 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Cross-domain Knowledge Distillation: A Case study on YouTube Music
Mar 30, 2026Knowledge Distillation (KD) has been widely used to improve the quality of latency sensitive models serving live traffic. However, applying KD in production recommender systems with low traffic is challenging: the limited amount of data restricts the teacher model size, and the cost of training a large dedicated teacher may not be justified. Cross-domain KD offers a cost-effective alternative by leveraging a teacher from a data-rich source domain, but introduces unique technical difficulties, as the features, user interfaces, and prediction tasks can significantly differ. We present a case study of using zero-shot cross-domain KD for multi-task ranking models, transferring knowledge from a (100x) large-scale video recommendation platform (YouTube) to a music recommendation application with significantly lower traffic. We share offline and live experiment results and present findings evaluating different KD techniques in this setting across two ranking models on the music app. Our results demonstrate that zero-shot cross-domain KD is a practical and effective approach to improve the performance of ranking models on low traffic surfaces.
Bridging the Gap: Unpacking the Hidden Challenges in Knowledge Distillation for Online Ranking Systems
Aug 26, 2024Knowledge Distillation (KD) is a powerful approach for compressing a large model into a smaller, more efficient model, particularly beneficial for latency-sensitive applications like recommender systems. However, current KD research predominantly focuses on Computer Vision (CV) and NLP tasks, overlooking unique data characteristics and challenges inherent to recommender systems. This paper addresses these overlooked challenges, specifically: (1) mitigating data distribution shifts between teacher and student models, (2) efficiently identifying optimal teacher configurations within time and budgetary constraints, and (3) enabling computationally efficient and rapid sharing of teacher labels to support multiple students. We present a robust KD system developed and rigorously evaluated on multiple large-scale personalized video recommendation systems within Google. Our live experiment results demonstrate significant improvements in student model performance while ensuring consistent and reliable generation of high quality teacher labels from a continuous data stream of data.
Adaptable Precomputation for Random Walker Image Segmentation and Registration
Jul 14, 2016



