 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarize and Search: Learning Consensus-aware Dynamic Convolution for Co-Saliency Detection
Oct 01, 2021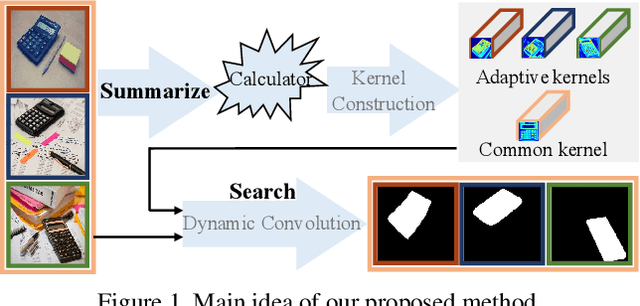
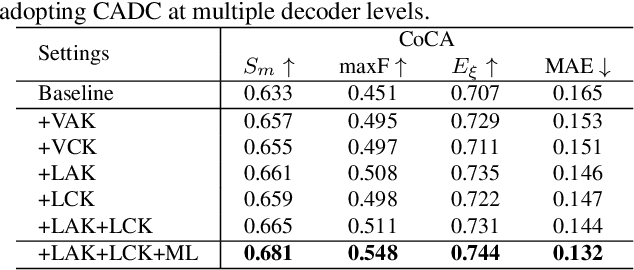
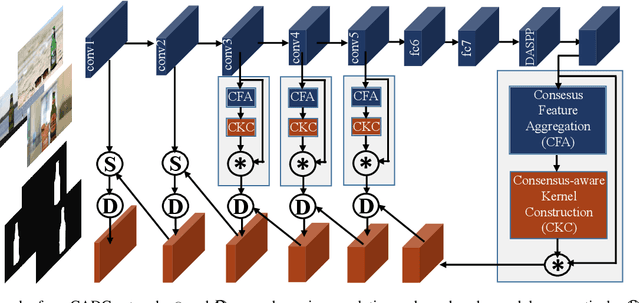
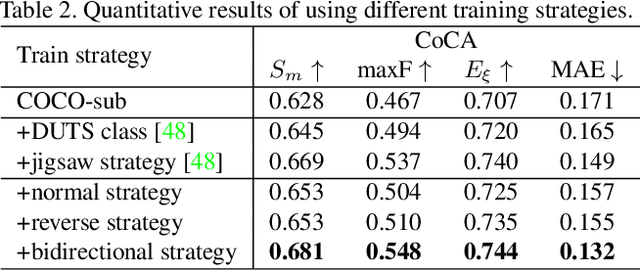
Humans perform co-saliency detection by first summarizing the consensus knowledge in the whole group and then searching corresponding objects in each image. Previous methods usually lack robustness, scalability, or stability for the first process and simply fuse consensus features with image features for the second process. In this paper, we propose a novel consensus-aware dynamic convolution model to explicitly and effectively perform the "summarize and search" process. To summarize consensus image features, we first summarize robust features for every single image using an effective pooling method and then aggregate cross-image consensus cues via the self-attention mechanism. By doing this, our model meets the scalability and stability requirements. Next, we generate dynamic kernels from consensus features to encode the summarized consensus knowledge. Two kinds of kernels are generated in a supplementary way to summarize fine-grained image-specific consensus object cues and the coarse group-wise common knowledge, respectively. Then, we can effectively perform object searching by employing dynamic convolution at multiple scales. Besides, a novel and effective data synthesis method is also proposed to train our network. Experimental results on four benchmark datasets verify the effectiveness of our proposed method. Our code and saliency maps are available at \url{https://github.com/nnizhang/CADC}.
