 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistically-Attracted Wireframe Parsing: From Supervised to Self-Supervised Learning
Oct 24, 2022This paper presents Holistically-Attracted Wireframe Parsing (HAWP) for 2D images using both fully supervised and self-supervised learning paradigms. At the core is a parsimonious representation that encodes a line segment using a closed-form 4D geometric vector, which enables lifting line segments in wireframe to an end-to-end trainable holistic attraction field that has built-in geometry-awareness, context-awareness and robustness. The proposed HAWP consists of three components: generating line segment and end-point proposal, binding line segment and end-point, and end-point-decoupled lines-of-interest verification. For self-supervised learning, a simulation-to-reality pipeline is exploited in which a HAWP is first trained using synthetic data and then used to ``annotate" wireframes in real images with Homographic Adaptation. With the self-supervised annotations, a HAWP model for real images is trained from scratch. In experiments, the proposed HAWP achieves state-of-the-art performance in both the Wireframe dataset and the YorkUrban dataset in fully-supervised learning. It also demonstrates a significantly better repeatability score than prior arts with much more efficient training in self-supervised learning. Furthermore, the self-supervised HAWP shows great potential for general wireframe parsing without onerous wireframe labels.
Advancing Plain Vision Transformer Towards Remote Sensing Foundation Model
Aug 10, 2022
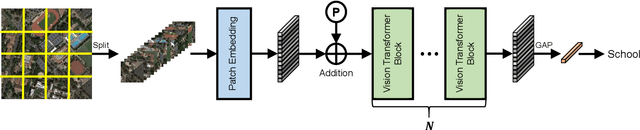
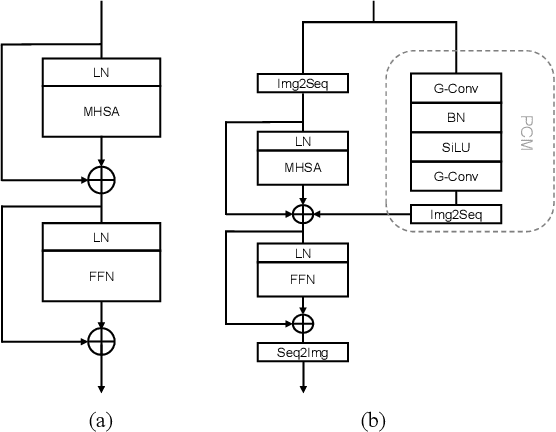
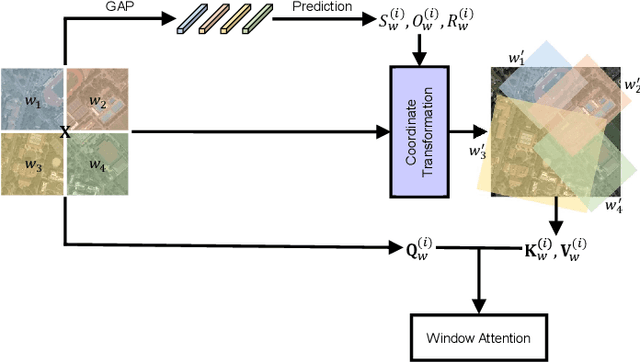
Large-scale vision foundation models have made significant progress in visual tasks on natural images, where the vision transformers are the primary choice for their good scalability and representation ability. However, the utilization of large models in the remote sensing (RS) community remains under-explored where existing models are still at small-scale, which limits the performance. In this paper, we resort to plain vision transformers with about 100 million parameters and make the first attempt to propose large vision models customized for RS tasks and explore how such large models perform. Specifically, to handle the large image size and objects of various orientations in RS images, we propose a new rotated varied-size window attention to substitute the original full attention in transformers, which could significantly reduce the computational cost and memory footprint while learn better object representation by extracting rich context from the generated diverse windows. Experiments on detection tasks demonstrate the superiority of our model over all state-of-the-art models, achieving 81.16% mAP on the DOTA-V1.0 dataset. The results of our models on downstream classification and segmentation tasks also demonstrate competitive performance compared with the existing advanced methods. Further experiments show the advantages of our models on computational complexity and few-shot learning.
