-agnostic pre-training, task-agnostic fine-tuning, and task-specific fine-tuning, where the first one embeds prior knowledge about natural images into the transformer and the latter two extracts the knowledge to assist downstream image restoration. Experiments on various types of degradation validate the effectiveness of TAPE. The image restoration performance in terms of PSNR is improved by as much as 1.45 dB and even outperforms task-specific algorithms. More importantly, TAPE shows the ability of disentangling generalized image priors from degraded images, which enjoys favorable transfer ability to unknown downstream tasks.
MVP: Multimodality-guided Visual Pre-training
Mar 10, 2022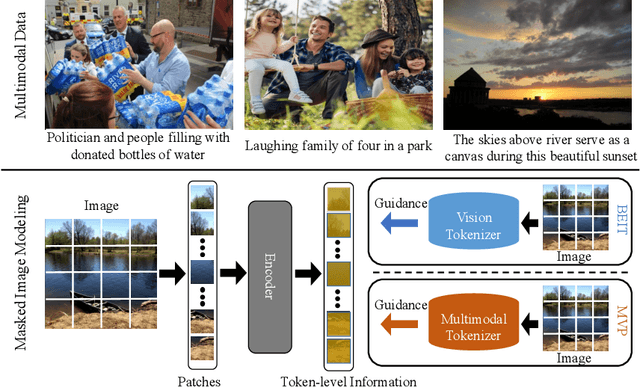
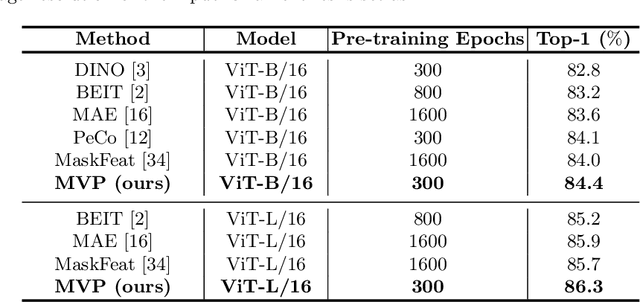
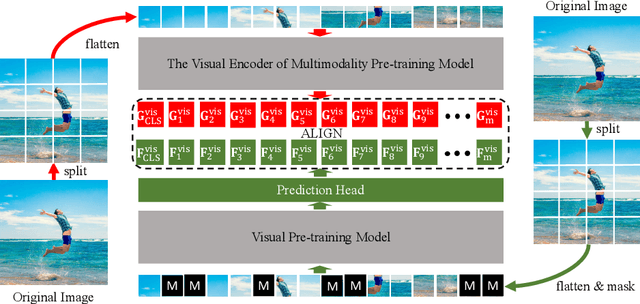
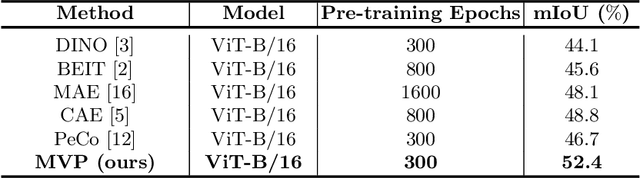
Recently, masked image modeling (MIM) has become a promising direction for visual pre-training. In the context of vision transformers, MIM learns effective visual representation by aligning the token-level features with a pre-defined space (e.g., BEIT used a d-VAE trained on a large image corpus as the tokenizer). In this paper, we go one step further by introducing guidance from other modalities and validating that such additional knowledge leads to impressive gains for visual pre-training. The proposed approach is named Multimodality-guided Visual Pre-training (MVP), in which we replace the tokenizer with the vision branch of CLIP, a vision-language model pre-trained on 400 million image-text pairs. We demonstrate the effectiveness of MVP by performing standard experiments, i.e., pre-training the ViT models on ImageNet and fine-tuning them on a series of downstream visual recognition tasks. In particular, pre-training ViT-Base/16 for 300 epochs, MVP reports a 52.4% mIoU on ADE20K, surpassing BEIT (the baseline and previous state-of-the-art) with an impressive margin of 6.8%.