RGB-D Saliency Detection via Cascaded Mutual Information Minimization
Sep 15, 2021

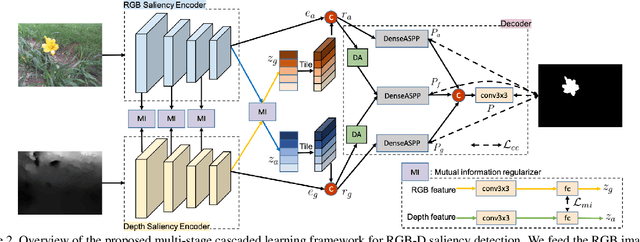
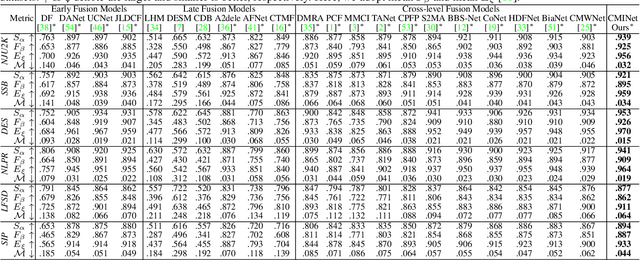
Existing RGB-D saliency detection models do not explicitly encourage RGB and depth to achieve effective multi-modal learning. In this paper, we introduce a novel multi-stage cascaded learning framework via mutual information minimization to "explicitly" model the multi-modal information between RGB image and depth data. Specifically, we first map the feature of each mode to a lower dimensional feature vector, and adopt mutual information minimization as a regularizer to reduce the redundancy between appearance features from RGB and geometric features from depth. We then perform multi-stage cascaded learning to impose the mutual information minimization constraint at every stage of the network. Extensive experiments on benchmark RGB-D saliency datasets illustrate the effectiveness of our framework. Further, to prosper the development of this field, we contribute the largest (7x larger than NJU2K) dataset, which contains 15,625 image pairs with high quality polygon-/scribble-/object-/instance-/rank-level annotations. Based on these rich labels, we additionally construct four new benchmarks with strong baselines and observe some interesting phenomena, which can motivate future model design. Source code and dataset are available at "https://github.com/JingZhang617/cascaded_rgbd_sod".
Full-Duplex Strategy for Video Object Segmentation
Sep 03, 2021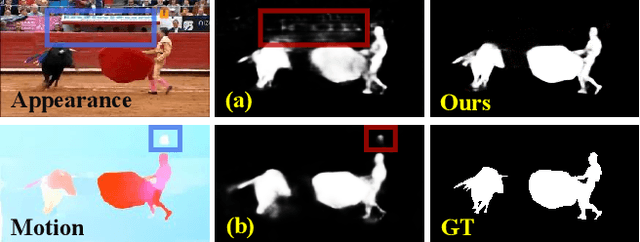

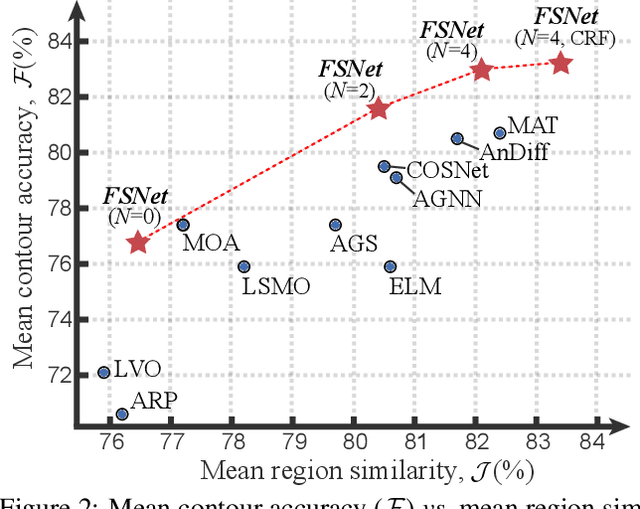
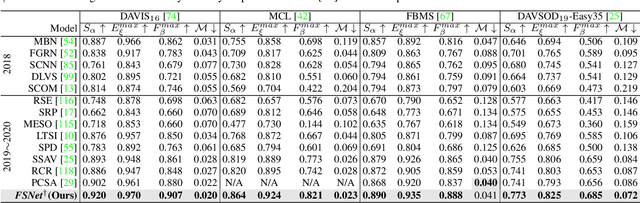
Previous video object segmentation approaches mainly focus on using simplex solutions between appearance and motion, limiting feature collaboration efficiency among and across these two cues. In this work, we study a novel and efficient full-duplex strategy network (FSNet) to address this issue, by considering a better mutual restraint scheme between motion and appearance in exploiting the cross-modal features from the fusion and decoding stage. Specifically, we introduce the relational cross-attention module (RCAM) to achieve bidirectional message propagation across embedding sub-spaces. To improve the model's robustness and update the inconsistent features from the spatial-temporal embeddings, we adopt the bidirectional purification module (BPM) after the RCAM. Extensive experiments on five popular benchmarks show that our FSNet is robust to various challenging scenarios (e.g., motion blur, occlusion) and achieves favourable performance against existing cutting-edges both in the video object segmentation and video salient object detection tasks. The project is publicly available at: https://dpfan.net/FSNet.
