 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTstars-Tryon 1.0: Robust and Realistic Virtual Try-On for Diverse Fashion Items
Apr 22, 2026Recent advances in image generation and editing have opened new opportunities for virtual try-on. However, existing methods still struggle to meet complex real-world demands. We present Tstars-Tryon 1.0, a commercial-scale virtual try-on system that is robust, realistic, versatile, and highly efficient. First, our system maintains a high success rate across challenging cases like extreme poses, severe illumination variations, motion blur, and other in-the-wild conditions. Second, it delivers highly photorealistic results with fine-grained details, faithfully preserving garment texture, material properties, and structural characteristics, while largely avoiding common AI-generated artifacts. Third, beyond apparel try-on, our model supports flexible multi-image composition (up to 6 reference images) across 8 fashion categories, with coordinated control over person identity and background. Fourth, to overcome the latency bottlenecks of commercial deployment, our system is heavily optimized for inference speed, delivering near real-time generation for a seamless user experience. These capabilities are enabled by an integrated system design spanning end-to-end model architecture, a scalable data engine, robust infrastructure, and a multi-stage training paradigm. Extensive evaluation and large-scale product deployment demonstrate that Tstars-Tryon1.0 achieves leading overall performance. To support future research, we also release a comprehensive benchmark. The model has been deployed at an industrial scale on the Taobao App, serving millions of users with tens of millions of requests.
Unconstrained Face Sketch Synthesis via Perception-Adaptive Network and A New Benchmark
Dec 02, 2021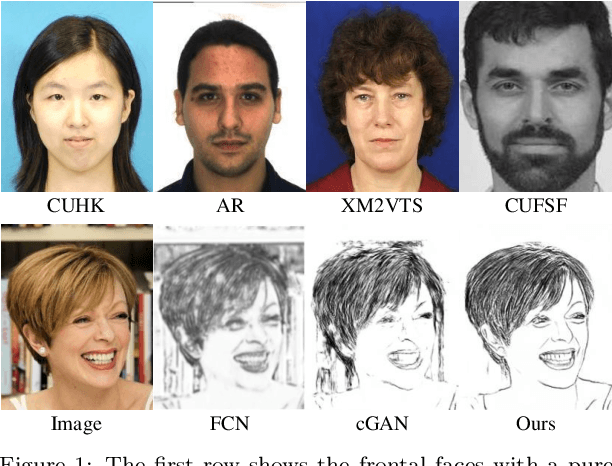
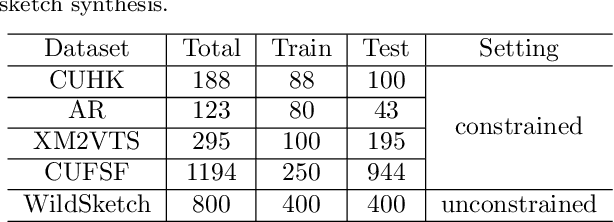

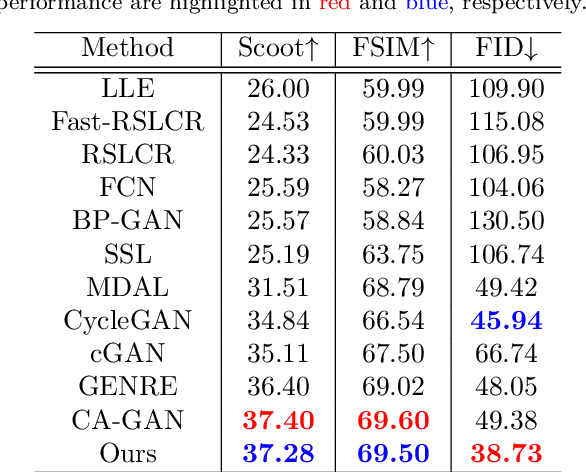
Face sketch generation has attracted much attention in the field of visual computing. However, existing methods either are limited to constrained conditions or heavily rely on various preprocessing steps to deal with in-the-wild cases. In this paper, we argue that accurately perceiving facial region and facial components is crucial for unconstrained sketch synthesis. To this end, we propose a novel Perception-Adaptive Network (PANet), which can generate high-quality face sketches under unconstrained conditions in an end-to-end scheme. Specifically, our PANet is composed of i) a Fully Convolutional Encoder for hierarchical feature extraction, ii) a Face-Adaptive Perceiving Decoder for extracting potential facial region and handling face variations, and iii) a Component-Adaptive Perceiving Module for facial component aware feature representation learning. To facilitate further researches of unconstrained face sketch synthesis, we introduce a new benchmark termed WildSketch, which contains 800 pairs of face photo-sketch with large variations in pose, expression, ethnic origin, background, and illumination. Extensive experiments demonstrate that the proposed method is capable of achieving state-of-the-art performance under both constrained and unconstrained conditions. Our source codes and the WildSketch benchmark are resealed on the project page http://lingboliu.com/unconstrained_face_sketch.html.