Exploring Complicated Search Spaces with Interleaving-Free Sampling
Dec 05, 2021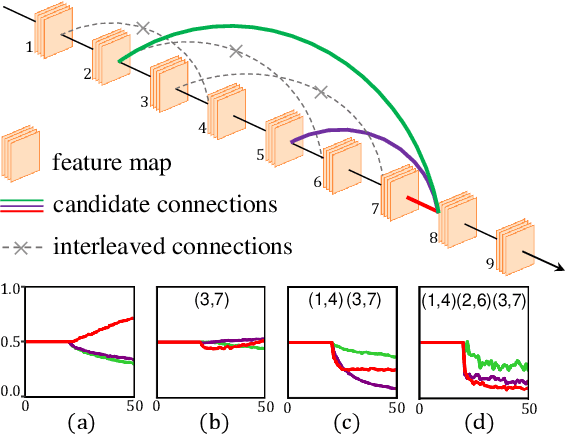


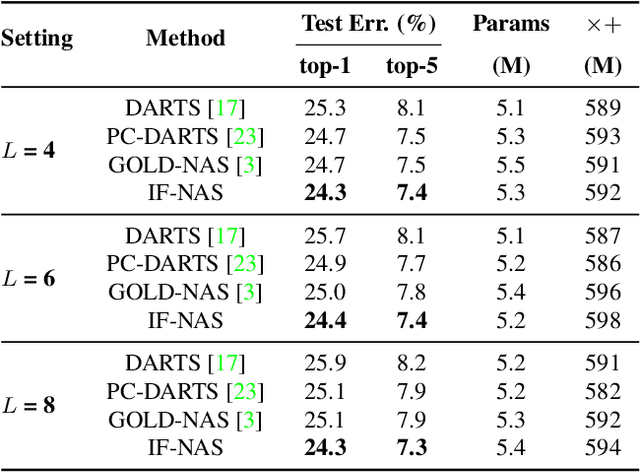
The existing neural architecture search algorithms are mostly working on search spaces with short-distance connections. We argue that such designs, though safe and stable, obstacles the search algorithms from exploring more complicated scenarios. In this paper, we build the search algorithm upon a complicated search space with long-distance connections, and show that existing weight-sharing search algorithms mostly fail due to the existence of \textbf{interleaved connections}. Based on the observation, we present a simple yet effective algorithm named \textbf{IF-NAS}, where we perform a periodic sampling strategy to construct different sub-networks during the search procedure, avoiding the interleaved connections to emerge in any of them. In the proposed search space, IF-NAS outperform both random sampling and previous weight-sharing search algorithms by a significant margin. IF-NAS also generalizes to the micro cell-based spaces which are much easier. Our research emphasizes the importance of macro structure and we look forward to further efforts along this direction.
NeuSample: Neural Sample Field for Efficient View Synthesis
Nov 30, 2021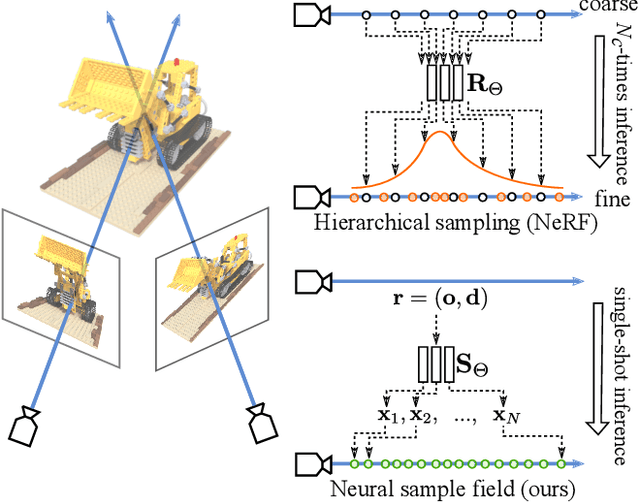
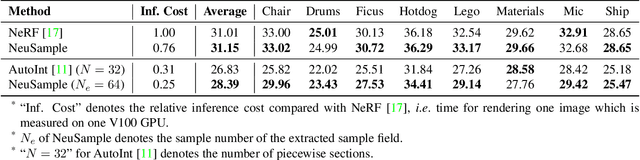
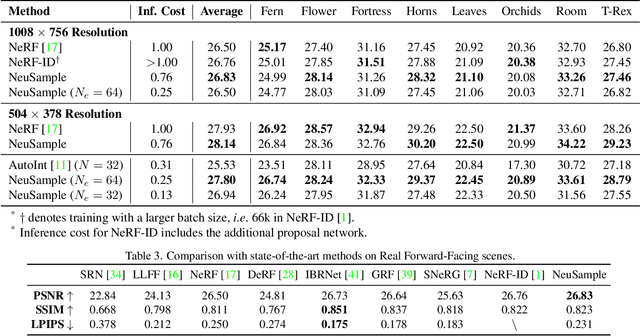
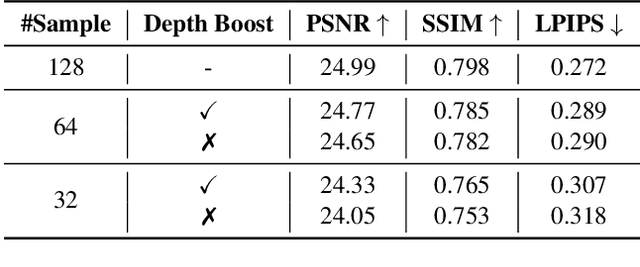
Neural radiance fields (NeRF) have shown great potentials in representing 3D scenes and synthesizing novel views, but the computational overhead of NeRF at the inference stage is still heavy. To alleviate the burden, we delve into the coarse-to-fine, hierarchical sampling procedure of NeRF and point out that the coarse stage can be replaced by a lightweight module