Exploring Separable Attention for Multi-Contrast MR Image Super-Resolution
Sep 03, 2021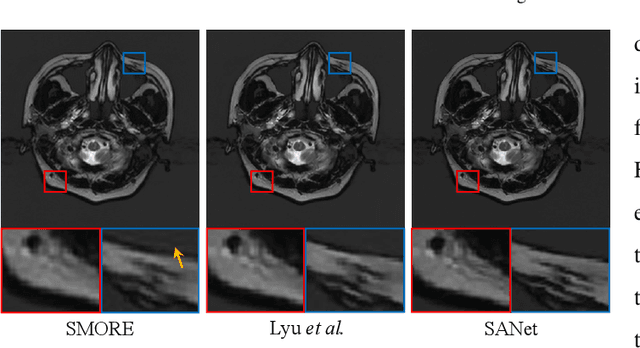
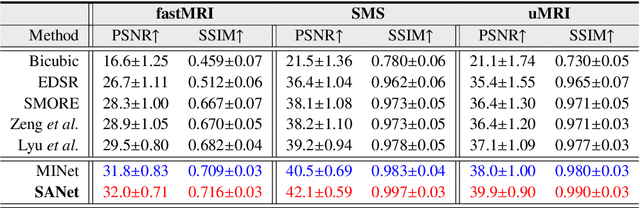
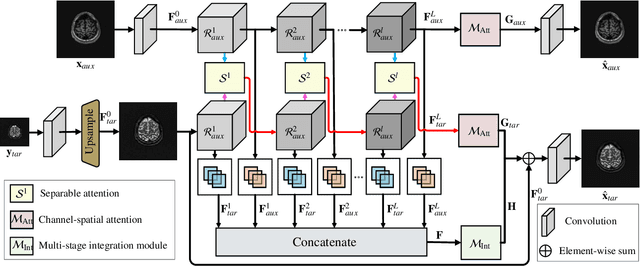
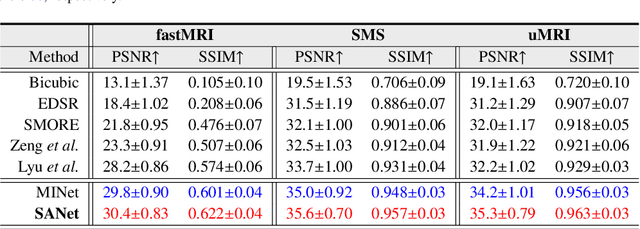
Super-resolving the Magnetic Resonance (MR) image of a target contrast under the guidance of the corresponding auxiliary contrast, which provides additional anatomical information, is a new and effective solution for fast MR imaging. However, current multi-contrast super-resolution (SR) methods tend to concatenate different contrasts directly, ignoring their relationships in different clues, \eg, in the foreground and background. In this paper, we propose a separable attention network (comprising a foreground priority attention and background separation attention), named SANet. Our method can explore the foreground and background areas in the forward and reverse directions with the help of the auxiliary contrast, enabling it to learn clearer anatomical structures and edge information for the SR of a target-contrast MR image. SANet provides three appealing benefits: (1) It is the first model to explore a separable attention mechanism that uses the auxiliary contrast to predict the foreground and background regions, diverting more attention to refining any uncertain details between these regions and correcting the fine areas in the reconstructed results. (2) A multi-stage integration module is proposed to learn the response of multi-contrast fusion at different stages, obtain the dependency between the fused features, and improve their representation ability. (3) Extensive experiments with various state-of-the-art multi-contrast SR methods on fastMRI and clinical \textit{in vivo} datasets demonstrate the superiority of our model.
