 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenseLight: Efficient Control for Large-scale Traffic Signals with Dense Feedback
Jun 13, 2023



Traffic Signal Control (TSC) aims to reduce the average travel time of vehicles in a road network, which in turn enhances fuel utilization efficiency, air quality, and road safety, benefiting society as a whole. Due to the complexity of long-horizon control and coordination, most prior TSC methods leverage deep reinforcement learning (RL) to search for a control policy and have witnessed great success. However, TSC still faces two significant challenges. 1) The travel time of a vehicle is delayed feedback on the effectiveness of TSC policy at each traffic intersection since it is obtained after the vehicle has left the road network. Although several heuristic reward functions have been proposed as substitutes for travel time, they are usually biased and not leading the policy to improve in the correct direction. 2) The traffic condition of each intersection is influenced by the non-local intersections since vehicles traverse multiple intersections over time. Therefore, the TSC agent is required to leverage both the local observation and the non-local traffic conditions to predict the long-horizontal traffic conditions of each intersection comprehensively. To address these challenges, we propose DenseLight, a novel RL-based TSC method that employs an unbiased reward function to provide dense feedback on policy effectiveness and a non-local enhanced TSC agent to better predict future traffic conditions for more precise traffic control. Extensive experiments and ablation studies demonstrate that DenseLight can consistently outperform advanced baselines on various road networks with diverse traffic flows. The code is available at https://github.com/junfanlin/DenseLight.
Long-term Wind Power Forecasting with Hierarchical Spatial-Temporal Transformer
May 30, 2023Wind power is attracting increasing attention around the world due to its renewable, pollution-free, and other advantages. However, safely and stably integrating the high permeability intermittent power energy into electric power systems remains challenging. Accurate wind power forecasting (WPF) can effectively reduce power fluctuations in power system operations. Existing methods are mainly designed for short-term predictions and lack effective spatial-temporal feature augmentation. In this work, we propose a novel end-to-end wind power forecasting model named Hierarchical Spatial-Temporal Transformer Network (HSTTN) to address the long-term WPF problems. Specifically, we construct an hourglass-shaped encoder-decoder framework with skip-connections to jointly model representations aggregated in hierarchical temporal scales, which benefits long-term forecasting. Based on this framework, we capture the inter-scale long-range temporal dependencies and global spatial correlations with two parallel Transformer skeletons and strengthen the intra-scale connections with downsampling and upsampling operations. Moreover, the complementary information from spatial and temporal features is fused and propagated in each other via Contextual Fusion Blocks (CFBs) to promote the prediction further. Extensive experimental results on two large-scale real-world datasets demonstrate the superior performance of our HSTTN over existing solutions.
CLIP-Count: Towards Text-Guided Zero-Shot Object Counting
May 12, 2023



Recent advances in visual-language models have shown remarkable zero-shot text-image matching ability that is transferable to down-stream tasks such as object detection and segmentation. However, adapting these models for object counting, which involves estimating the number of objects in an image, remains a formidable challenge. In this study, we conduct the first exploration of transferring visual-language models for class-agnostic object counting. Specifically, we propose CLIP-Count, a novel pipeline that estimates density maps for open-vocabulary objects with text guidance in a zero-shot manner, without requiring any finetuning on specific object classes. To align the text embedding with dense image features, we introduce a patch-text contrastive loss that guides the model to learn informative patch-level image representations for dense prediction. Moreover, we design a hierarchical patch-text interaction module that propagates semantic information across different resolution levels of image features. Benefiting from the full exploitation of the rich image-text alignment knowledge of pretrained visual-language models, our method effectively generates high-quality density maps for objects-of-interest. Extensive experiments on FSC-147, CARPK, and ShanghaiTech crowd counting datasets demonstrate that our proposed method achieves state-of-the-art accuracy and generalizability for zero-shot object counting. Project page at https://github.com/songrise/CLIP-Count
Visual Tuning
May 10, 2023Fine-tuning visual models has been widely shown promising performance on many downstream visual tasks. With the surprising development of pre-trained visual foundation models, visual tuning jumped out of the standard modus operandi that fine-tunes the whole pre-trained model or just the fully connected layer. Instead, recent advances can achieve superior performance than full-tuning the whole pre-trained parameters by updating far fewer parameters, enabling edge devices and downstream applications to reuse the increasingly large foundation models deployed on the cloud. With the aim of helping researchers get the full picture and future directions of visual tuning, this survey characterizes a large and thoughtful selection of recent works, providing a systematic and comprehensive overview of existing work and models. Specifically, it provides a detailed background of visual tuning and categorizes recent visual tuning techniques into five groups: prompt tuning, adapter tuning, parameter tuning, and remapping tuning. Meanwhile, it offers some exciting research directions for prospective pre-training and various interactions in visual tuning.