HyperNet: Self-Supervised Hyperspectral Spatial-Spectral Feature Understanding Network for Hyperspectral Change Detection
Jul 20, 2022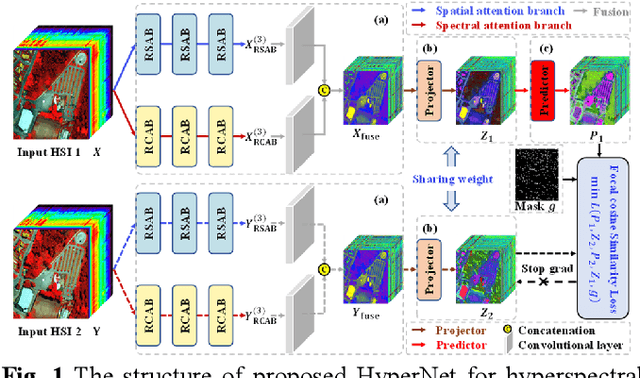
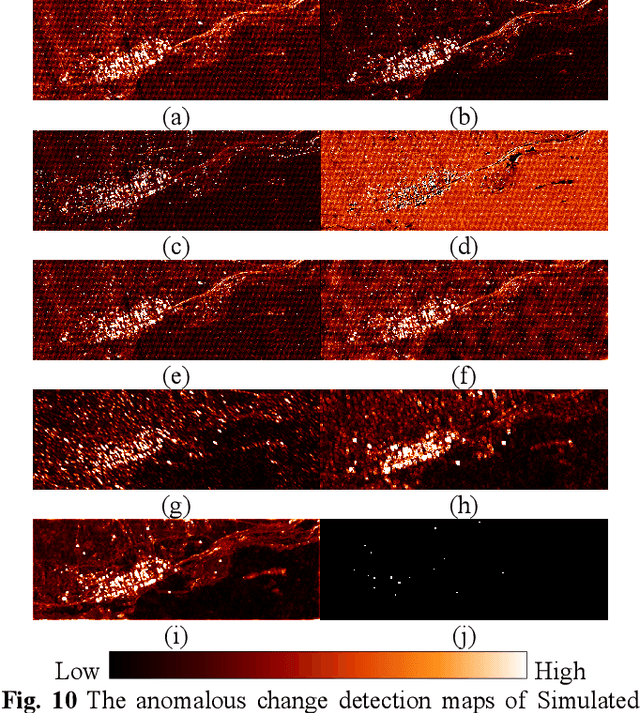
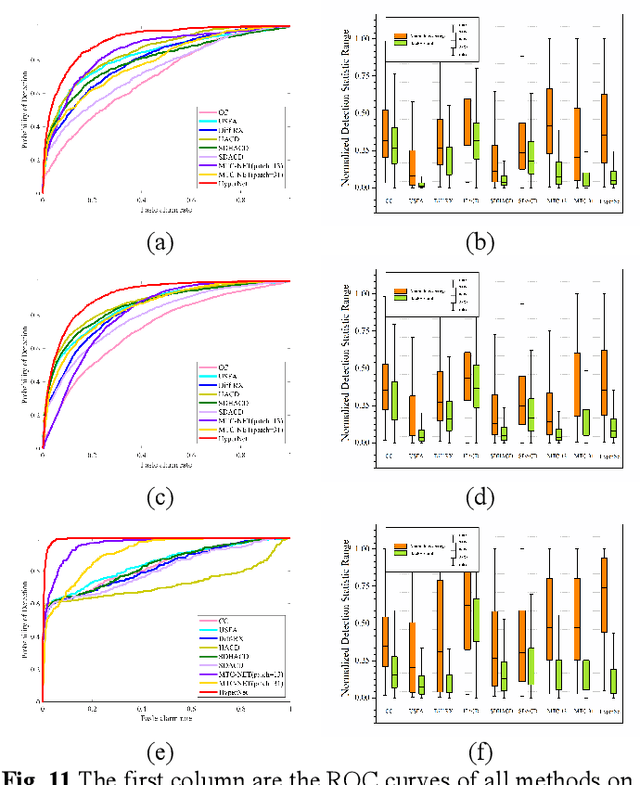
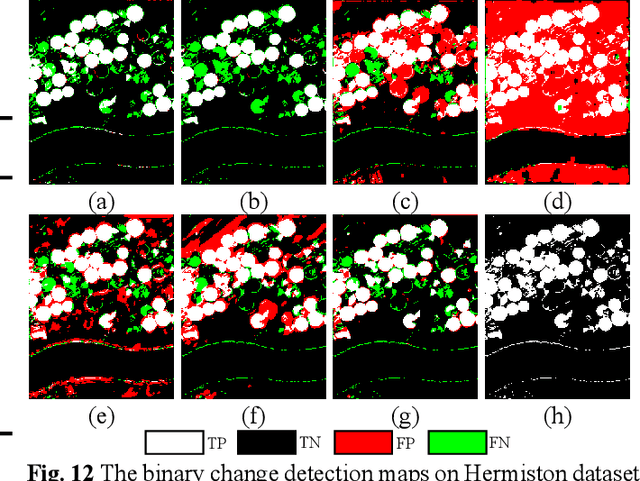
The fast development of self-supervised learning lowers the bar learning feature representation from massive unlabeled data and has triggered a series of research on change detection of remote sensing images. Challenges in adapting self-supervised learning from natural images classification to remote sensing images change detection arise from difference between the two tasks. The learned patch-level feature representations are not satisfying for the pixel-level precise change detection. In this paper, we proposed a novel pixel-level self-supervised hyperspectral spatial-spectral understanding network (HyperNet) to accomplish pixel-wise feature representation for effective hyperspectral change detection. Concretely, not patches but the whole images are fed into the network and the multi-temporal spatial-spectral features are compared pixel by pixel. Instead of processing the two-dimensional imaging space and spectral response dimension in hybrid style, a powerful spatial-spectral attention module is put forward to explore the spatial correlation and discriminative spectral features of multi-temporal hyperspectral images (HSIs), separately. Only the positive samples at the same location of bi-temporal HSIs are created and forced to be aligned, aiming at learning the spectral difference-invariant features. Moreover, a new similarity loss function named focal cosine is proposed to solve the problem of imbalanced easy and hard positive samples comparison, where the weights of those hard samples are enlarged and highlighted to promote the network training. Six hyperspectral datasets have been adopted to test the validity and generalization of proposed HyperNet. The extensive experiments demonstrate the superiority of HyperNet over the state-of-the-art algorithms on downstream hyperspectral change detection tasks.