Seminar Learning for Click-Level Weakly Supervised Semantic Segmentation
Aug 30, 2021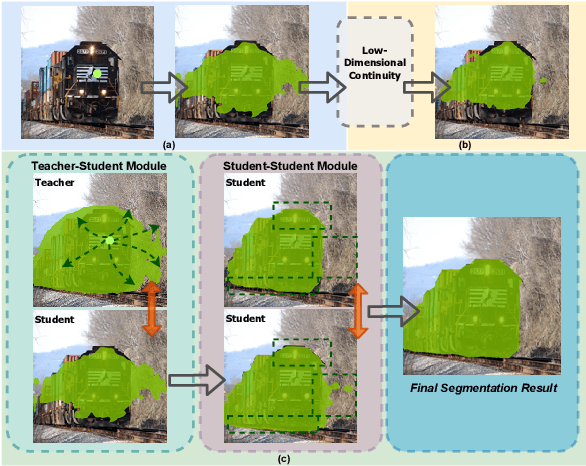
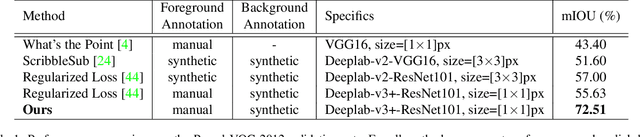

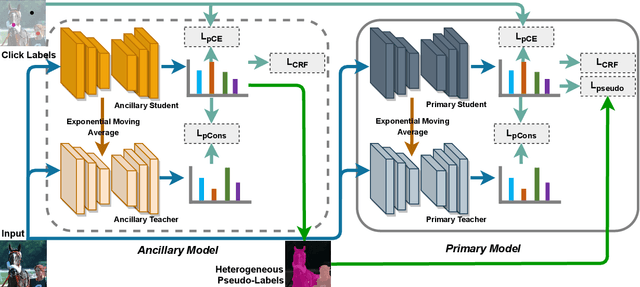
Annotation burden has become one of the biggest barriers to semantic segmentation. Approaches based on click-level annotations have therefore attracted increasing attention due to their superior trade-off between supervision and annotation cost. In this paper, we propose seminar learning, a new learning paradigm for semantic segmentation with click-level supervision. The fundamental rationale of seminar learning is to leverage the knowledge from different networks to compensate for insufficient information provided in click-level annotations. Mimicking a seminar, our seminar learning involves a teacher-student and a student-student module, where a student can learn from both skillful teachers and other students. The teacher-student module uses a teacher network based on the exponential moving average to guide the training of the student network. In the student-student module, heterogeneous pseudo-labels are proposed to bridge the transfer of knowledge among students to enhance each other's performance. Experimental results demonstrate the effectiveness of seminar learning, which achieves the new state-of-the-art performance of 72.51% (mIOU), surpassing previous methods by a large margin of up to 16.88% on the Pascal VOC 2012 dataset.
Discriminative Region-based Multi-Label Zero-Shot Learning
Aug 20, 2021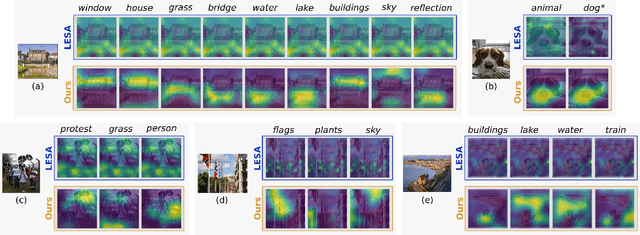
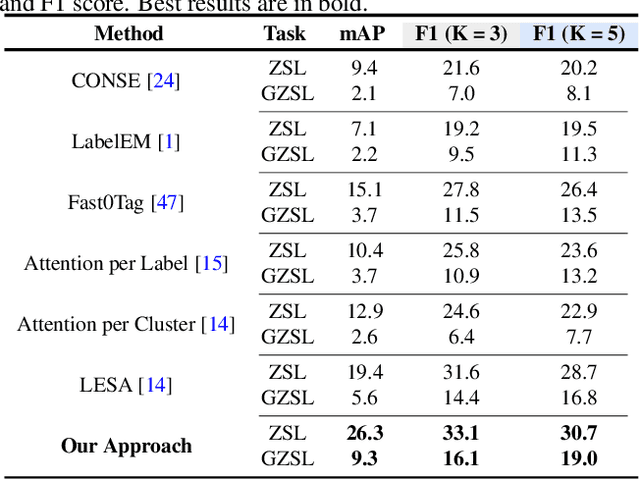
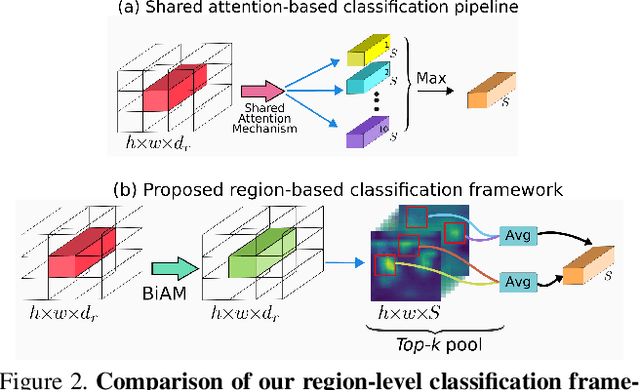
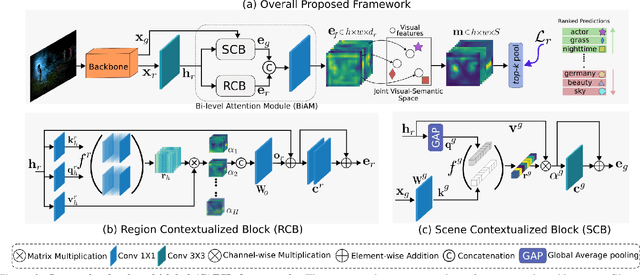
Multi-label zero-shot learning (ZSL) is a more realistic counter-part of standard single-label ZSL since several objects can co-exist in a natural image. However, the occurrence of multiple objects complicates the reasoning and requires region-specific processing of visual features to preserve their contextual cues. We note that the best existing multi-label ZSL method takes a shared approach towards attending to region features with a common set of attention maps for all the classes. Such shared maps lead to diffused attention, which does not discriminatively focus on relevant locations when the number of classes are large. Moreover, mapping spatially-pooled visual features to the class