Urban Regional Function Guided Traffic Flow Prediction
Mar 20, 2023



The prediction of traffic flow is a challenging yet crucial problem in spatial-temporal analysis, which has recently gained increasing interest. In addition to spatial-temporal correlations, the functionality of urban areas also plays a crucial role in traffic flow prediction. However, the exploration of regional functional attributes mainly focuses on adding additional topological structures, ignoring the influence of functional attributes on regional traffic patterns. Different from the existing works, we propose a novel module named POI-MetaBlock, which utilizes the functionality of each region (represented by Point of Interest distribution) as metadata to further mine different traffic characteristics in areas with different functions. Specifically, the proposed POI-MetaBlock employs a self-attention architecture and incorporates POI and time information to generate dynamic attention parameters for each region, which enables the model to fit different traffic patterns of various areas at different times. Furthermore, our lightweight POI-MetaBlock can be easily integrated into conventional traffic flow prediction models. Extensive experiments demonstrate that our module significantly improves the performance of traffic flow prediction and outperforms state-of-the-art methods that use metadata.
OhMG: Zero-shot Open-vocabulary Human Motion Generation
Oct 28, 2022



Generating motion in line with text has attracted increasing attention nowadays. However, open-vocabulary human motion generation still remains touchless and undergoes the lack of diverse labeled data. The good news is that, recent studies of large multi-model foundation models (e.g., CLIP) have demonstrated superior performance on few/zero-shot image-text alignment, largely reducing the need for manually labeled data. In this paper, we take advantage of CLIP for open-vocabulary 3D human motion generation in a zero-shot manner. Specifically, our model is composed of two stages, i.e., text2pose and pose2motion. For text2pose, to address the difficulty of optimization with direct supervision from CLIP, we propose to carve the versatile CLIP model into a slimmer but more specific model for aligning 3D poses and texts, via a novel pipeline distillation strategy. Optimizing with the distilled 3D pose-text model, we manage to concretize the text-pose knowledge of CLIP into a text2pose generator effectively and efficiently. As for pose2motion, drawing inspiration from the advanced language model, we pretrain a transformer-based motion model, which makes up for the lack of motion dynamics of CLIP. After that, by formulating the generated poses from the text2pose stage as prompts, the motion generator can generate motions referring to the poses in a controllable and flexible manner. Our method is validated against advanced baselines and obtains sharp improvements. The code will be released here.