Fully Convolutional Change Detection Framework with Generative Adversarial Network for Unsupervised, Weakly Supervised and Regional Supervised Change Detection
Jan 16, 2022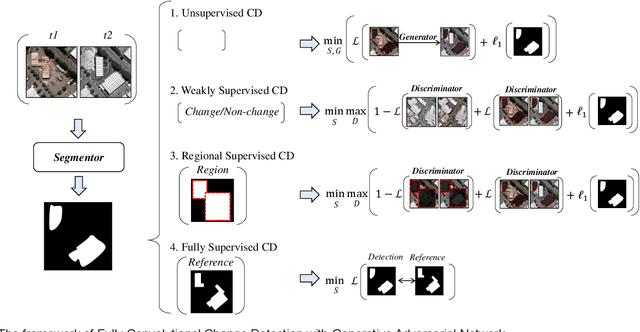
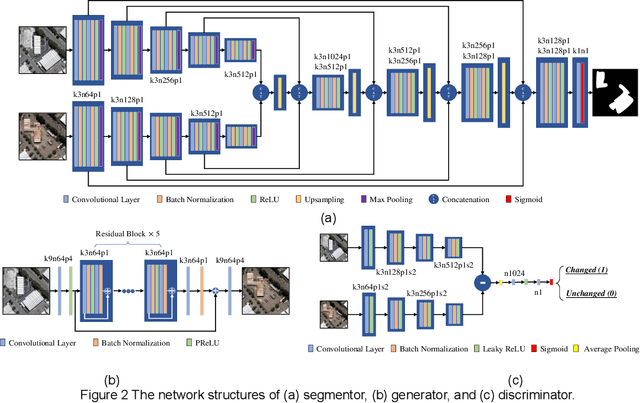

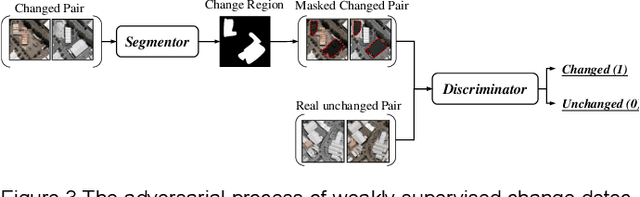
Deep learning for change detection is one of the current hot topics in the field of remote sensing. However, most end-to-end networks are proposed for supervised change detection, and unsupervised change detection models depend on traditional pre-detection methods. Therefore, we proposed a fully convolutional change detection framework with generative adversarial network, to conclude unsupervised, weakly supervised, regional supervised, and fully supervised change detection tasks into one framework. A basic Unet segmentor is used to obtain change detection map, an image-to-image generator is implemented to model the spectral and spatial variation between multi-temporal images, and a discriminator for changed and unchanged is proposed for modeling the semantic changes in weakly and regional supervised change detection task. The iterative optimization of segmentor and generator can build an end-to-end network for unsupervised change detection, the adversarial process between segmentor and discriminator can provide the solutions for weakly and regional supervised change detection, the segmentor itself can be trained for fully supervised task. The experiments indicate the effectiveness of the propsed framework in unsupervised, weakly supervised and regional supervised change detection. This paper provides theorical definitions for unsupervised, weakly supervised and regional supervised change detection tasks, and shows great potentials in exploring end-to-end network for remote sensing change detection.
