 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate and Robust Pulmonary Nodule Detection by 3D Feature Pyramid Network with Self-supervised Feature Learning
Jul 25, 2019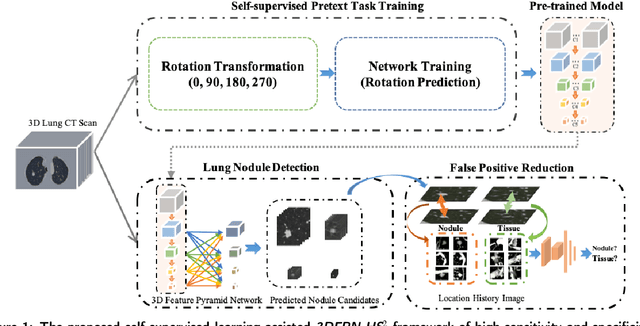

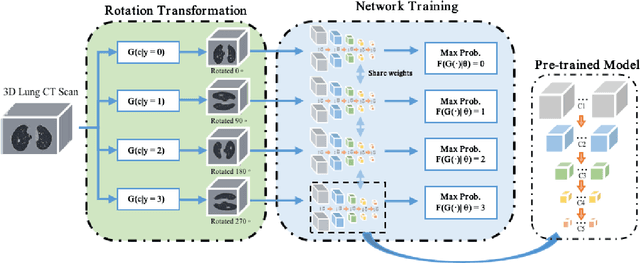

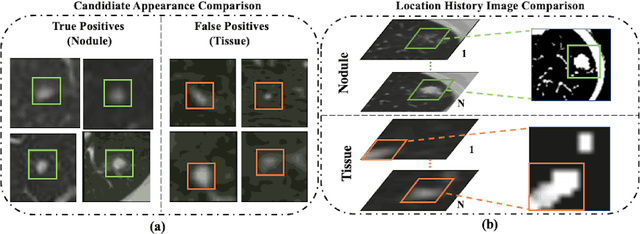
Accurate detection of pulmonary nodules with high sensitivity and specificity is essential for automatic lung cancer diagnosis from CT scans. Although many deep learning-based algorithms make great progress for improving the accuracy of nodule detection, the high false positive rate is still a challenging problem which limits the automatic diagnosis in routine clinical practice. Moreover, the CT scans collected from multiple manufacturers may affect the robustness of Computer-aided diagnosis (CAD) due to the differences in intensity scales and machine noises. In this paper, we propose a novel self-supervised learning assisted pulmonary nodule detection framework based on a 3D Feature Pyramid Network (3DFPN) to improve the sensitivity of nodule detection by employing multi-scale features to increase the resolution of nodules, as well as a parallel top-down path to transit the high-level semantic features to complement low-level general features. Furthermore, a High Sensitivity and Specificity (HS2) network is introduced to eliminate the false positive nodule candidates by tracking the appearance changes in continuous CT slices of each nodule candidate on Location History Images (LHI). In addition, in order to improve the performance consistency of the proposed framework across data captured by different CT scanners without using additional annotations, an effective self-supervised learning schema is applied to learn spatiotemporal features of CT scans from large-scale unlabeled data. The performance and robustness of our method are evaluated on several publicly available datasets with significant performance improvements. The proposed framework is able to accurately detect pulmonary nodules with high sensitivity and specificity and achieves 90.6% sensitivity with 1/8 false positive per scan which outperforms the state-of-the-art results 15.8% on LUNA16 dataset.