which we name a neural sample field. The proposed sample field maps rays into sample distributions, which can be transformed into point coordinates and fed into radiance fields for volume rendering. The overall framework is named as NeuSample. We perform experiments on Realistic Synthetic 360$^{\circ}$ and Real Forward-Facing, two popular 3D scene sets, and show that NeuSample achieves better rendering quality than NeRF while enjoying a faster inference speed. NeuSample is further compressed with a proposed sample field extraction method towards a better trade-off between quality and speed.
Semantic-Aware Generation for Self-Supervised Visual Representation Learning
Nov 25, 2021
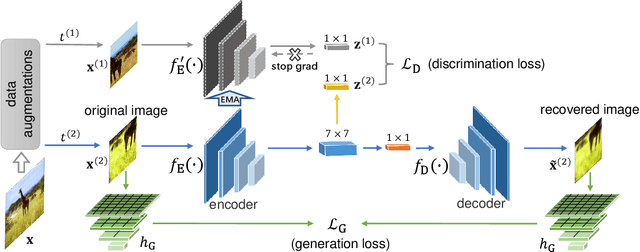

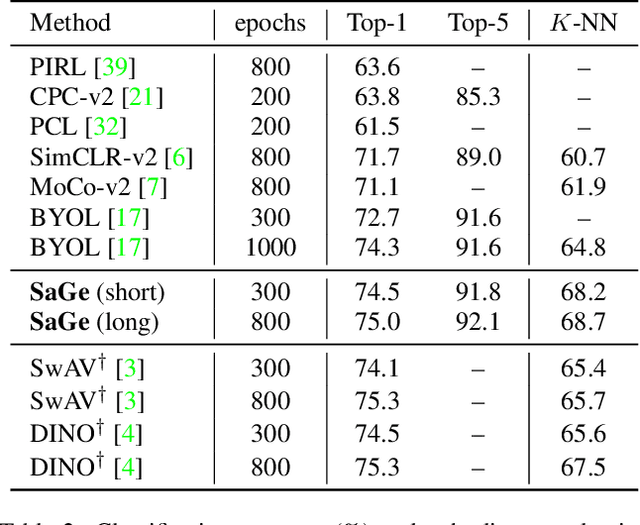
In this paper, we propose a self-supervised visual representation learning approach which involves both generative and discriminative proxies, where we focus on the former part by requiring the target network to recover the original image based on the mid-level features. Different from prior work that mostly focuses on pixel-level similarity between the original and generated images, we advocate for Semantic-aware Generation (SaGe) to facilitate richer semantics rather than details to be preserved in the generated image. The core idea of implementing SaGe is to use an evaluator, a deep network that is pre-trained without labels, for extracting semantic-aware features. SaGe complements the target network with view-specific features and thus alleviates the semantic degradation brought by intensive data augmentations. We execute SaGe on ImageNet-1K and evaluate the pre-trained models on five downstream tasks including nearest neighbor test, linear classification, and fine-scaled image recognition, demonstrating its ability to learn stronger visual representations.
