 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLamPO: A Lambda Style Policy Optimization for Reasoning Language Models
May 20, 2026Reinforcement learning with verifiable rewards (RLVR) has become an effective paradigm for improving reasoning language models on tasks such as mathematics, coding, and scientific question answering. However, widely used group-relative objectives, such as GRPO, summarize each sampled group with scalar statistics and therefore discard fine-grained relational information among candidate responses. This weakens credit assignment under sparse outcome rewards, especially when multiple generated solutions differ only subtly in reasoning quality. We propose \textbf{LamPO}, a \textbf{Lambda-Style Policy Optimization} method that replaces scalar group advantages with a \emph{Pairwise Decomposed Advantage}. LamPO aggregates pairwise reward gaps within each response group and modulates each comparison by a confidence-aware weight computed from sequence log-probability differences, while retaining the critic-free and clipped-update structure of PPO-style optimization. When reference solutions are available, we further add a lightweight ROUGE-L-based dense auxiliary reward to reduce reward sparsity. Experiments on AIME24, AIME25, MATH-500, and GPQA-Diamond with Qwen3-1.7B, Qwen3-4B, and Phi-4-mini show that LamPO consistently improves over GRPO and recent RLVR variants, with more stable training dynamics and better sample efficiency.
LambdaPO: A Lambda Style Policy Optimization for Reasoning Language Models
May 19, 2026Group Relative Policy Optimization(GRPO) has become a cornerstone of modern reinforcement learning alignment, prized for its efficacy in foregoing an explicit value-critic by leveraging reward normalization across sampled trajectory cohorts. However, the method's reliance on a monolithic statistical baseline, such as the group mean, collapses the relational topology of the trajectory space into a single scalar, thereby erasing the fine-grained preference information essential for navigating complex, rank-sensitive reward landscapes. To address this issue, we introduce a novel framework, Lambda Policy Optimization (LambdaPO), that addresses this information-theoretic bottleneck by re-conceptualizing advantage estimation from a scalar value to a decomposed, pairwise preference structure. Specifically, the advantage for any given trajectory is formulated as the integrated sum of reward differentials against all peers in its cohort, where each pairwise comparison is dynamically attenuated by the policy's own probabilistic confidence in the established preference. To further mitigate the sparsity of binary outcome supervision, we augment the objective with a semantic density reward, derived from the precision-recall alignment between generated reasoning traces and ground-truth solutions. As a result, our method can mine more fine-grained optimization signals from a group of rollouts, guiding the LLM to a better optima. Experimental results across challenging math reasoning and question-answering tasks demonstrates that LambdaPO improves performance compared to the baseline methods.
OpenECAD: An Efficient Visual Language Model for Computer-Aided Design
Jun 14, 2024Computer-aided design (CAD) tools are utilized in the manufacturing industry for modeling everything from cups to spacecraft. These programs are complex to use and typically require years of training and experience to master. Structured and well-constrained 2D sketches and 3D constructions are crucial components of CAD modeling. A well-executed CAD model can be seamlessly integrated into the manufacturing process, thereby enhancing production efficiency. Deep generative models of 3D shapes and 3D object reconstruction models has garnered significant research interest. However, most of these models are represented in discrete forms. Moreover, the few models based on CAD operations often have substantial input restrictions. In this work, we fine-tuned pre-trained models to create OpenECAD (0.55B, 0.89B, and 4.2B), leveraging the visual, logical, coding, and general capabilities of visual language models. OpenECAD can process images of 3D designs as input and generate highly structured 2D sketches and 3D construction commands. These outputs can be directly used with existing CAD tools' APIs to generate project files. To train our network, we created a new CAD dataset. This dataset is based on existing public CAD datasets, with adjustments and augmentations to meet the requirements of ~VLM training.