3DFPN-HS$^2$: 3D Feature Pyramid Network Based High Sensitivity and Specificity Pulmonary Nodule Detection
Jun 11, 2019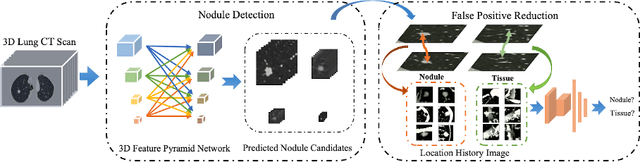


Accurate detection of pulmonary nodules with high sensitivity and specificity is essential for automatic lung cancer diagnosis from CT scans. Although many deep learning-based algorithms make great progress for improving the accuracy of nodule detection, the high false positive rate is still a challenging problem which limited the automatic diagnosis in routine clinical practice. In this paper, we propose a novel pulmonary nodule detection framework based on a 3D Feature Pyramid Network (3DFPN) to improve the sensitivity of nodule detection by employing multi-scale features to increase the resolution of nodules, as well as a parallel top-down path to transit the high-level semantic features to complement low-level general features. Furthermore, a High Sensitivity and Specificity (HS$^2$) network is introduced to eliminate the falsely detected nodule candidates by tracking the appearance changes in continuous CT slices of each nodule candidate. The proposed framework is evaluated on the public Lung Nodule Analysis (LUNA16) challenge dataset. Our method is able to accurately detect lung nodules at high sensitivity and specificity and achieves $90.4\%$ sensitivity with 1/8 false positive per scan which outperforms the state-of-the-art results $15.6\%$.
Automatic adaptation of object detectors to new domains using self-training
Apr 15, 2019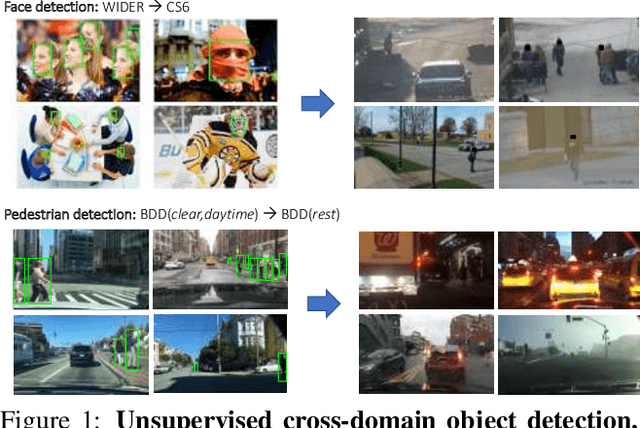

This work addresses the unsupervised adaptation of an existing object detector to a new target domain. We assume that a large number of unlabeled videos from this domain are readily available. We automatically obtain labels on the target data by using high-confidence detections from the existing detector, augmented with hard (misclassified) examples acquired by exploiting temporal cues using a tracker. These automatically-obtained labels are then used for re-training the original model. A modified knowledge distillation loss is proposed, and we investigate several ways of assigning soft-labels to the training examples from the target domain. Our approach is empirically evaluated on challenging face and pedestrian detection tasks: a face detector trained on WIDER-Face, which consists of high-quality images crawled from the web, is adapted to a large-scale surveillance data set; a pedestrian detector trained on clear, daytime images from the BDD-100K driving data set is adapted to all other scenarios such as rainy, foggy, night-time. Our results demonstrate the usefulness of incorporating hard examples obtained from tracking, the advantage of using soft-labels via distillation loss versus hard-labels, and show promising performance as a simple method for unsupervised domain adaptation of object detectors, with minimal dependence on hyper-parameters.