Aerial Scene Parsing: From Tile-level Scene Classification to Pixel-wise Semantic Labeling
Jan 09, 2022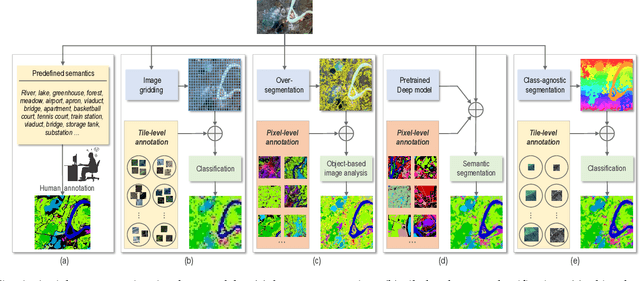
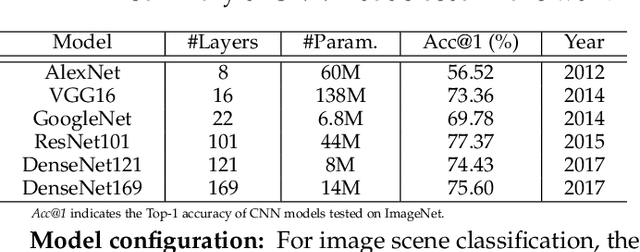
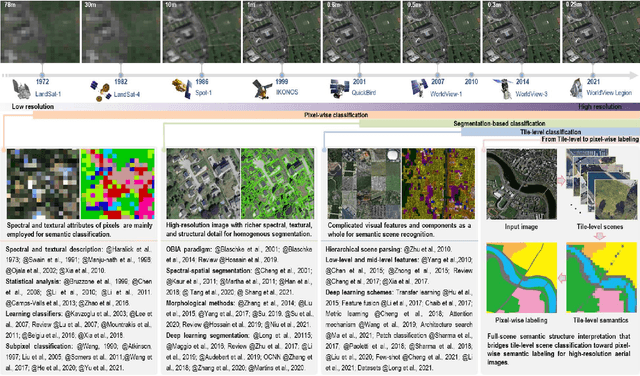

Given an aerial image, aerial scene parsing (ASP) targets to interpret the semantic structure of the image content, e.g., by assigning a semantic label to every pixel of the image. With the popularization of data-driven methods, the past decades have witnessed promising progress on ASP by approaching the problem with the schemes of tile-level scene classification or segmentation-based image analysis, when using high-resolution aerial images. However, the former scheme often produces results with tile-wise boundaries, while the latter one needs to handle the complex modeling process from pixels to semantics, which often requires large-scale and well-annotated image samples with pixel-wise semantic labels. In this paper, we address these issues in ASP, with perspectives from tile-level scene classification to pixel-wise semantic labeling. Specifically, we first revisit aerial image interpretation by a literature review. We then present a large-scale scene classification dataset that contains one million aerial images termed Million-AID. With the presented dataset, we also report benchmarking experiments using classical convolutional neural networks (CNNs). Finally, we perform ASP by unifying the tile-level scene classification and object-based image analysis to achieve pixel-wise semantic labeling. Intensive experiments show that Million-AID is a challenging yet useful dataset, which can serve as a benchmark for evaluating newly developed algorithms. When transferring knowledge from Million-AID, fine-tuning CNN models pretrained on Million-AID perform consistently better than those pretrained ImageNet for aerial scene classification. Moreover, our designed hierarchical multi-task learning method achieves the state-of-the-art pixel-wise classification on the challenging GID, bridging the tile-level scene classification toward pixel-wise semantic labeling for aerial image interpretation.
