 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety-Critical Scenario Generation Via Reinforcement Learning Based Editing
Jun 25, 2023



Generating safety-critical scenarios is essential for testing and verifying the safety of autonomous vehicles. Traditional optimization techniques suffer from the curse of dimensionality and limit the search space to fixed parameter spaces. To address these challenges, we propose a deep reinforcement learning approach that generates scenarios by sequential editing, such as adding new agents or modifying the trajectories of the existing agents. Our framework employs a reward function consisting of both risk and plausibility objectives. The plausibility objective leverages generative models, such as a variational autoencoder, to learn the likelihood of the generated parameters from the training datasets; It penalizes the generation of unlikely scenarios. Our approach overcomes the dimensionality challenge and explores a wide range of safety-critical scenarios. Our evaluation demonstrates that the proposed method generates safety-critical scenarios of higher quality compared with previous approaches.
NeuS-PIR: Learning Relightable Neural Surface using Pre-Integrated Rendering
Jun 13, 2023Recent advances in neural implicit fields enables rapidly reconstructing 3D geometry from multi-view images. Beyond that, recovering physical properties such as material and illumination is essential for enabling more applications. This paper presents a new method that effectively learns relightable neural surface using pre-intergrated rendering, which simultaneously learns geometry, material and illumination within the neural implicit field. The key insight of our work is that these properties are closely related to each other, and optimizing them in a collaborative manner would lead to consistent improvements. Specifically, we propose NeuS-PIR, a method that factorizes the radiance field into a spatially varying material field and a differentiable environment cubemap, and jointly learns it with geometry represented by neural surface. Our experiments demonstrate that the proposed method outperforms the state-of-the-art method in both synthetic and real datasets.
Learning Excavation of Rigid Objects with Offline Reinforcement Learning
Mar 29, 2023



Autonomous excavation is a challenging task. The unknown contact dynamics between the excavator bucket and the terrain could easily result in large contact forces and jamming problems during excavation. Traditional model-based methods struggle to handle such problems due to complex dynamic modeling. In this paper, we formulate the excavation skills with three novel manipulation primitives. We propose to learn the manipulation primitives with offline reinforcement learning (RL) to avoid large amounts of online robot interactions. The proposed method can learn efficient penetration skills from sub-optimal demonstrations, which contain sub-trajectories that can be ``stitched" together to formulate an optimal trajectory without causing jamming. We evaluate the proposed method with extensive experiments on excavating a variety of rigid objects and demonstrate that the learned policy outperforms the demonstrations. We also show that the learned policy can quickly adapt to unseen and challenging fragmented rocks with online fine-tuning.
GOATS: Goal Sampling Adaptation for Scooping with Curriculum Reinforcement Learning
Mar 09, 2023



In this work, we first formulate the problem of goal-conditioned robotic water scooping with reinforcement learning. This task is challenging due to the complex dynamics of fluid and multi-modal goal-reaching. The policy is required to achieve both position goals and water amount goals, which leads to a large convoluted goal state space. To address these challenges, we introduce Goal Sampling Adaptation for Scooping (GOATS), a curriculum reinforcement learning method that can learn an effective and generalizable policy for robot scooping tasks. Specifically, we use a goal-factorized reward formulation and interpolate position goal distributions and amount goal distributions to create curriculum through the learning process. As a result, our proposed method can outperform the baselines in simulation and achieves 5.46% and 8.71% amount errors on bowl scooping and bucket scooping tasks, respectively, under 1000 variations of initial water states in the tank and a large goal state space. Besides being effective in simulation environments, our method can efficiently generalize to noisy real-robot water-scooping scenarios with different physical configurations and unseen settings, demonstrating superior efficacy and generalizability. The videos of this work are available on our project page: https://sites.google.com/view/goatscooping.