Learning Deterministic Policy with Target for Power Control in Wireless Networks
Feb 21, 2019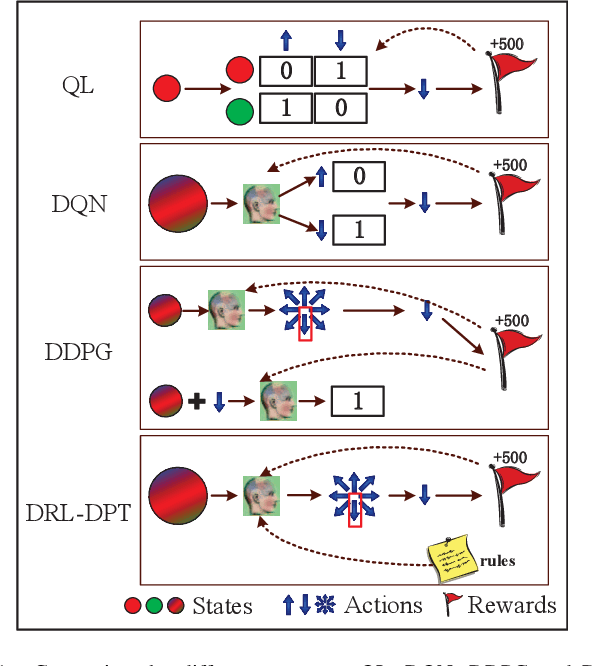
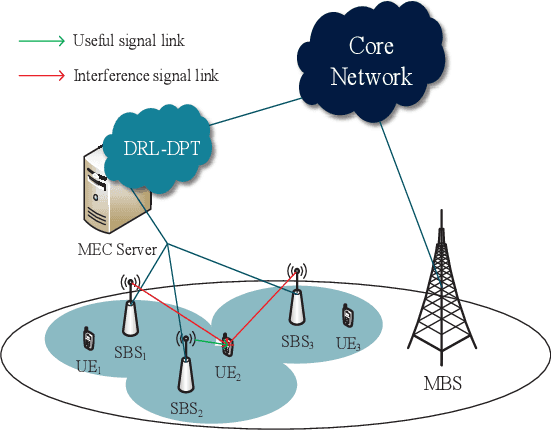
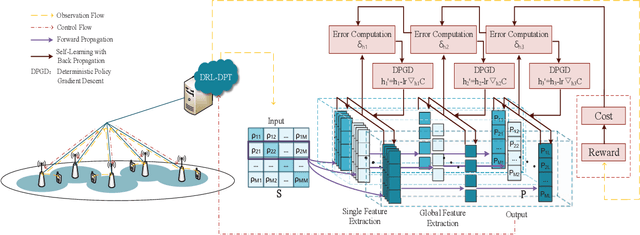
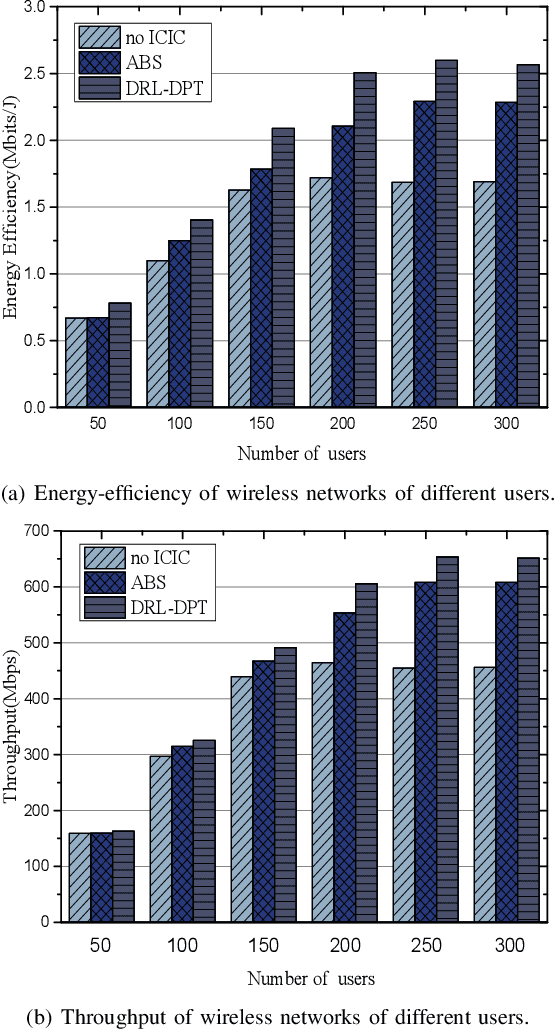
Inter-Cell Interference Coordination (ICIC) is a promising way to improve energy efficiency in wireless networks, especially where small base stations are densely deployed. However, traditional optimization based ICIC schemes suffer from severe performance degradation with complex interference pattern. To address this issue, we propose a Deep Reinforcement Learning with Deterministic Policy and Target (DRL-DPT) framework for ICIC in wireless networks. DRL-DPT overcomes the main obstacles in applying reinforcement learning and deep learning in wireless networks, i.e. continuous state space, continuous action space and convergence. Firstly, a Deep Neural Network (DNN) is involved as the actor to obtain deterministic power control actions in continuous space. Then, to guarantee the convergence, an online training process is presented, which makes use of a dedicated reward function as the target rule and a policy gradient descent algorithm to adjust DNN weights. Experimental results show that the proposed DRL-DPT framework consistently outperforms existing schemes in terms of energy efficiency and throughput under different wireless interference scenarios. More specifically, it improves up to 15% of energy efficiency with faster convergence rate.