Towards a Unified View on Visual Parameter-Efficient Transfer Learning
Oct 03, 2022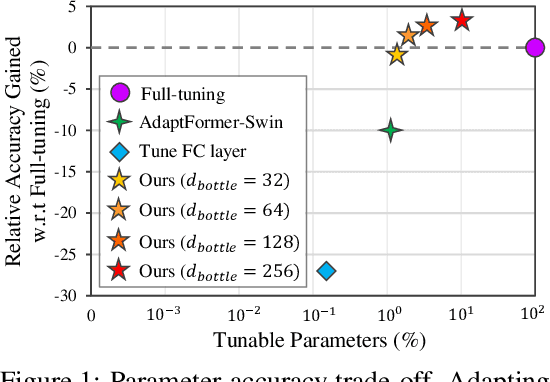
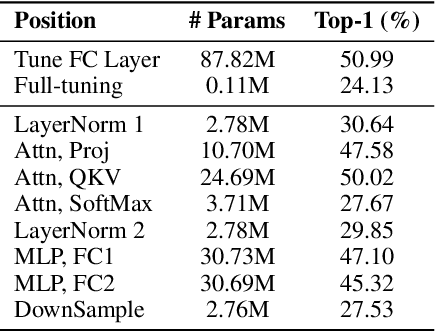
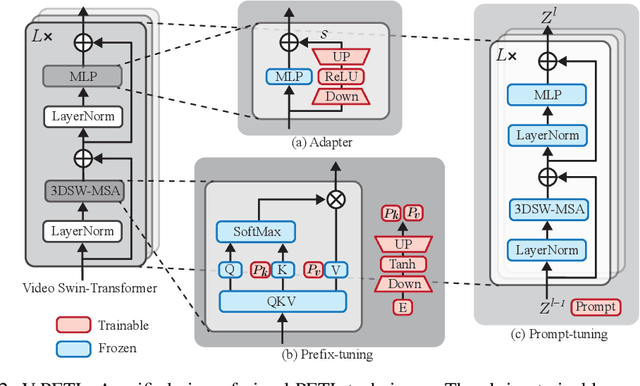
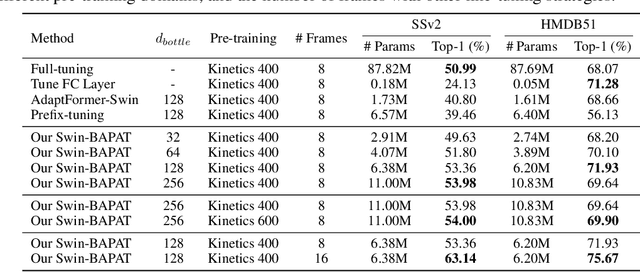
Since the release of various large-scale natural language processing (NLP) pre-trained models, parameter efficient transfer learning (PETL) has become a popular paradigm capable of achieving impressive performance on various downstream tasks. PETL aims at making good use of the representation knowledge in the pre-trained large models by fine-tuning a small number of parameters. Recently, it has also attracted increasing attention to developing various PETL techniques for vision tasks. Popular PETL techniques such as Prompt-tuning and Adapter have been proposed for high-level visual downstream tasks such as image classification and video recognition. However, Prefix-tuning remains under-explored for vision tasks. In this work, we intend to adapt large video-based models to downstream tasks with a good parameter-accuracy trade-off. Towards this goal, we propose a framework with a unified view called visual-PETL (V-PETL) to investigate the different aspects affecting the trade-off. Specifically, we analyze the positional importance of trainable parameters and differences between NLP and vision tasks in terms of data structures and pre-training mechanisms while implementing various PETL techniques, especially for the under-explored prefix-tuning technique. Based on a comprehensive understanding of differences between NLP and video data, we propose a new variation of prefix-tuning module called parallel attention (PATT) for video-based downstream tasks. An extensive empirical analysis on two video datasets via different frozen backbones has been carried and the findings show that the proposed PATT can effectively contribute to other PETL techniques. An effective scheme Swin-BAPAT derived from the proposed V-PETL framework achieves significantly better performance than the state-of-the-art AdaptFormer-Swin with slightly more parameters and outperforms full-tuning with far less parameters.
