 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Contrastive Learning for Self-supervised Action Recognition
Apr 28, 2022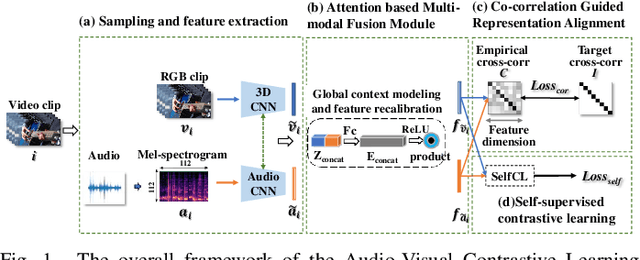


The underlying correlation between audio and visual modalities within videos can be utilized to learn supervised information for unlabeled videos. In this paper, we present an end-to-end self-supervised framework named Audio-Visual Contrastive Learning (AVCL), to learn discriminative audio-visual representations for action recognition. Specifically, we design an attention based multi-modal fusion module (AMFM) to fuse audio and visual modalities. To align heterogeneous audio-visual modalities, we construct a novel co-correlation guided representation alignment module (CGRA). To learn supervised information from unlabeled videos, we propose a novel self-supervised contrastive learning module (SelfCL). Furthermore, to expand the existing audio-visual action recognition datasets and better evaluate our framework AVCL, we build a new audio-visual action recognition dataset named Kinetics-Sounds100. Experimental results on Kinetics-Sounds32 and Kinetics-Sounds100 datasets demonstrate the superiority of our AVCL over the state-of-the-art methods on large-scale action recognition benchmark.
TCGL: Temporal Contrastive Graph for Self-supervised Video Representation Learning
Jan 05, 2022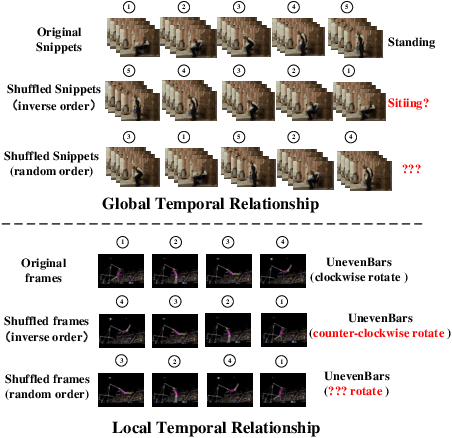
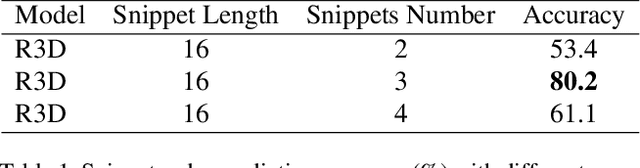
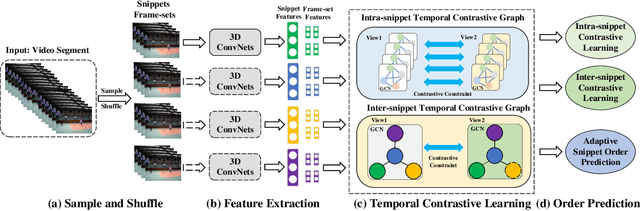