LEVI: Generalizable Fine-tuning via Layer-wise Ensemble of Different Views
Feb 07, 2024



Fine-tuning is becoming widely used for leveraging the power of pre-trained foundation models in new downstream tasks. While there are many successes of fine-tuning on various tasks, recent studies have observed challenges in the generalization of fine-tuned models to unseen distributions (i.e., out-of-distribution; OOD). To improve OOD generalization, some previous studies identify the limitations of fine-tuning data and regulate fine-tuning to preserve the general representation learned from pre-training data. However, potential limitations in the pre-training data and models are often ignored. In this paper, we contend that overly relying on the pre-trained representation may hinder fine-tuning from learning essential representations for downstream tasks and thus hurt its OOD generalization. It can be especially catastrophic when new tasks are from different (sub)domains compared to pre-training data. To address the issues in both pre-training and fine-tuning data, we propose a novel generalizable fine-tuning method LEVI, where the pre-trained model is adaptively ensembled layer-wise with a small task-specific model, while preserving training and inference efficiencies. By combining two complementing models, LEVI effectively suppresses problematic features in both the fine-tuning data and pre-trained model and preserves useful features for new tasks. Broad experiments with large language and vision models show that LEVI greatly improves fine-tuning generalization via emphasizing different views from fine-tuning data and pre-trained features.
A new semi-supervised inductive transfer learning framework: Co-Transfer
Aug 21, 2021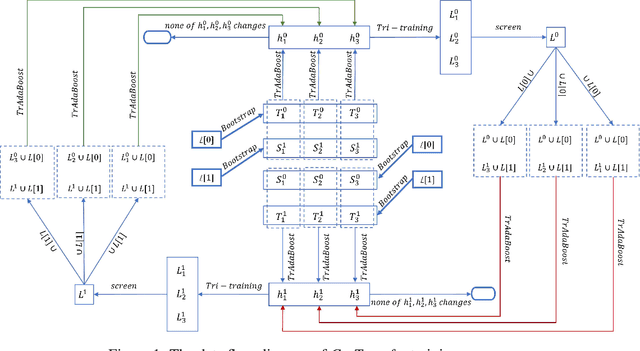
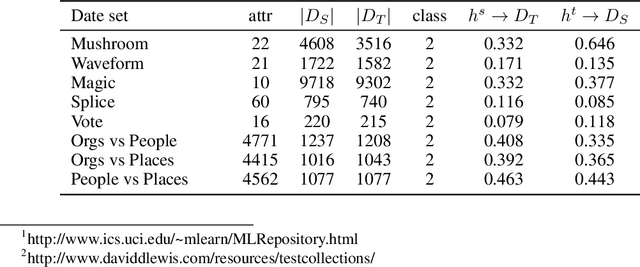
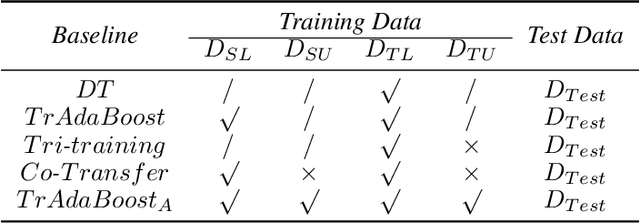
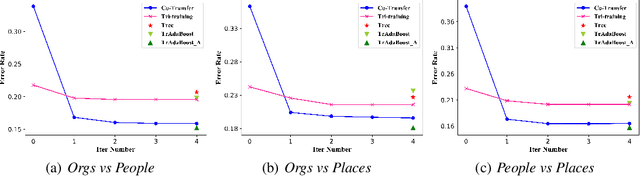
In many practical data mining scenarios, such as network intrusion detection, Twitter spam detection, and computer-aided diagnosis, a source domain that is different from but related to a target domain is very common. In addition, a large amount of unlabeled data is available in both source and target domains, but labeling each of them is difficult, expensive, time-consuming, and sometime unnecessary. Therefore, it is very important and worthwhile to fully explore the labeled and unlabeled data in source and target domains to settle the task in target domain. In this paper, a new semi-supervised inductive transfer learning framework, named Co-Transfer is proposed. Co-Transfer first generates three TrAdaBoost classifiers for transfer learning from the source domain to the target domain, and meanwhile another three TrAdaBoost classifiers are generated for transfer learning from the target domain to the source domain, using bootstraped samples from the original labeled data. In each round of co-transfer, each group of TrAdaBoost classifiers are refined using the carefully labeled data. Finally, the group of TrAdaBoost classifiers learned to transfer from the source domain to the target domain produce the final hypothesis. Experiments results illustrate Co-Transfer can effectively exploit and reuse the labeled and unlabeled data in source and target domains.