Self-Ensembling GAN for Cross-Domain Semantic Segmentation
Dec 15, 2021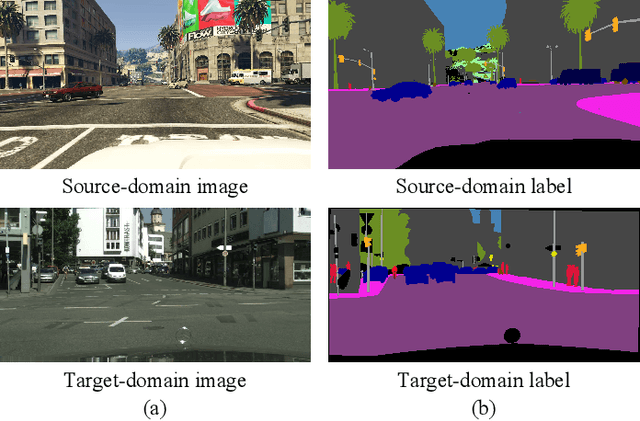
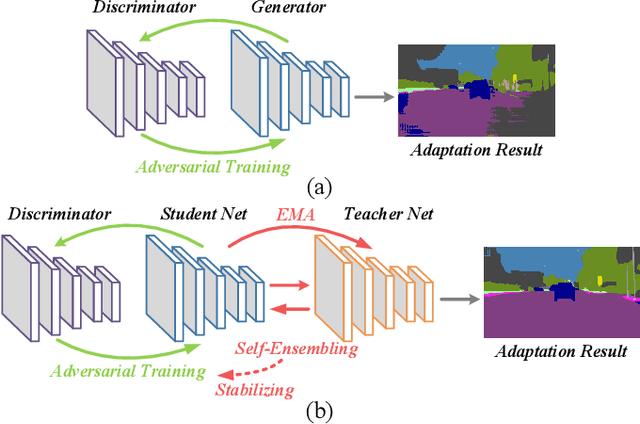
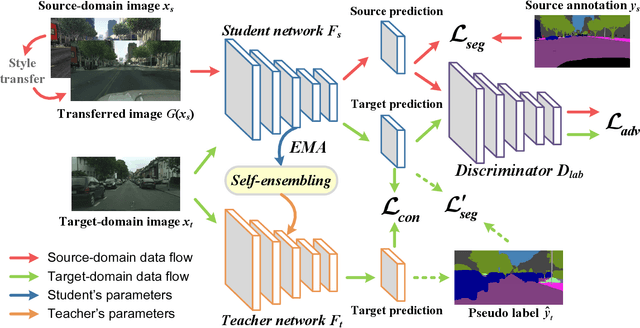
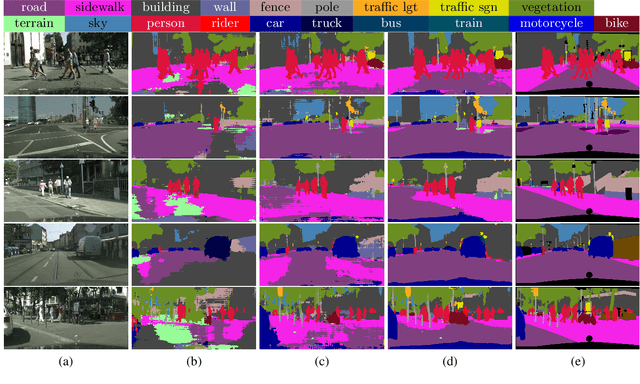
Deep neural networks (DNNs) have greatly contributed to the performance gains in semantic segmentation. Nevertheless, training DNNs generally requires large amounts of pixel-level labeled data, which is expensive and time-consuming to collect in practice. To mitigate the annotation burden, this paper proposes a self-ensembling generative adversarial network (SE-GAN) exploiting cross-domain data for semantic segmentation. In SE-GAN, a teacher network and a student network constitute a self-ensembling model for generating semantic segmentation maps, which together with a discriminator, forms a GAN. Despite its simplicity, we find SE-GAN can significantly boost the performance of adversarial training and enhance the stability of the model, the latter of which is a common barrier shared by most adversarial training-based methods. We theoretically analyze SE-GAN and provide an $\mathcal O(1/\sqrt{N})$ generalization bound ($N$ is the training sample size), which suggests controlling the discriminator's hypothesis complexity to enhance the generalizability. Accordingly, we choose a simple network as the discriminator. Extensive and systematic experiments in two standard settings demonstrate that the proposed method significantly outperforms current state-of-the-art approaches. The source code of our model will be available soon.