semantics leads to inter-class feature entanglement, thus hampering the classification. Here, we propose an alternate approach towards region-based discriminability-preserving multi-label zero-shot classification. Our approach maintains the spatial resolution to preserve region-level characteristics and utilizes a bi-level attention module (BiAM) to enrich the features by incorporating both region and scene context information. The enriched region-level features are then mapped to the class semantics and only their class predictions are spatially pooled to obtain image-level predictions, thereby keeping the multi-class features disentangled. Our approach sets a new state of the art on two large-scale multi-label zero-shot benchmarks: NUS-WIDE and Open Images. On NUS-WIDE, our approach achieves an absolute gain of 6.9% mAP for ZSL, compared to the best published results.
Learning Anchored Unsigned Distance Functions with Gradient Direction Alignment for Single-view Garment Reconstruction
Aug 19, 2021
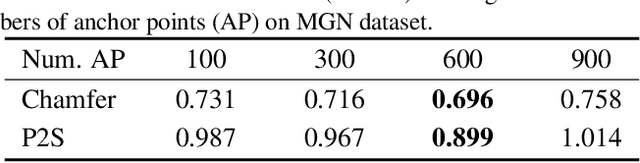
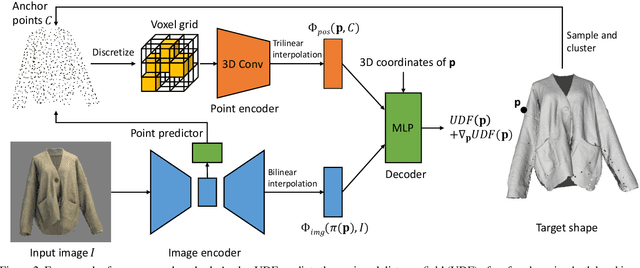
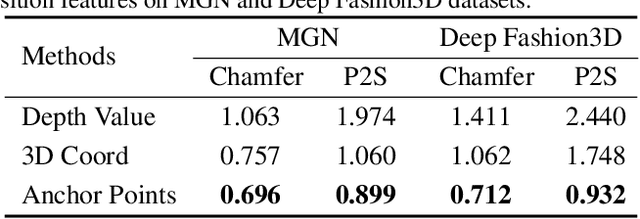
While single-view 3D reconstruction has made significant progress benefiting from deep shape representations in recent years, garment reconstruction is still not solved well due to open surfaces, diverse topologies and complex geometric details. In this paper, we propose a novel learnable Anchored Unsigned Distance Function (AnchorUDF) representation for 3D garment reconstruction from a single image. AnchorUDF represents 3D shapes by predicting unsigned distance fields (UDFs) to enable open garment surface modeling at arbitrary resolution. To capture diverse garment topologies, AnchorUDF not only computes pixel-aligned local image features of query points, but also leverages a set of anchor points located around the surface to enrich 3D position features for query points, which provides stronger 3D space context for the distance function. Furthermore, in order to obtain more accurate point projection direction at inference, we explicitly align the spatial gradient direction of AnchorUDF with the ground-truth direction to the surface during training. Extensive experiments on two public 3D garment datasets, i.e., MGN and Deep Fashion3D, demonstrate that AnchorUDF achieves the state-of-the-art performance on single-view garment reconstruction.