Prompt-Matched Semantic Segmentation
Aug 22, 2022
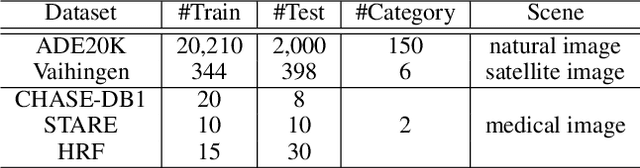

The objective of this work is to explore how to effectively and efficiently adapt pre-trained foundation models to various downstream tasks of image semantic segmentation. Conventional methods usually fine-tuned the whole networks for each specific dataset and it was burdensome to store the massive parameters of these networks. A few recent works attempted to insert some trainable parameters into the frozen network to learn visual prompts for efficient tuning. However, these works significantly modified the original structure of standard modules, making them inoperable on many existing high-speed inference devices, where standard modules and their parameters have been embedded. To facilitate prompt-based semantic segmentation, we propose a novel Inter-Stage Prompt-Matched Framework, which maintains the original structure of the foundation model while generating visual prompts adaptively for task-oriented tuning. Specifically, the pre-trained model is first divided into multiple stages, and their parameters are frozen and shared for all semantic segmentation tasks. A lightweight module termed Semantic-aware Prompt Matcher is then introduced to hierarchically interpolate between two stages to learn reasonable prompts for each specific task under the guidance of interim semantic maps. In this way, we can better stimulate the pre-trained knowledge of the frozen model to learn semantic concepts effectively on downstream datasets. Extensive experiments conducted on five benchmarks show that the proposed method can achieve a promising trade-off between parameter efficiency and performance effectiveness.
Probing Visual-Audio Representation for Video Highlight Detection via Hard-Pairs Guided Contrastive Learning
Jun 21, 2022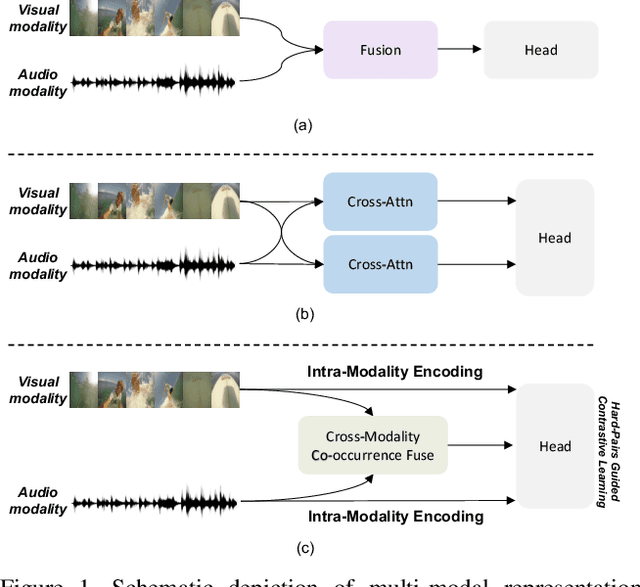

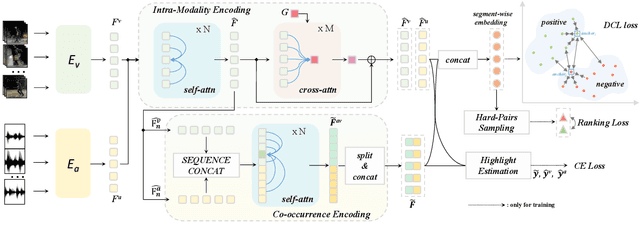
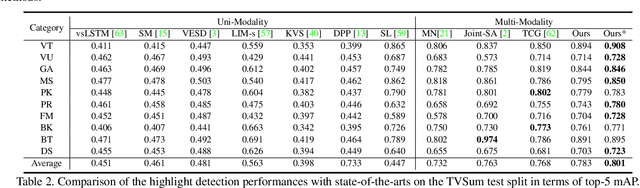
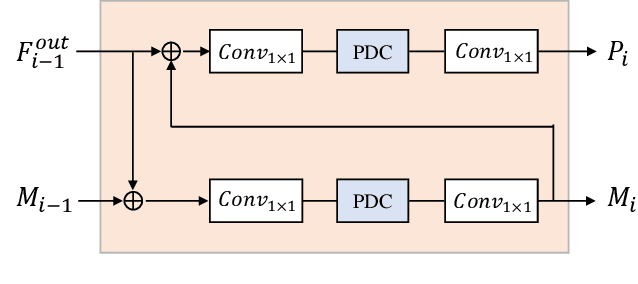
Video highlight detection is a crucial yet challenging problem that aims to identify the interesting moments in untrimmed videos. The key to this task lies in effective video representations that jointly pursue two goals, \textit{i.e.}, cross-modal representation learning and fine-grained feature discrimination. In this paper, these two challenges are tackled by not only enriching intra-modality and cross-modality relations for representation modeling but also shaping the features in a discriminative manner. Our proposed method mainly leverages the intra-modality encoding and cross-modality co-occurrence encoding for fully representation modeling. Specifically, intra-modality encoding augments the modality-wise features and dampens irrelevant modality