Consensus Synergizes with Memory: A Simple Approach for Anomaly Segmentation in Urban Scenes
Nov 24, 2021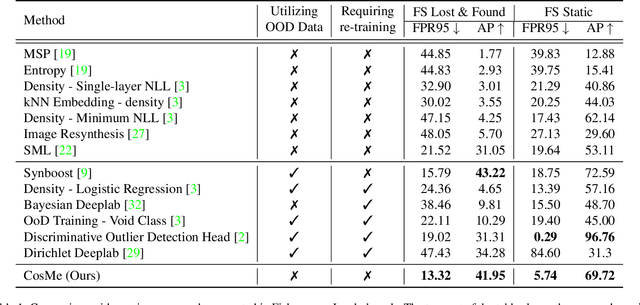
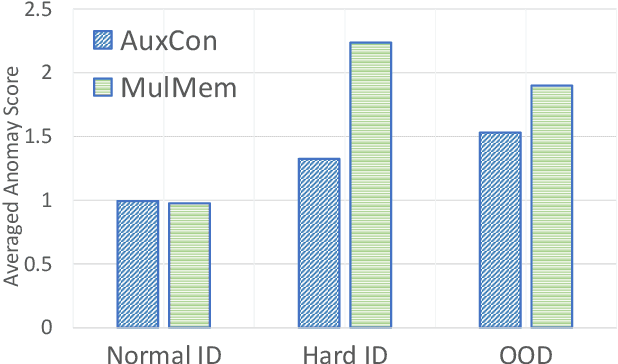
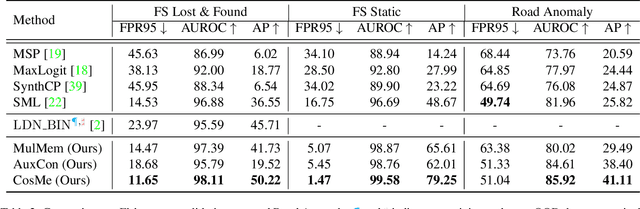
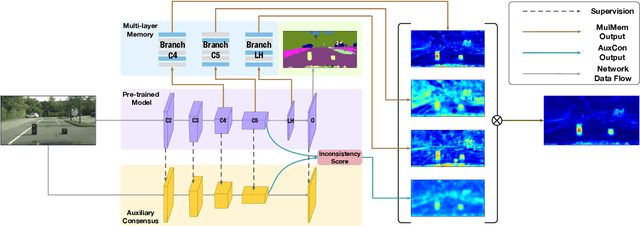
Anomaly segmentation is a crucial task for safety-critical applications, such as autonomous driving in urban scenes, where the goal is to detect out-of-distribution (OOD) objects with categories which are unseen during training. The core challenge of this task is how to distinguish hard in-distribution samples from OOD samples, which has not been explicitly discussed yet. In this paper, we propose a novel and simple approach named Consensus Synergizes with Memory (CosMe) to address this challenge, inspired by the psychology finding that groups perform better than individuals on memory tasks. The main idea is 1) building a memory bank which consists of seen prototypes extracted from multiple layers of the pre-trained segmentation model and 2) training an auxiliary model that mimics the behavior of the pre-trained model, and then measuring the consensus of their mid-level features as complementary cues that synergize with the memory bank. CosMe is good at distinguishing between hard in-distribution examples and OOD samples. Experimental results on several urban scene anomaly segmentation datasets show that CosMe outperforms previous approaches by large margins.