Matrix Factorization on GPUs with Memory Optimization and Approximate Computing
Aug 11, 2018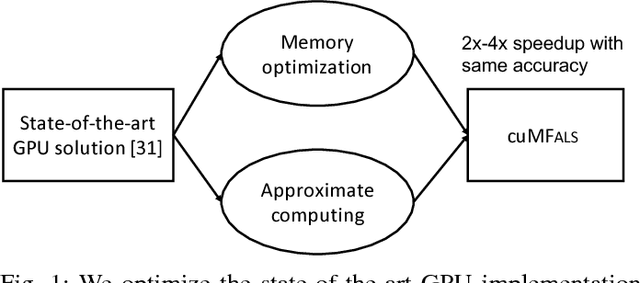
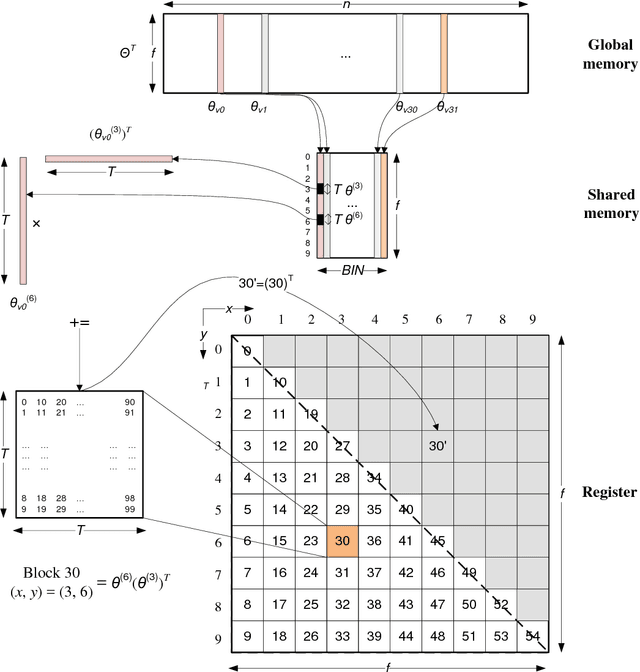
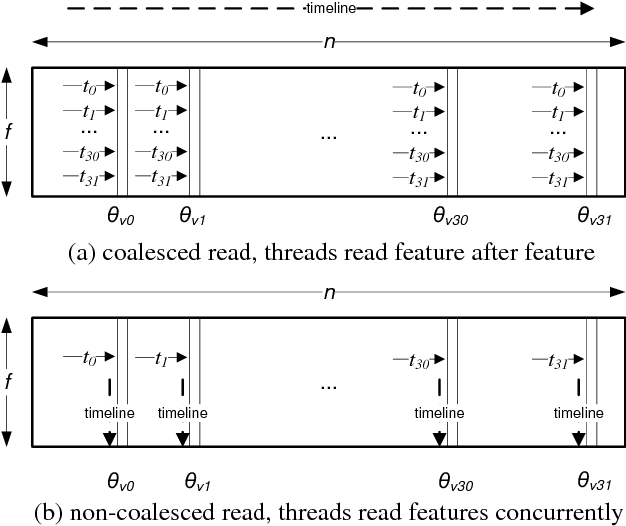
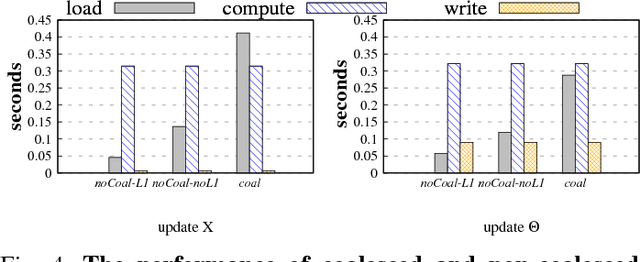
Matrix factorization (MF) discovers latent features from observations, which has shown great promises in the fields of collaborative filtering, data compression, feature extraction, word embedding, etc. While many problem-specific optimization techniques have been proposed, alternating least square (ALS) remains popular due to its general applicability e.g. easy to handle positive-unlabeled inputs, fast convergence and parallelization capability. Current MF implementations are either optimized for a single machine or with a need of a large computer cluster but still are insufficient. This is because a single machine provides limited compute power for large-scale data while multiple machines suffer from the network communication bottleneck. To address the aforementioned challenge, accelerating ALS on graphics processing units (GPUs) is a promising direction. We propose the novel approach in enhancing the MF efficiency via both memory optimization and approximate computing. The former exploits GPU memory hierarchy to increase data reuse, while the later reduces unnecessary computing without hurting the convergence of learning algorithms. Extensive experiments on large-scale datasets show that our solution not only outperforms the competing CPU solutions by a large margin but also has a 2x-4x performance gain compared to the state-of-the-art GPU solutions. Our implementations are open-sourced and publicly available.