LiDAR-CS Dataset: LiDAR Point Cloud Dataset with Cross-Sensors for 3D Object Detection
Jan 29, 2023LiDAR devices are widely used in autonomous driving scenarios and researches on 3D point cloud achieve remarkable progress over the past years. However, deep learning-based methods heavily rely on the annotation data and often face the domain generalization problem. Unlike 2D images whose domains are usually related to the texture information, the feature extracted from the 3D point cloud is affected by the distribution of the points. Due to the lack of a 3D domain adaptation benchmark, the common practice is to train the model on one benchmark (e.g, Waymo) and evaluate it on another dataset (e.g. KITTI). However, in this setting, there are two types of domain gaps, the scenarios domain, and sensors domain, making the evaluation and analysis complicated and difficult. To handle this situation, we propose LiDAR Dataset with Cross-Sensors (LiDAR-CS Dataset), which contains large-scale annotated LiDAR point cloud under 6 groups of different sensors but with same corresponding scenarios, captured from hybrid realistic LiDAR simulator. As far as we know, LiDAR-CS Dataset is the first dataset focused on the sensor (e.g., the points distribution) domain gaps for 3D object detection in real traffic. Furthermore, we evaluate and analyze the performance with several baseline detectors on the LiDAR-CS benchmark and show its applications.
Multi-Sem Fusion: Multimodal Semantic Fusion for 3D Object Detection
Dec 10, 2022



LiDAR-based 3D Object detectors have achieved impressive performances in many benchmarks, however, multisensors fusion-based techniques are promising to further improve the results. PointPainting, as a recently proposed framework, can add the semantic information from the 2D image into the 3D LiDAR point by the painting operation to boost the detection performance. However, due to the limited resolution of 2D feature maps, severe boundary-blurring effect happens during re-projection of 2D semantic segmentation into the 3D point clouds. To well handle this limitation, a general multimodal fusion framework MSF has been proposed to fuse the semantic information from both the 2D image and 3D points scene parsing results. Specifically, MSF includes three main modules. First, SOTA off-the-shelf 2D/3D semantic segmentation approaches are employed to generate the parsing results for 2D images and 3D point clouds. The 2D semantic information is further re-projected into the 3D point clouds with calibrated parameters. To handle the misalignment between the 2D and 3D parsing results, an AAF module is proposed to fuse them by learning an adaptive fusion score. Then the point cloud with the fused semantic label is sent to the following 3D object detectors. Furthermore, we propose a DFF module to aggregate deep features in different levels to boost the final detection performance. The effectiveness of the framework has been verified on two public large-scale 3D object detection benchmarks by comparing with different baselines. The experimental results show that the proposed fusion strategies can significantly improve the detection performance compared to the methods using only point clouds and the methods using only 2D semantic information. Most importantly, the proposed approach significantly outperforms other approaches and sets new SOTA results on the nuScenes testing benchmark.