Binary Change Guided Hyperspectral Multiclass Change Detection
Dec 11, 2021

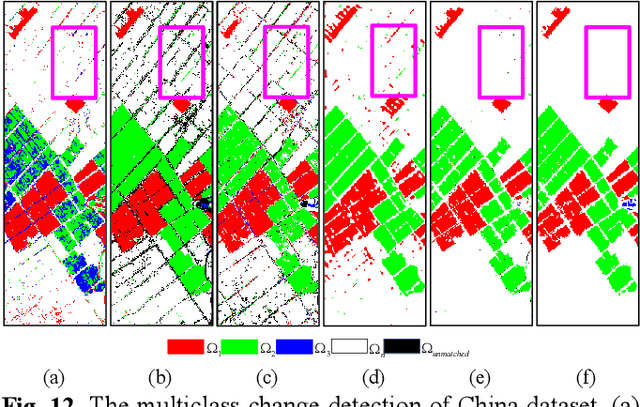
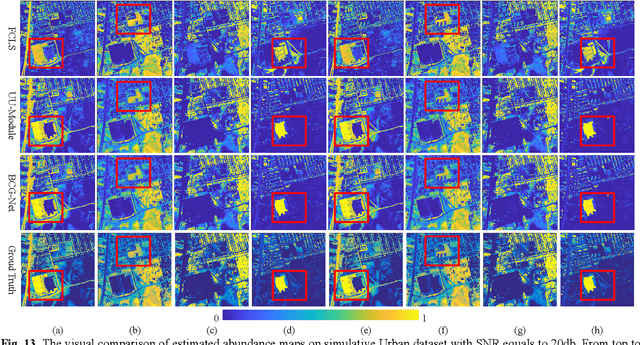
Characterized by tremendous spectral information, hyperspectral image is able to detect subtle changes and discriminate various change classes for change detection. The recent research works dominated by hyperspectral binary change detection, however, cannot provide fine change classes information. And most methods incorporating spectral unmixing for hyperspectral multiclass change detection (HMCD), yet suffer from the neglection of temporal correlation and error accumulation. In this study, we proposed an unsupervised Binary Change Guided hyperspectral multiclass change detection Network (BCG-Net) for HMCD, which aims at boosting the multiclass change detection result and unmixing result with the mature binary change detection approaches. In BCG-Net, a novel partial-siamese united-unmixing module is designed for multi-temporal spectral unmixing, and a groundbreaking temporal correlation constraint directed by the pseudo-labels of binary change detection result is developed to guide the unmixing process from the perspective of change detection, encouraging the abundance of the unchanged pixels more coherent and that of the changed pixels more accurate. Moreover, an innovative binary change detection rule is put forward to deal with the problem that traditional rule is susceptible to numerical values. The iterative optimization of the spectral unmixing process and the change detection process is proposed to eliminate the accumulated errors and bias from unmixing result to change detection result. The experimental results demonstrate that our proposed BCG-Net could achieve comparative or even outstanding performance of multiclass change detection among the state-of-the-art approaches and gain better spectral unmixing results at the same time.