Focal Visual-Text Attention for Visual Question Answering
Jun 05, 2018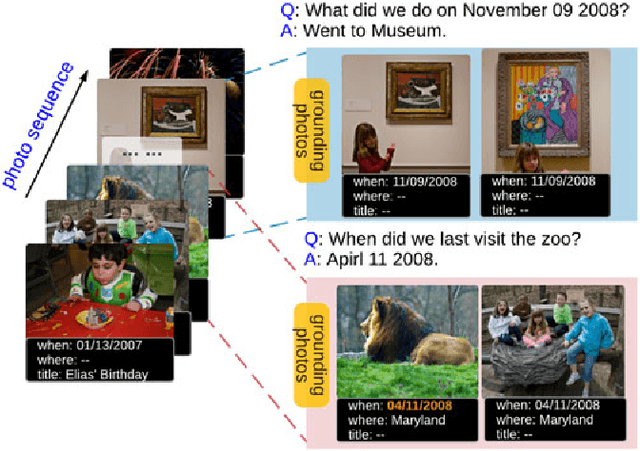
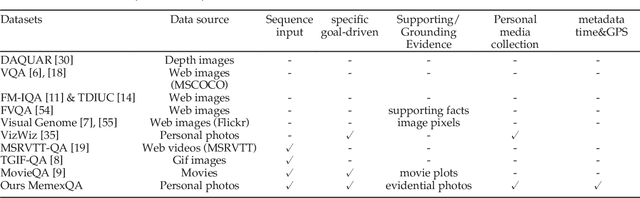
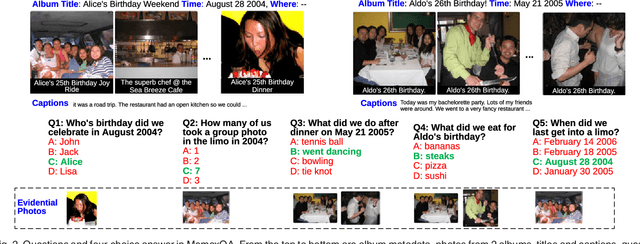

Recent insights on language and vision with neural networks have been successfully applied to simple single-image visual question answering. However, to tackle real-life question answering problems on multimedia collections such as personal photos, we have to look at whole collections with sequences of photos or videos. When answering questions from a large collection, a natural problem is to identify snippets to support the answer. In this paper, we describe a novel neural network called Focal Visual-Text Attention network (FVTA) for collective reasoning in visual question answering, where both visual and text sequence information such as images and text metadata are presented. FVTA introduces an end-to-end approach that makes use of a hierarchical process to dynamically determine what media and what time to focus on in the sequential data to answer the question. FVTA can not only answer the questions well but also provides the justifications which the system results are based upon to get the answers. FVTA achieves state-of-the-art performance on the MemexQA dataset and competitive results on the MovieQA dataset.