CIPS-3D: A 3D-Aware Generator of GANs Based on Conditionally-Independent Pixel Synthesis
Oct 19, 2021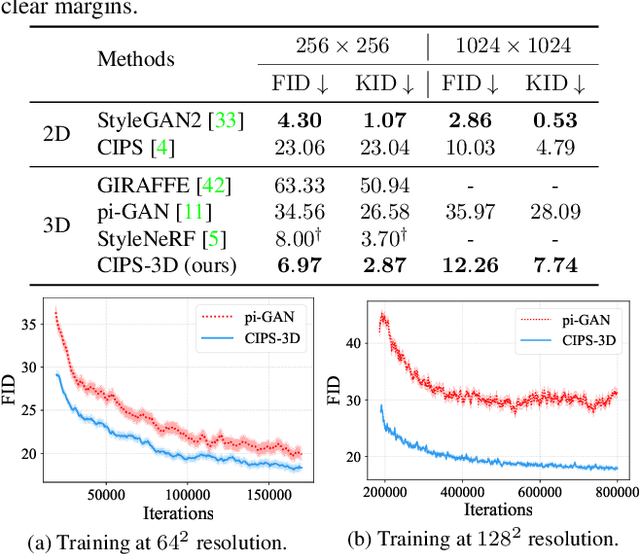
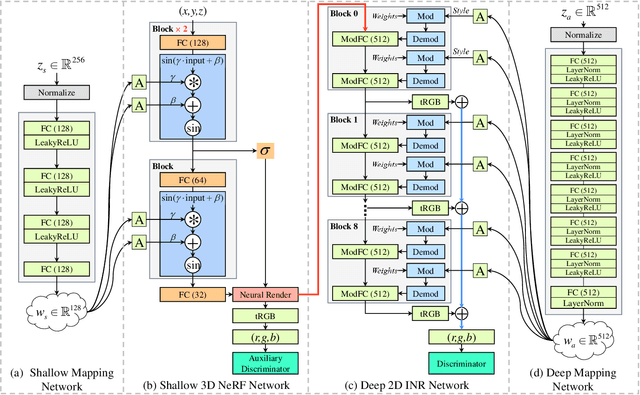

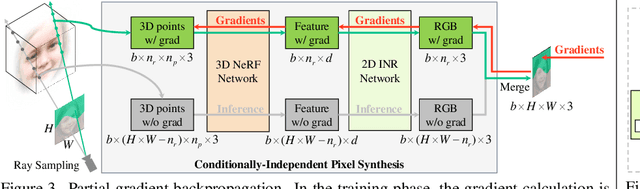
The style-based GAN (StyleGAN) architecture achieved state-of-the-art results for generating high-quality images, but it lacks explicit and precise control over camera poses. The recently proposed NeRF-based GANs made great progress towards 3D-aware generators, but they are unable to generate high-quality images yet. This paper presents CIPS-3D, a style-based, 3D-aware generator that is composed of a shallow NeRF network and a deep implicit neural representation (INR) network. The generator synthesizes each pixel value independently without any spatial convolution or upsampling operation. In addition, we diagnose the problem of mirror symmetry that implies a suboptimal solution and solve it by introducing an auxiliary discriminator. Trained on raw, single-view images, CIPS-3D sets new records for 3D-aware image synthesis with an impressive FID of 6.97 for images at the $256\times256$ resolution on FFHQ. We also demonstrate several interesting directions for CIPS-3D such as transfer learning and 3D-aware face stylization. The synthesis results are best viewed as videos, so we recommend the readers to check our github project at https://github.com/PeterouZh/CIPS-3D
Rectifying the Shortcut Learning of Background: Shared Object Concentration for Few-Shot Image Recognition
Jul 16, 2021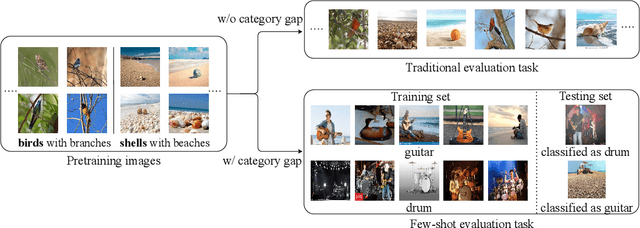
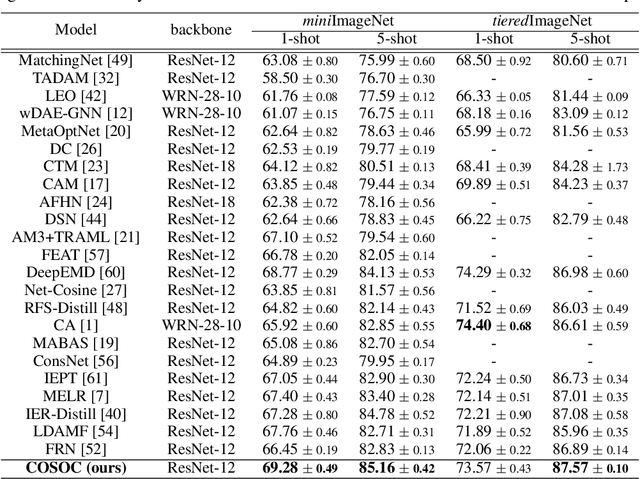
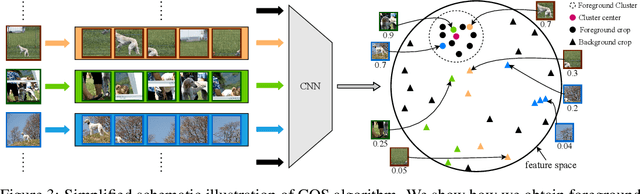
Few-Shot image classification aims to utilize pretrained knowledge learned from a large-scale dataset to tackle a series of downstream classification tasks. Typically, each task involves only few training examples from brand-new categories. This requires the pretraining models to focus on well-generalizable knowledge, but ignore domain-specific information. In this paper, we observe that image background serves as a source of domain-specific knowledge, which is a shortcut for models to learn in the source dataset, but is harmful when adapting to brand-new classes. To prevent the model from learning this shortcut knowledge, we propose COSOC, a novel