VINet: Visual and Inertial-based Terrain Classification and Adaptive Navigation over Unknown Terrain
Sep 26, 2022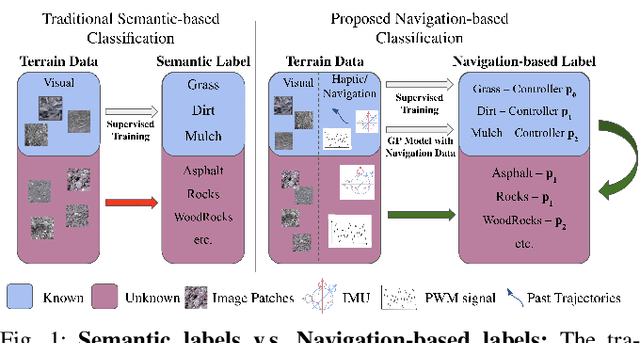
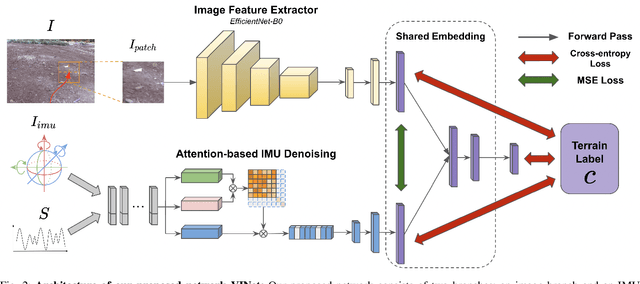
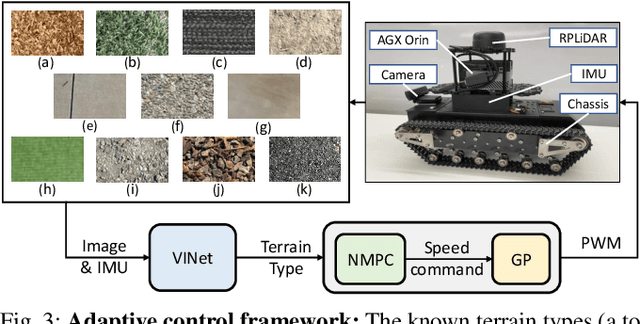
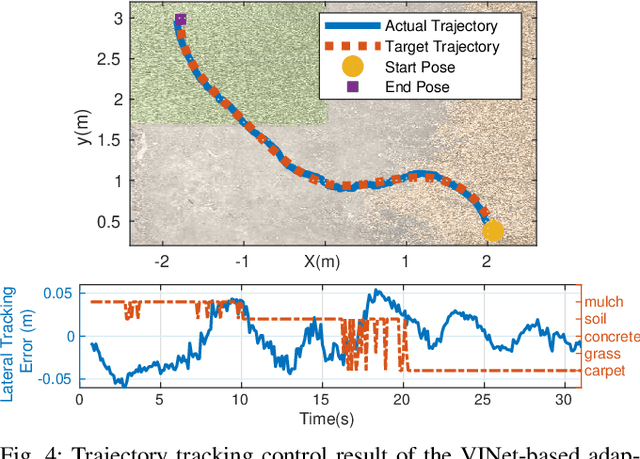
We present a visual and inertial-based terrain classification network (VINet) for robotic navigation over different traversable surfaces. We use a novel navigation-based labeling scheme for terrain classification and generalization on unknown surfaces. Our proposed perception method and adaptive control framework can make predictions according to terrain navigation properties and lead to better performance on both terrain classification and navigation control on known and unknown surfaces. Our VINet can achieve 98.37% in terms of accuracy under supervised setting on known terrains and improve the accuracy by 8.51% on unknown terrains compared to previous methods. We deploy VINet on a mobile tracked robot for trajectory following and navigation on different terrains, and we demonstrate an improvement of 10.3% compared to a baseline controller in terms of RMSE.
NeRF-Loc: Transformer-Based Object Localization Within Neural Radiance Fields
Sep 24, 2022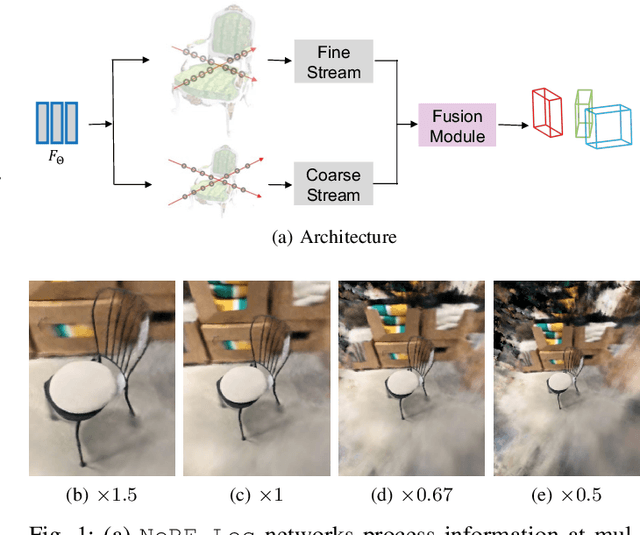