Specificity-preserving RGB-D Saliency Detection
Aug 18, 2021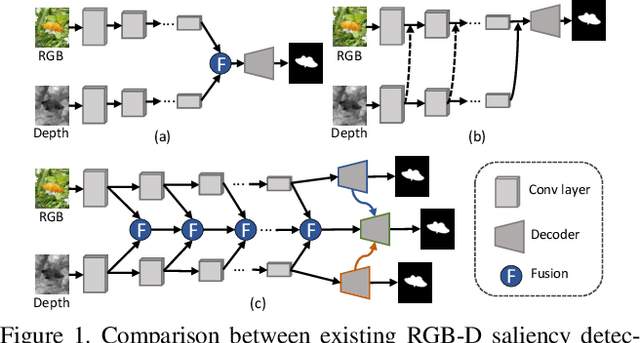
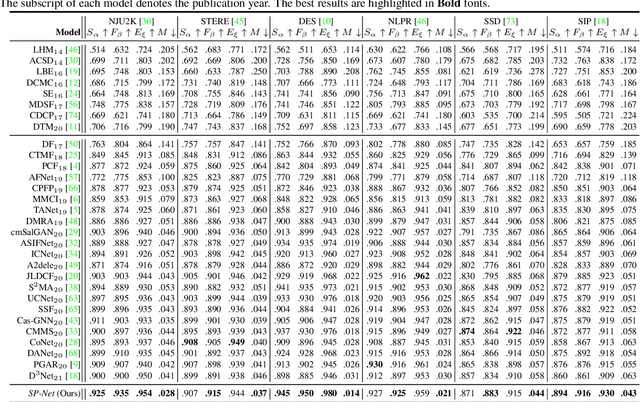
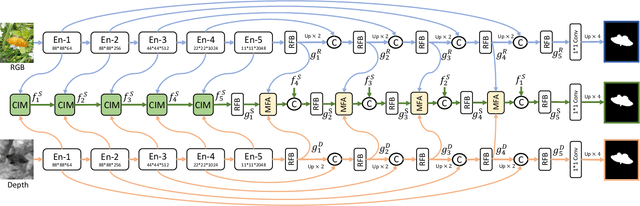
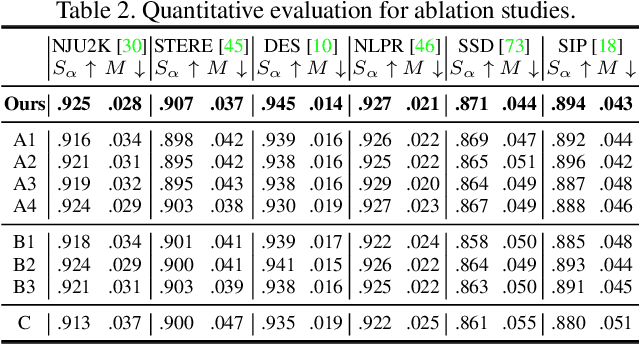
RGB-D saliency detection has attracted increasing attention, due to its effectiveness and the fact that depth cues can now be conveniently captured. Existing works often focus on learning a shared representation through various fusion strategies, with few methods explicitly considering how to preserve modality-specific characteristics. In this paper, taking a new perspective, we propose a specificity-preserving network (SP-Net) for RGB-D saliency detection, which benefits saliency detection performance by exploring both the shared information and modality-specific properties (e.g., specificity). Specifically, two modality-specific networks and a shared learning network are adopted to generate individual and shared saliency maps. A cross-enhanced integration module (CIM) is proposed to fuse cross-modal features in the shared learning network, which are then propagated to the next layer for integrating cross-level information. Besides, we propose a multi-modal feature aggregation (MFA) module to integrate the modality-specific features from each individual decoder into the shared decoder, which can provide rich complementary multi-modal information to boost the saliency detection performance. Further, a skip connection is used to combine hierarchical features between the encoder and decoder layers. Experiments on six benchmark datasets demonstrate that our SP-Net outperforms other state-of-the-art methods. Code is available at: https://github.com/taozh2017/SPNet.