Learning Object Detectors from Scratch with Gated Recurrent Feature Pyramids
Dec 04, 2017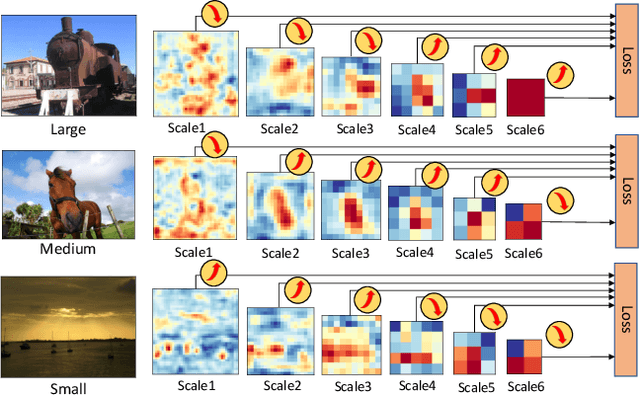

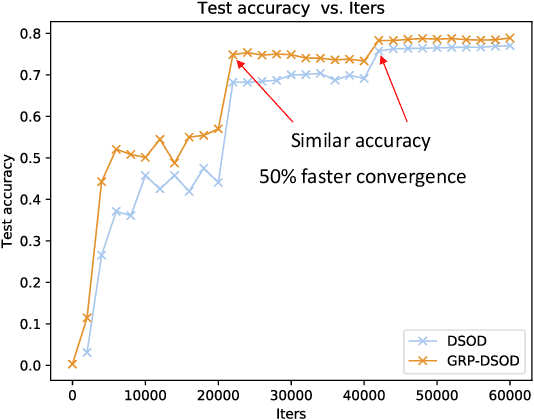
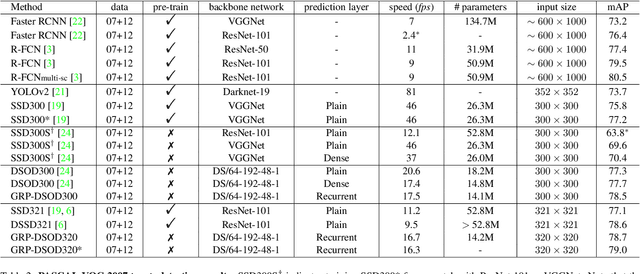
In this paper, we propose gated recurrent feature pyramid for the problem of learning object detection from scratch. Our approach is motivated by the recent work of deeply supervised object detector (DSOD), but explores new network architecture that dynamically adjusts the supervision intensities of intermediate layers for various scales in object detection. The benefits of the proposed method are two-fold: First, we propose a recurrent feature-pyramid structure to squeeze rich spatial and semantic features into a single prediction layer that further reduces the number of parameters to learn (DSOD need learn 1/2, but our method need only 1/3). Thus our new model is more fit for learning from scratch, and can converge faster than DSOD (using only 50% of iterations). Second, we introduce a novel gate-controlled prediction strategy to adaptively enhance or attenuate supervision at different scales based on the input object size. As a result, our model is more suitable for detecting small objects. To the best of our knowledge, our study is the best performed model of learning object detection from scratch. Our method in the PASCAL VOC 2012 comp3 leaderboard (which compares object detectors that are trained only with PASCAL VOC data) demonstrates a significant performance jump, from previous 64% to our 77% (VOC 07++12) and 72.5% (VOC 12). We also evaluate the performance of our method on PASCAL VOC 2007, 2012 and MS COCO datasets, and find that the accuracy of our learning from scratch method can even beat a lot of the state-of-the-art detection methods which use pre-trained models from ImageNet. Code is available at: https://github.com/szq0214/GRP-DSOD .