Hidden Path Selection Network for Semantic Segmentation of Remote Sensing Images
Dec 09, 2021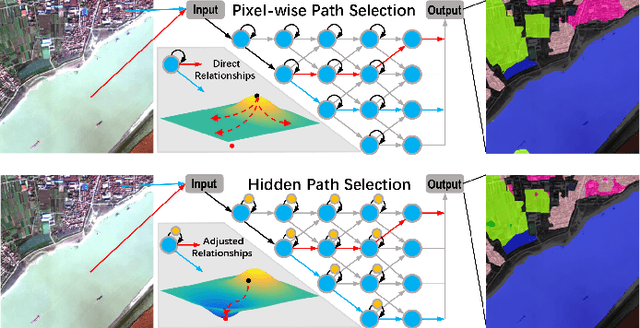
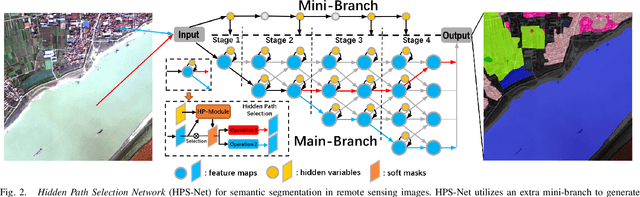
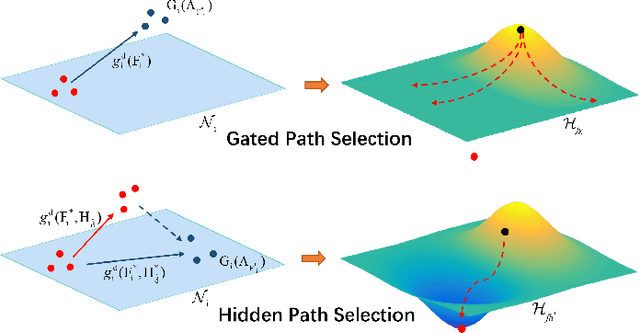
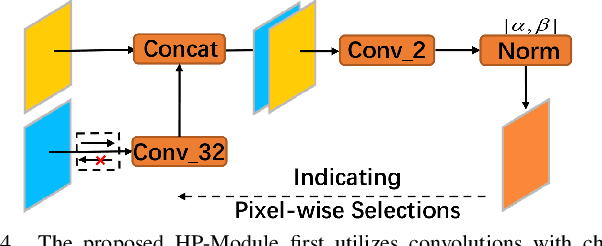
Targeting at depicting land covers with pixel-wise semantic categories, semantic segmentation in remote sensing images needs to portray diverse distributions over vast geographical locations, which is difficult to be achieved by the homogeneous pixel-wise forward paths in the architectures of existing deep models. Although several algorithms have been designed to select pixel-wise adaptive forward paths for natural image analysis, it still lacks theoretical supports on how to obtain optimal selections. In this paper, we provide mathematical analyses in terms of the parameter optimization, which guides us to design a method called Hidden Path Selection Network (HPS-Net). With the help of hidden variables derived from an extra mini-branch, HPS-Net is able to tackle the inherent problem about inaccessible global optimums by adjusting the direct relationships between feature maps and pixel-wise path selections in existing algorithms, which we call hidden path selection. For the better training and evaluation, we further refine and expand the 5-class Gaofen Image Dataset (GID-5) to a new one with 15 land-cover categories, i.e., GID-15. The experimental results on both GID-5 and GID-15 demonstrate that the proposed modules can stably improve the performance of different deep structures, which validates the proposed mathematical analyses.
An Integrated Framework for the Heterogeneous Spatio-Spectral-Temporal Fusion of Remote Sensing Images
Sep 01, 2021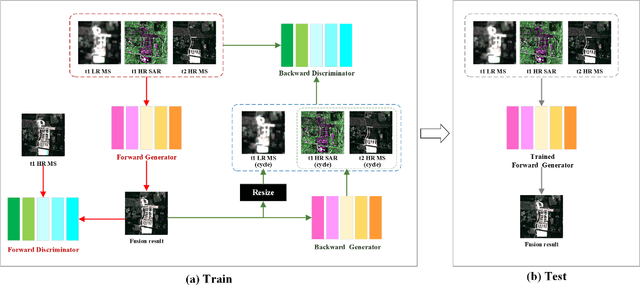
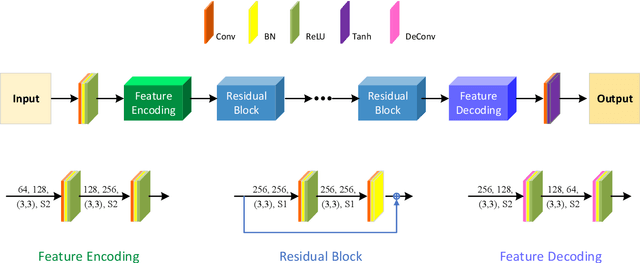
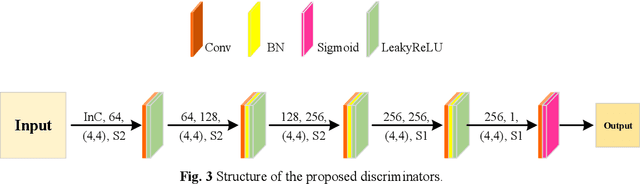
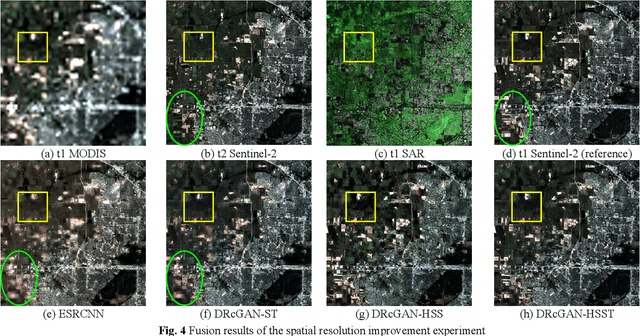