Polyp-PVT: Polyp Segmentation with Pyramid Vision Transformers
Aug 16, 2021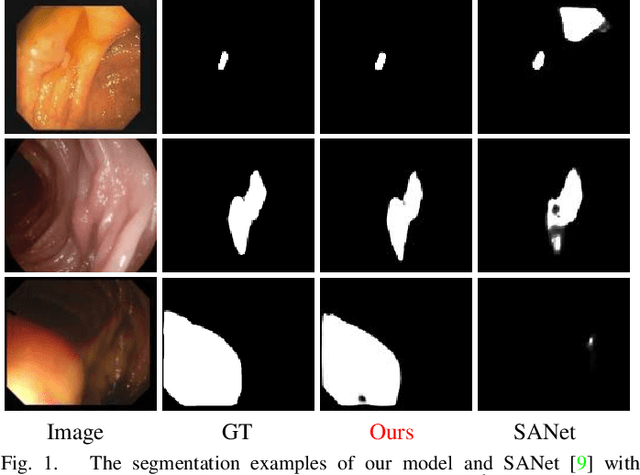
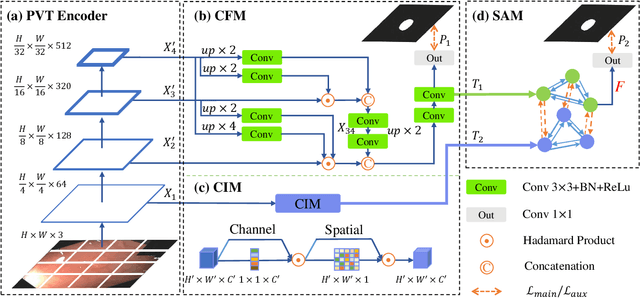
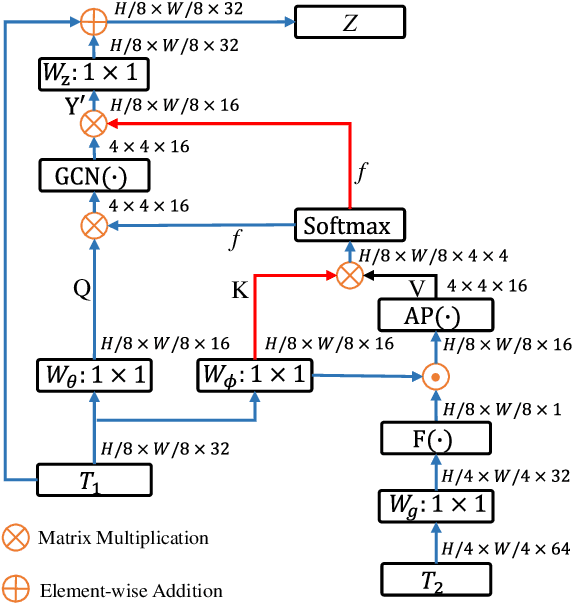
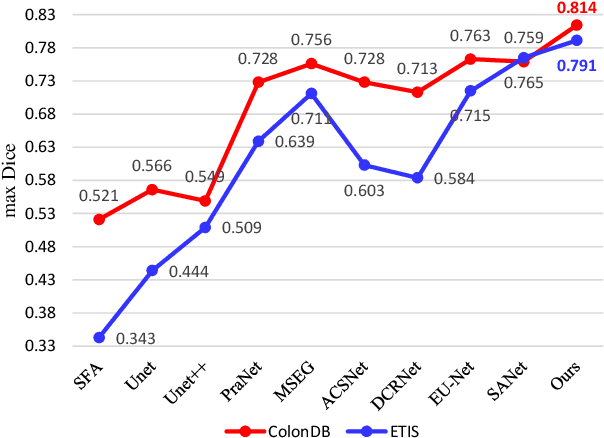
Most polyp segmentation methods use CNNs as their backbone, leading to two key issues when exchanging information between the encoder and decoder: 1) taking into account the differences in contribution between different-level features; and 2) designing effective mechanism for fusing these features. Different from existing CNN-based methods, we adopt a transformer encoder, which learns more powerful and robust representations. In addition, considering the image acquisition influence and elusive properties of polyps, we introduce three novel modules, including a cascaded fusion module (CFM), a camouflage identification module (CIM), a and similarity aggregation module (SAM). Among these, the CFM is used to collect the semantic and location information of polyps from high-level features, while the CIM is applied to capture polyp information disguised in low-level features. With the help of the SAM, we extend the pixel features of the polyp area with high-level semantic position information to the entire polyp area, thereby effectively fusing cross-level features. The proposed model, named \ourmodel, effectively suppresses noises in the features and significantly improves their expressive capabilities. Extensive experiments on five widely adopted datasets show that the proposed model is more robust to various challenging situations (e.g., appearance changes, small objects) than existing methods, and achieves the new state-of-the-art performance. The proposed model is available at https://github.com/DengPingFan/Polyp-PVT .