The random walker (RW) algorithm is used for both image segmentation and registration, and possesses several useful properties that make it popular in medical imaging, such as being globally optimizable, allowing user interaction, and providing uncertainty information. The RW algorithm defines a weighted graph over an image and uses the graph's Laplacian matrix to regularize its solutions. This regularization reduces to solving a large system of equations, which may be excessively time consuming in some applications, such as when interacting with a human user. Techniques have been developed that precompute eigenvectors of a Laplacian offline, after image acquisition but before any analysis, in order speed up the RW algorithm online, when segmentation or registration is being performed. However, precomputation requires certain algorithm parameters be fixed offline, limiting their flexibility. In this paper, we develop techniques to update the precomputed data online when RW parameters are altered. Specifically, we dynamically determine the number of eigenvectors needed for a desired accuracy based on user input, and derive update equations for the eigenvectors when the edge weights or topology of the image graph are changed. We present results demonstrating that our techniques make RW with precomputation much more robust to offline settings while only sacrificing minimal accuracy.
Multi-Region Probabilistic Dice Similarity Coefficient using the Aitchison Distance and Bipartite Graph Matching
Oct 13, 2015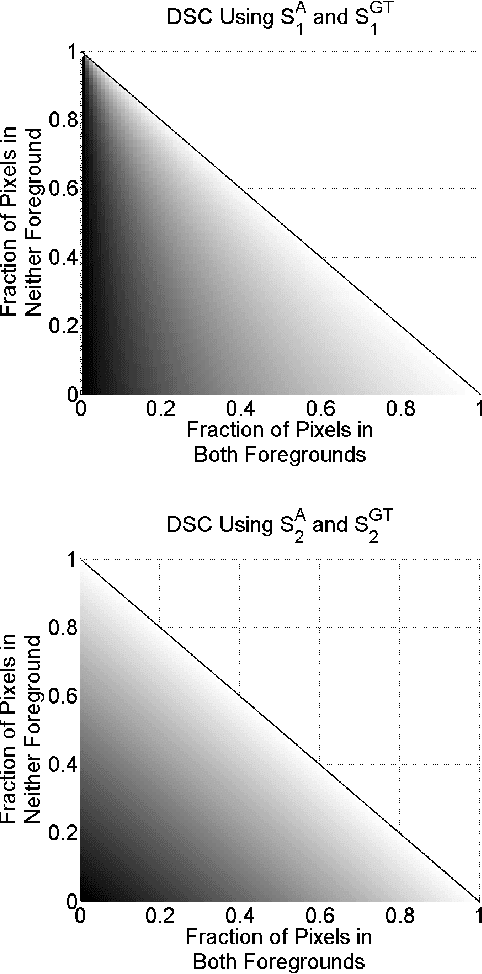
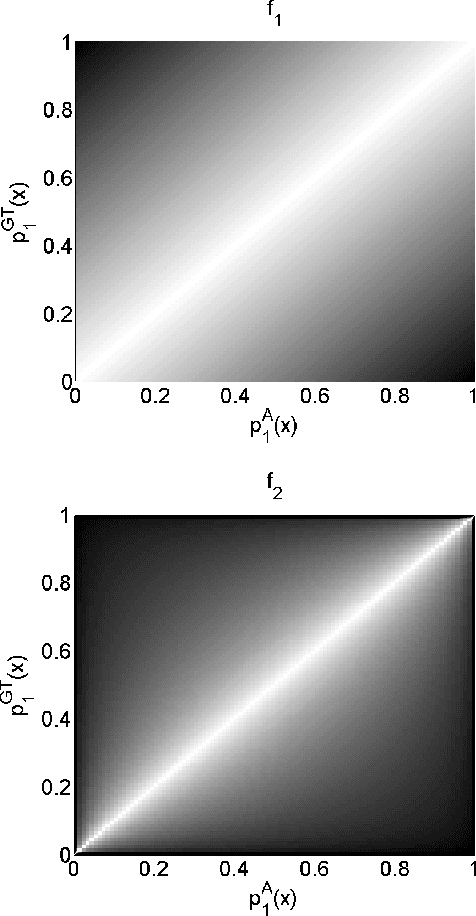
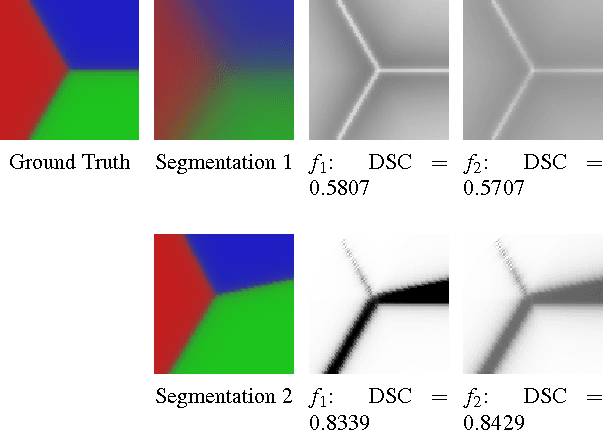
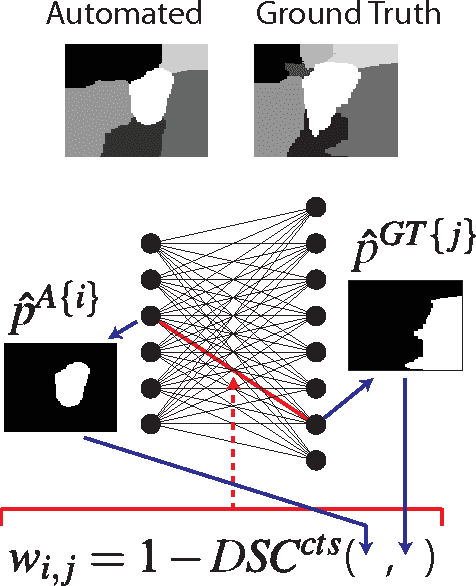
Validation of image segmentation methods is of critical importance. Probabilistic image segmentation is increasingly popular as it captures uncertainty in the results. Image segmentation methods that support multi-region (as opposed to binary) delineation are more favourable as they capture interactions between the different objects in the image. The Dice similarity coefficient (DSC) has been a popular metric for evaluating the accuracy of automated or semi-automated segmentation methods by comparing their results to the ground truth. In this work, we develop an extension of the DSC to multi-region probabilistic segmentations (with unordered labels). We use bipartite graph matching to establish label correspondences and propose two functions that extend the DSC, one based on absolute probability differences and one based on the Aitchison distance. These provide a robust and accurate measure of multi-region probabilistic segmentation accuracy.