Image fusion technology is widely used to fuse the complementary information between multi-source remote sensing images. Inspired by the frontier of deep learning, this paper first proposes a heterogeneous-integrated framework based on a novel deep residual cycle GAN. The proposed network consists of a forward fusion part and a backward degeneration feedback part. The forward part generates the desired fusion result from the various observations; the backward degeneration feedback part considers the imaging degradation process and regenerates the observations inversely from the fusion result. The proposed network can effectively fuse not only the homogeneous but also the heterogeneous information. In addition, for the first time, a heterogeneous-integrated fusion framework is proposed to simultaneously merge the complementary heterogeneous spatial, spectral and temporal information of multi-source heterogeneous observations. The proposed heterogeneous-integrated framework also provides a uniform mode that can complete various fusion tasks, including heterogeneous spatio-spectral fusion, spatio-temporal fusion, and heterogeneous spatio-spectral-temporal fusion. Experiments are conducted for two challenging scenarios of land cover changes and thick cloud coverage. Images from many remote sensing satellites, including MODIS, Landsat-8, Sentinel-1, and Sentinel-2, are utilized in the experiments. Both qualitative and quantitative evaluations confirm the effectiveness of the proposed method.
LUAI Challenge 2021 on Learning to Understand Aerial Images
Aug 30, 2021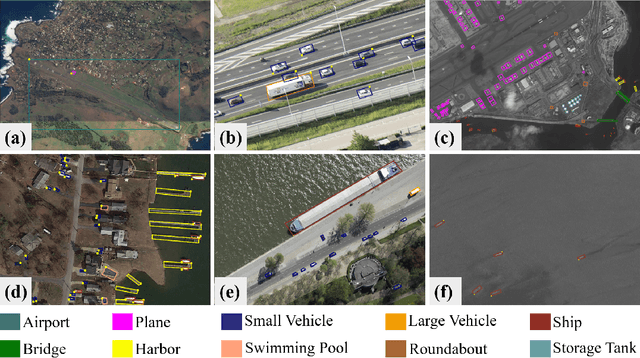

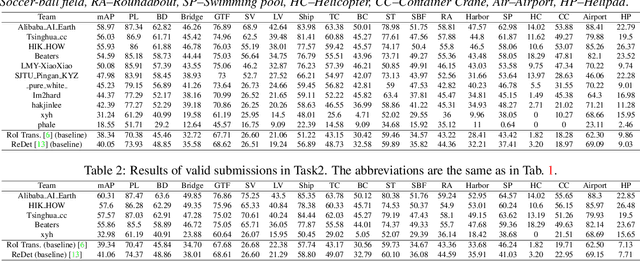
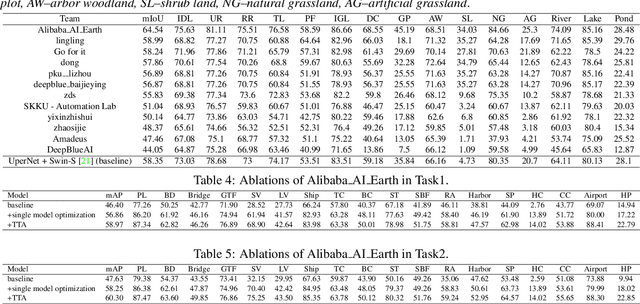
This report summarizes the results of Learning to Understand Aerial Images (LUAI) 2021 challenge held on ICCV 2021, which focuses on object detection and semantic segmentation in aerial images. Using DOTA-v2.0 and GID-15 datasets, this challenge proposes three tasks for oriented object detection, horizontal object detection, and semantic segmentation of common categories in aerial images. This challenge received a total of 146 registrations on the three tasks. Through the challenge, we hope to draw attention from a wide range of communities and call for more efforts on the problems of learning to understand aerial images.