Few-Shot Learning framework, to automatically figure out foreground objects at both pretraining and evaluation stage. COSOC is a two-stage algorithm motivated by the observation that foreground objects from different images within the same class share more similar patterns than backgrounds. At the pretraining stage, for each class, we cluster contrastive-pretrained features of randomly cropped image patches, such that crops containing only foreground objects can be identified by a single cluster. We then force the pretraining model to focus on found foreground objects by a fusion sampling strategy; at the evaluation stage, among images in each training class of any few-shot task, we seek for shared contents and filter out background. The recognized foreground objects of each class are used to match foreground of testing images. Extensive experiments tailored to inductive FSL tasks on two benchmarks demonstrate the state-of-the-art performance of our method.
Bag of Instances Aggregation Boosts Self-supervised Learning
Jul 04, 2021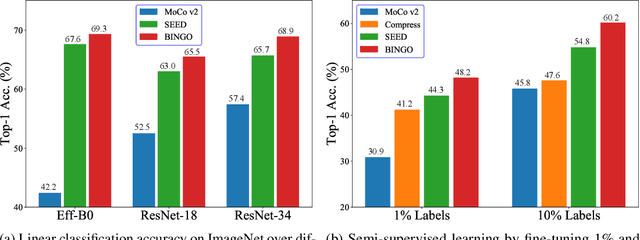
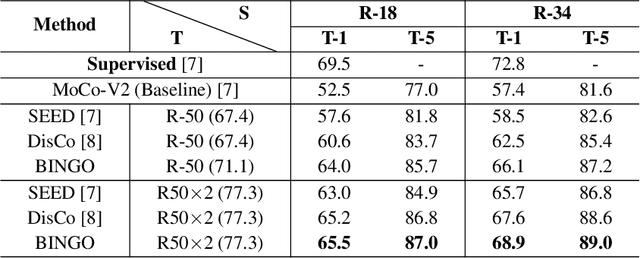
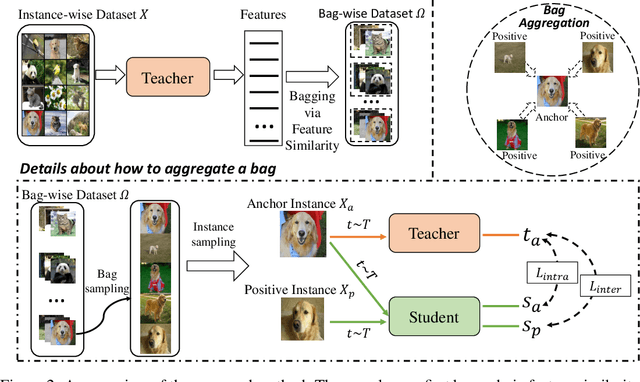
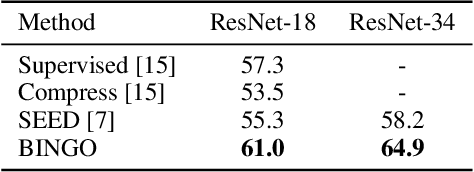
Recent advances in self-supervised learning have experienced remarkable progress, especially for contrastive learning based methods, which regard each image as well as its augmentations as an individual class and try to distinguish them from all other images. However, due to the large quantity of exemplars, this kind of pretext task intrinsically suffers from slow convergence and is hard for optimization. This is especially true for small scale models, which we find the performance drops dramatically comparing with its supervised counterpart. In this paper, we propose a simple but effective distillation strategy for unsupervised learning. The highlight is that the relationship among similar samples counts and can be seamlessly transferred to the student to boost the performance. Our method, termed as BINGO, which is short for \textbf{B}ag of \textbf{I}nsta\textbf{N}ces a\textbf{G}gregati\textbf{O}n, targets at transferring the relationship learned by the teacher to the student. Here bag of instances indicates a set of similar samples constructed by the teacher and are grouped within a bag, and the goal of distillation is to aggregate compact representations over the student with respect to instances in a bag. Notably, BINGO achieves new state-of-the-art performance on small scale models, \emph{i.e.