via within-modality relation learning in both audio and visual signals. Meanwhile, cross-modality co-occurrence encoding focuses on the co-occurrence inter-modality relations and selectively captures effective information among multi-modality. The multi-modal representation is further enhanced by the global information abstracted from the local context. In addition, we enlarge the discriminative power of feature embedding with a hard-pairs guided contrastive learning (HPCL) scheme. A hard-pairs sampling strategy is further employed to mine the hard samples for improving feature discrimination in HPCL. Extensive experiments conducted on two benchmarks demonstrate the effectiveness and superiority of our proposed methods compared to other state-of-the-art methods.
Pyramid Region-based Slot Attention Network for Temporal Action Proposal Generation
Jun 21, 2022
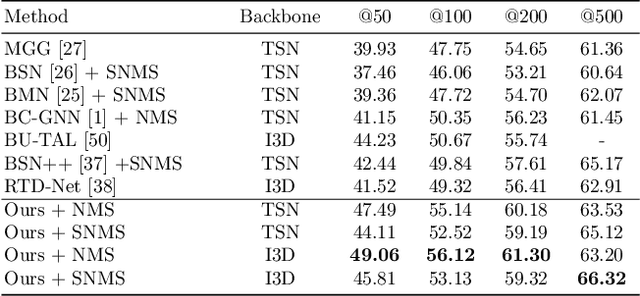
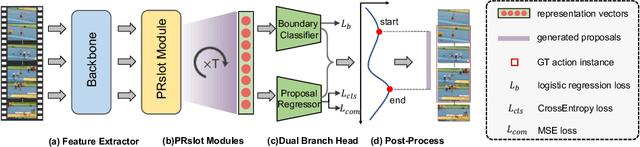

It has been found that temporal action proposal generation, which aims to discover the temporal action instances within the range of the start and end frames in the untrimmed videos, can largely benefit from proper temporal and semantic context exploitation. The latest efforts were dedicated to considering the temporal context and similarity-based semantic contexts through self-attention modules. However, they still suffer from cluttered background information and limited contextual feature learning. In this paper, we propose a novel Pyramid Region-based Slot Attention (PRSlot) module to address these issues. Instead of using the similarity computation, our PRSlot module directly learns the local relations in an encoder-decoder manner and generates the representation of a local region enhanced based on the attention over input features called \textit{slot}. Specifically, upon the input snippet-level features, PRSlot module takes the target snippet as \textit{query}, its surrounding region as \textit{key} and then generates slot representations for each \textit{query-key} slot by aggregating the local snippet context with a parallel pyramid strategy. Based on PRSlot modules, we present a novel Pyramid Region-based Slot Attention Network termed PRSA-Net to learn a unified visual representation with rich temporal and semantic context for better proposal generation. Extensive experiments are conducted on two widely adopted THUMOS14 and ActivityNet-1.3 benchmarks. Our PRSA-Net outperforms other state-of-the-art methods. In particular, we improve the AR@100 from the previous best 50.67% to 56.12% for proposal generation and raise the mAP under 0.5 tIoU from 51.9\% to 58.7\% for action detection on THUMOS14. \textit{Code is available at} \url{https://github.com/handhand123/PRSA-Net}