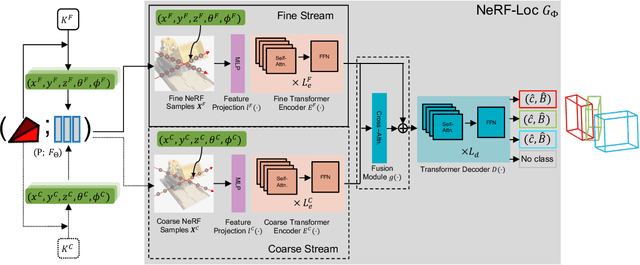
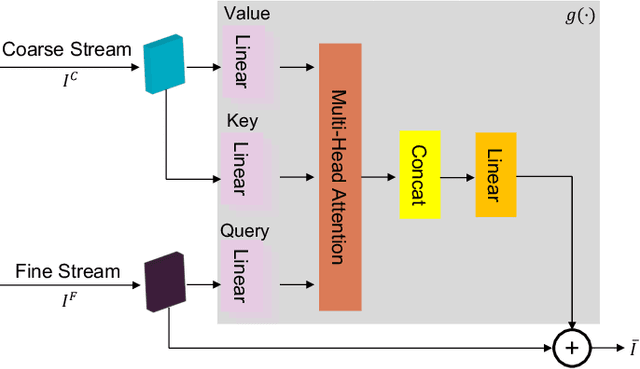
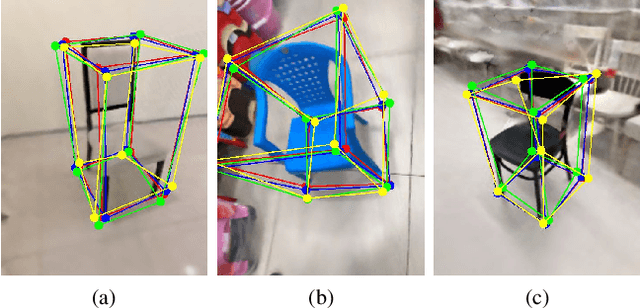
Neural Radiance Fields (NeRFs) have been successfully used for scene representation. Recent works have also developed robotic navigation and manipulation systems using NeRF-based environment representations. As object localization is the foundation for many robotic applications, to further unleash the potential of NeRFs in robotic systems, we study object localization within a NeRF scene. We propose a transformer-based framework NeRF-Loc to extract 3D bounding boxes of objects in NeRF scenes. NeRF-Loc takes a pre-trained NeRF model and camera view as input, and produces labeled 3D bounding boxes of objects as output. Concretely, we design a pair of paralleled transformer encoder branches, namely the coarse stream and the fine stream, to encode both the context and details of target objects. The encoded features are then fused together with attention layers to alleviate ambiguities for accurate object localization. We have compared our method with the conventional transformer-based method and our method achieves better performance. In addition, we also present the first NeRF samples-based object localization benchmark NeRFLocBench.