}, 65.5% and 68.9% top-1 accuracies with linear evaluation on ImageNet, using ResNet-18 and ResNet-34 as backbone, respectively, surpassing baselines (52.5% and 57.4% top-1 accuracies) by a significant margin. The code will be available at \url{https://github.com/haohang96/bingo}.
Exploring the Diversity and Invariance in Yourself for Visual Pre-Training Task
Jun 01, 2021
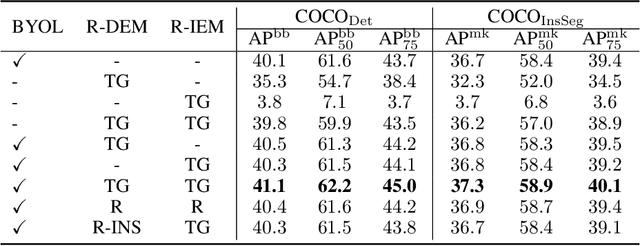
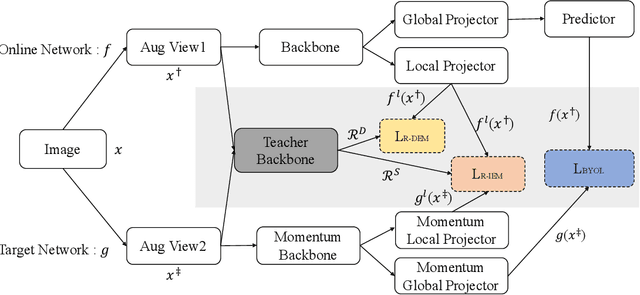
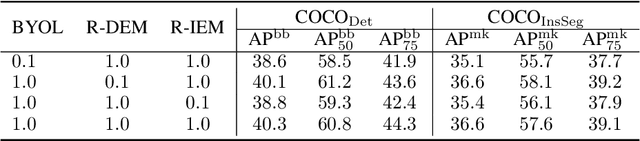
Recently, self-supervised learning methods have achieved remarkable success in visual pre-training task. By simply pulling the different augmented views of each image together or other novel mechanisms, they can learn much unsupervised knowledge and significantly improve the transfer performance of pre-training models. However, these works still cannot avoid the representation collapse problem, i.e., they only focus on limited regions or the extracted features on totally different regions inside each image are nearly the same. Generally, this problem makes the pre-training models cannot sufficiently describe the multi-grained information inside images, which further limits the upper bound of their transfer performance. To alleviate this issue, this paper introduces a simple but effective mechanism, called Exploring the Diversity and Invariance in Yourself E-DIY. By simply pushing the most different regions inside each augmented view away, E-DIY can preserve the diversity of extracted region-level features. By pulling the most similar regions from different augmented views of the same image together, E-DIY can ensure the robustness of region-level features. Benefited from the above diversity and invariance exploring mechanism, E-DIY maximally extracts the multi-grained visual information inside each image. Extensive experiments on downstream tasks demonstrate the superiority of our proposed approach, e.g., there are 2.1% improvements compared with the strong baseline BYOL on COCO while fine-tuning Mask R-CNN with the R50-C4 backbone and 1X learning schedule.