Lip2AudSpec: Speech reconstruction from silent lip movements video
Oct 26, 2017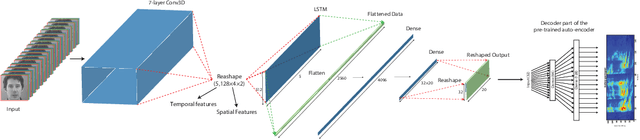
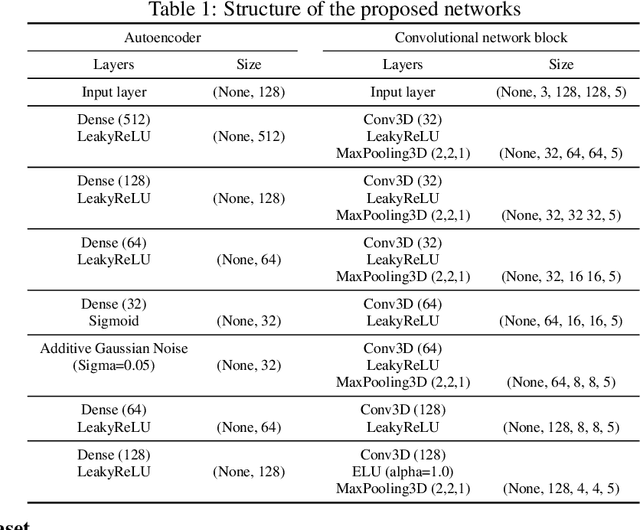

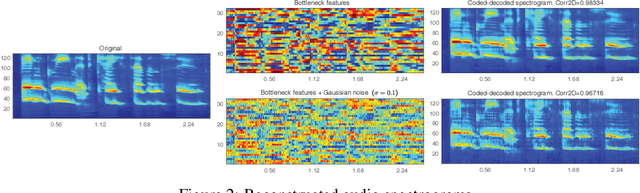
In this study, we propose a deep neural network for reconstructing intelligible speech from silent lip movement videos. We use auditory spectrogram as spectral representation of speech and its corresponding sound generation method resulting in a more natural sounding reconstructed speech. Our proposed network consists of an autoencoder to extract bottleneck features from the auditory spectrogram which is then used as target to our main lip reading network comprising of CNN, LSTM and fully connected layers. Our experiments show that the autoencoder is able to reconstruct the original auditory spectrogram with a 98% correlation and also improves the quality of reconstructed speech from the main lip reading network. Our model, trained jointly on different speakers is able to extract individual speaker characteristics and gives promising results of reconstructing intelligible speech with superior word recognition accuracy.
MemexQA: Visual Memex Question Answering
Aug 04, 2017


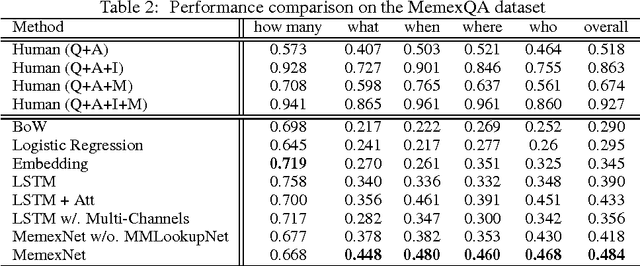
This paper proposes a new task, MemexQA: given a collection of photos or videos from a user, the goal is to automatically answer questions that help users recover their memory about events captured in the collection. Towards solving the task, we 1) present the MemexQA dataset, a large, realistic multimodal dataset consisting of real personal photos and crowd-sourced questions/answers, 2) propose MemexNet, a unified, end-to-end trainable network architecture for image, text and video question answering. Experimental results on the MemexQA dataset demonstrate that MemexNet outperforms strong baselines and yields the state-of-the-art on this novel and challenging task. The promising results on TextQA and VideoQA suggest MemexNet's efficacy and scalability across various QA tasks.