Semi-supervised 3D Object Detection with Proficient Teachers
Jul 26, 2022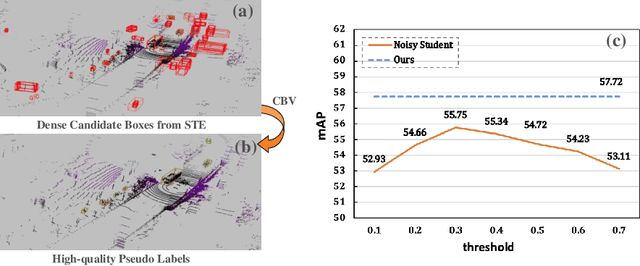

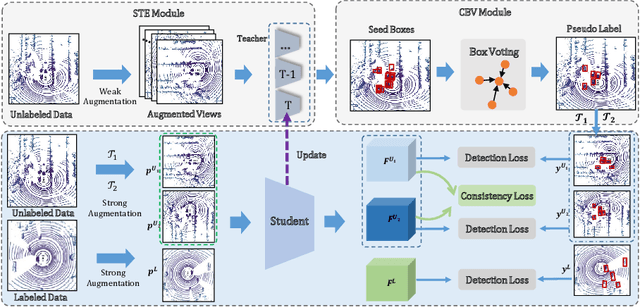

Dominated point cloud-based 3D object detectors in autonomous driving scenarios rely heavily on the huge amount of accurately labeled samples, however, 3D annotation in the point cloud is extremely tedious, expensive and time-consuming. To reduce the dependence on large supervision, semi-supervised learning (SSL) based approaches have been proposed. The Pseudo-Labeling methodology is commonly used for SSL frameworks, however, the low-quality predictions from the teacher model have seriously limited its performance. In this work, we propose a new Pseudo-Labeling framework for semi-supervised 3D object detection, by enhancing the teacher model to a proficient one with several necessary designs. First, to improve the recall of pseudo labels, a Spatialtemporal Ensemble (STE) module is proposed to generate sufficient seed boxes. Second, to improve the precision of recalled boxes, a Clusteringbased Box Voting (CBV) module is designed to get aggregated votes from the clustered seed boxes. This also eliminates the necessity of sophisticated thresholds to select pseudo labels. Furthermore, to reduce the negative influence of wrongly pseudo-labeled samples during the training, a soft supervision signal is proposed by considering Box-wise Contrastive Learning (BCL). The effectiveness of our model is verified on both ONCE and Waymo datasets. For example, on ONCE, our approach significantly improves the baseline by 9.51 mAP. Moreover, with half annotations, our model outperforms the oracle model with full annotations on Waymo.
ProposalContrast: Unsupervised Pre-training for LiDAR-based 3D Object Detection
Jul 26, 2022
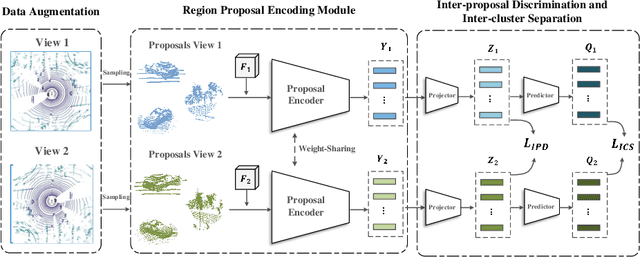
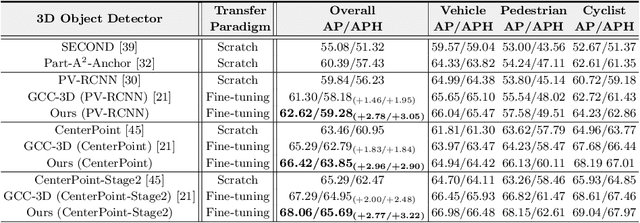
Existing approaches for unsupervised point cloud pre-training are constrained to either scene-level or point/voxel-level instance discrimination. Scene-level methods tend to lose local details that are crucial for recognizing the road objects, while point/voxel-level methods inherently suffer from limited receptive field that is incapable of perceiving large objects or context environments. Considering region-level representations are more suitable for 3D object detection, we devise a new unsupervised point cloud pre-training framework, called ProposalContrast, that learns robust 3D representations by contrasting region proposals. Specifically, with an exhaustive set of region proposals sampled from each point cloud, geometric point relations within each proposal are modeled for creating expressive proposal representations. To better accommodate 3D detection properties, ProposalContrast optimizes with both inter-cluster and inter-proposal separation, i.e., sharpening the discriminativeness of proposal representations across semantic classes and object instances. The generalizability and transferability of ProposalContrast are verified on various 3D detectors (i.e., PV-RCNN, CenterPoint, PointPillars and PointRCNN) and datasets (i.e., KITTI, Waymo and ONCE).