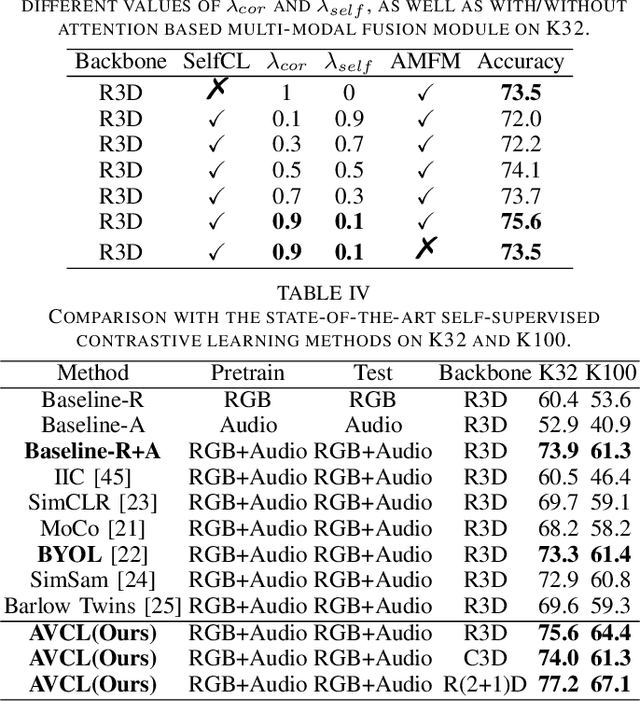
Video self-supervised learning is a challenging task, which requires significant expressive power from the model to leverage rich spatial-temporal knowledge and generate effective supervisory signals from large amounts of unlabeled videos. However, existing methods fail to increase the temporal diversity of unlabeled videos and ignore elaborately modeling multi-scale temporal dependencies in an explicit way. To overcome these limitations, we take advantage of the multi-scale temporal dependencies within videos and proposes a novel video self-supervised learning framework named Temporal Contrastive Graph Learning (TCGL), which jointly models the inter-snippet and intra-snippet temporal dependencies for temporal representation learning with a hybrid graph contrastive learning strategy. Specifically, a Spatial-Temporal Knowledge Discovering (STKD) module is first introduced to extract motion-enhanced spatial-temporal representations from videos based on the frequency domain analysis of discrete cosine transform. To explicitly model multi-scale temporal dependencies of unlabeled videos, our TCGL integrates the prior knowledge about the frame and snippet orders into graph structures, i.e., the intra-/inter- snippet Temporal Contrastive Graphs (TCG). Then, specific contrastive learning modules are designed to maximize the agreement between nodes in different graph views. To generate supervisory signals for unlabeled videos, we introduce an Adaptive Snippet Order Prediction (ASOP) module which leverages the relational knowledge among video snippets to learn the global context representation and recalibrate the channel-wise features adaptively. Experimental results demonstrate the superiority of our TCGL over the state-of-the-art methods on large-scale action recognition and video retrieval benchmarks.The code is publicly available at https://github.com/YangLiu9208/TCGL.
Temporal Contrastive Graph for Self-supervised Video Representation Learning
Feb 01, 2021

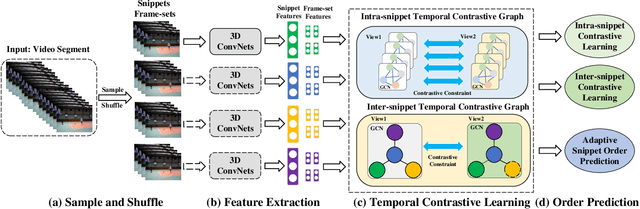

Attempt to fully explore the fine-grained temporal structure and global-local chronological characteristics for self-supervised video representation learning, this work takes a closer look at exploiting the temporal structure of videos and further proposes a novel self-supervised method named Temporal Contrastive Graph (TCG). In contrast to the existing methods that randomly shuffle the video frames or video snippets within a video, our proposed TCG roots in a hybrid graph contrastive learning strategy to regard the inter-snippet and intra-snippet temporal relationships as self-supervision signals for temporal representation learning. To increase the temporal diversity of features more comprehensively and precisely, our proposed TCG integrates the prior knowledge about the frame and snippet orders into temporal contrastive graph structures, i.e., the intra-/inter- snippet temporal contrastive graph modules. By randomly removing edges and masking node features of the intra-snippet graphs or inter-snippet graphs, our TCG can generate different correlated graph views. Then, specific contrastive losses are designed to maximize the agreement between node embeddings in different views. To learn the global context representation and recalibrate the channel-wise features adaptively, we introduce an adaptive video snippet order prediction module, which leverages the relational knowledge among video snippets to predict the actual snippet orders.Experimental results demonstrate the superiority of our TCG over the state-of-the-art methods on large-scale action recognition and video retrieval benchmarks.