From Voxel to Point: IoU-guided 3D Object Detection for Point Cloud with Voxel-to-Point Decoder
Aug 08, 2021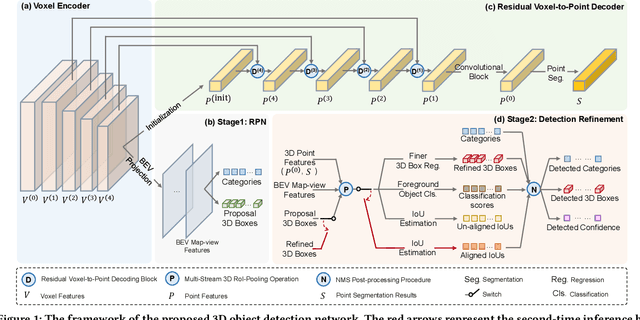
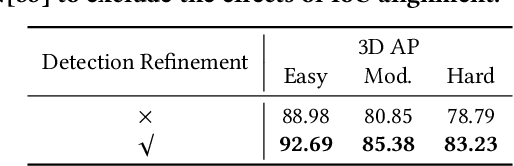
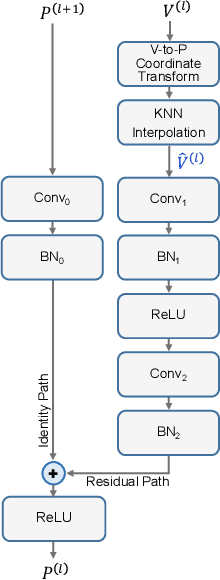
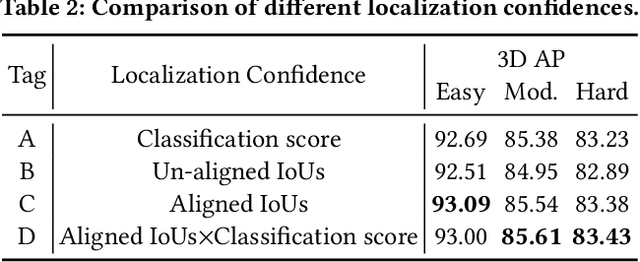
In this paper, we present an Intersection-over-Union (IoU) guided two-stage 3D object detector with a voxel-to-point decoder. To preserve the necessary information from all raw points and maintain the high box recall in voxel based Region Proposal Network (RPN), we propose a residual voxel-to-point decoder to extract the point features in addition to the map-view features from the voxel based RPN. We use a 3D Region of Interest (RoI) alignment to crop and align the features with the proposal boxes for accurately perceiving the object position. The RoI-Aligned features are finally aggregated with the corner geometry embeddings that can provide the potentially missing corner information in the box refinement stage. We propose a simple and efficient method to align the estimated IoUs to the refined proposal boxes as a more relevant localization confidence. The comprehensive experiments on KITTI and Waymo Open Dataset demonstrate that our method achieves significant improvements with novel architectures against the existing methods. The code is available on Github URL\footnote{\url{https://github.com/jialeli1/From-Voxel-to-Point}}.