Image Based Appraisal of Real Estate Properties
Jul 27, 2017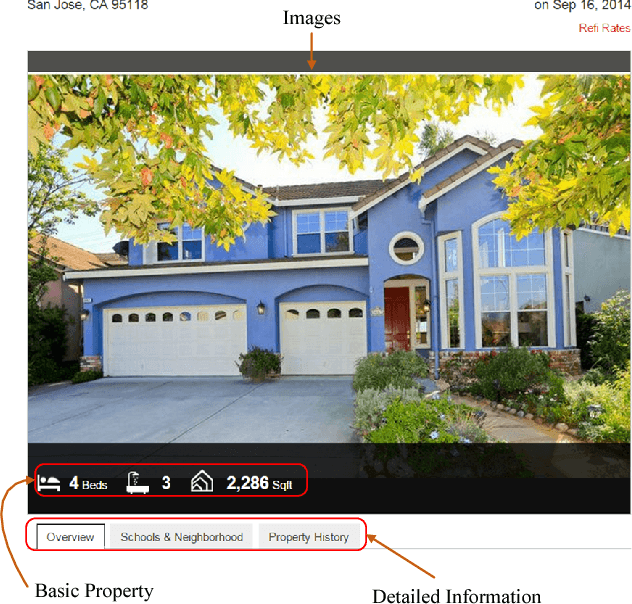
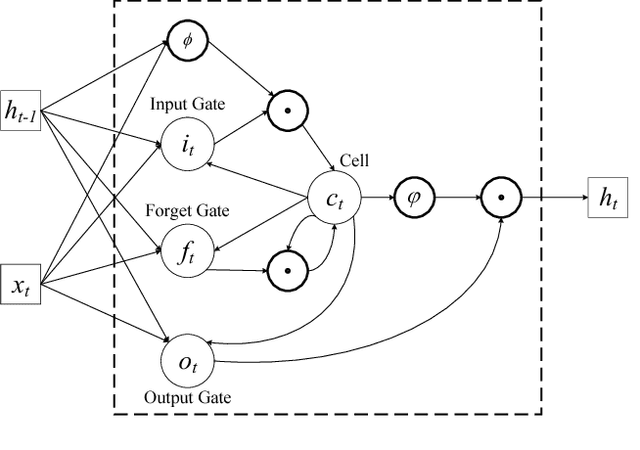
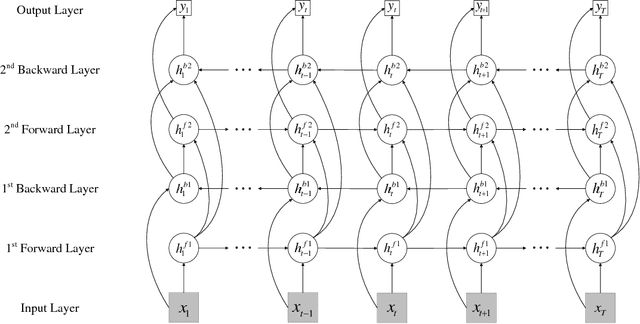
Real estate appraisal, which is the process of estimating the price for real estate properties, is crucial for both buys and sellers as the basis for negotiation and transaction. Traditionally, the repeat sales model has been widely adopted to estimate real estate price. However, it depends the design and calculation of a complex economic related index, which is challenging to estimate accurately. Today, real estate brokers provide easy access to detailed online information on real estate properties to their clients. We are interested in estimating the real estate price from these large amounts of easily accessed data. In particular, we analyze the prediction power of online house pictures, which is one of the key factors for online users to make a potential visiting decision. The development of robust computer vision algorithms makes the analysis of visual content possible. In this work, we employ a Recurrent Neural Network (RNN) to predict real estate price using the state-of-the-art visual features. The experimental results indicate that our model outperforms several of other state-of-the-art baseline algorithms in terms of both mean absolute error (MAE) and mean absolute percentage error (MAPE).