 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamArtist: Towards Controllable One-Shot Text-to-Image Generation via Contrastive Prompt-Tuning
Nov 21, 2022Large-scale text-to-image generation models with an exponential evolution can currently synthesize high-resolution, feature-rich, high-quality images based on text guidance. However, they are often overwhelmed by words of new concepts, styles, or object entities that always emerge. Although there are some recent attempts to use fine-tuning or prompt-tuning methods to teach the model a new concept as a new pseudo-word from a given reference image set, these methods are not only still difficult to synthesize diverse and high-quality images without distortion and artifacts, but also suffer from low controllability. To address these problems, we propose a DreamArtist method that employs a learning strategy of contrastive prompt-tuning, which introduces both positive and negative embeddings as pseudo-words and trains them jointly. The positive embedding aggressively learns characteristics in the reference image to drive the model diversified generation, while the negative embedding introspects in a self-supervised manner to rectify the mistakes and inadequacies from positive embedding in reverse. It learns not only what is correct but also what should be avoided. Extensive experiments on image quality and diversity analysis, controllability analysis, model learning analysis and task expansion have demonstrated that our model learns not only concept but also form, content and context. Pseudo-words of DreamArtist have similar properties as true words to generate high-quality images.
Category-Adaptive Label Discovery and Noise Rejection for Multi-label Image Recognition with Partial Positive Labels
Nov 15, 2022



As a promising solution of reducing annotation cost, training multi-label models with partial positive labels (MLR-PPL), in which merely few positive labels are known while other are missing, attracts increasing attention. Due to the absence of any negative labels, previous works regard unknown labels as negative and adopt traditional MLR algorithms. To reject noisy labels, recent works regard large loss samples as noise but ignore the semantic correlation different multi-label images. In this work, we propose to explore semantic correlation among different images to facilitate the MLR-PPL task. Specifically, we design a unified framework, Category-Adaptive Label Discovery and Noise Rejection, that discovers unknown labels and rejects noisy labels for each category in an adaptive manner. The framework consists of two complementary modules: (1) Category-Adaptive Label Discovery module first measures the semantic similarity between positive samples and then complement unknown labels with high similarities; (2) Category-Adaptive Noise Rejection module first computes the sample weights based on semantic similarities from different samples and then discards noisy labels with low weights. Besides, we propose a novel category-adaptive threshold updating that adaptively adjusts the threshold, to avoid the time-consuming manual tuning process. Extensive experiments demonstrate that our proposed method consistently outperforms current leading algorithms.
Divide and Contrast: Source-free Domain Adaptation via Adaptive Contrastive Learning
Nov 12, 2022



We investigate a practical domain adaptation task, called source-free domain adaptation (SFUDA), where the source-pretrained model is adapted to the target domain without access to the source data. Existing techniques mainly leverage self-supervised pseudo labeling to achieve class-wise global alignment [1] or rely on local structure extraction that encourages feature consistency among neighborhoods [2]. While impressive progress has been made, both lines of methods have their own drawbacks - the "global" approach is sensitive to noisy labels while the "local" counterpart suffers from source bias. In this paper, we present Divide and Contrast (DaC), a new paradigm for SFUDA that strives to connect the good ends of both worlds while bypassing their limitations. Based on the prediction confidence of the source model, DaC divides the target data into source-like and target-specific samples, where either group of samples is treated with tailored goals under an adaptive contrastive learning framework. Specifically, the source-like samples are utilized for learning global class clustering thanks to their relatively clean labels. The more noisy target-specific data are harnessed at the instance level for learning the intrinsic local structures. We further align the source-like domain with the target-specific samples using a memory bank-based Maximum Mean Discrepancy (MMD) loss to reduce the distribution mismatch. Extensive experiments on VisDA, Office-Home, and the more challenging DomainNet have verified the superior performance of DaC over current state-of-the-art approaches. The code is available at https://github.com/ZyeZhang/DaC.git.
Structure-Preserving 3D Garment Modeling with Neural Sewing Machines
Nov 12, 2022



3D Garment modeling is a critical and challenging topic in the area of computer vision and graphics, with increasing attention focused on garment representation learning, garment reconstruction, and controllable garment manipulation, whereas existing methods were constrained to model garments under specific categories or with relatively simple topologies. In this paper, we propose a novel Neural Sewing Machine (NSM), a learning-based framework for structure-preserving 3D garment modeling, which is capable of learning representations for garments with diverse shapes and topologies and is successfully applied to 3D garment reconstruction and controllable manipulation. To model generic garments, we first obtain sewing pattern embedding via a unified sewing pattern encoding module, as the sewing pattern can accurately describe the intrinsic structure and the topology of the 3D garment. Then we use a 3D garment decoder to decode the sewing pattern embedding into a 3D garment using the UV-position maps with masks. To preserve the intrinsic structure of the predicted 3D garment, we introduce an inner-panel structure-preserving loss, an inter-panel structure-preserving loss, and a surface-normal loss in the learning process of our framework. We evaluate NSM on the public 3D garment dataset with sewing patterns with diverse garment shapes and categories. Extensive experiments demonstrate that the proposed NSM is capable of representing 3D garments under diverse garment shapes and topologies, realistically reconstructing 3D garments from 2D images with the preserved structure, and accurately manipulating the 3D garment categories, shapes, and topologies, outperforming the state-of-the-art methods by a clear margin.
OhMG: Zero-shot Open-vocabulary Human Motion Generation
Oct 28, 2022



Generating motion in line with text has attracted increasing attention nowadays. However, open-vocabulary human motion generation still remains touchless and undergoes the lack of diverse labeled data. The good news is that, recent studies of large multi-model foundation models (e.g., CLIP) have demonstrated superior performance on few/zero-shot image-text alignment, largely reducing the need for manually labeled data. In this paper, we take advantage of CLIP for open-vocabulary 3D human motion generation in a zero-shot manner. Specifically, our model is composed of two stages, i.e., text2pose and pose2motion. For text2pose, to address the difficulty of optimization with direct supervision from CLIP, we propose to carve the versatile CLIP model into a slimmer but more specific model for aligning 3D poses and texts, via a novel pipeline distillation strategy. Optimizing with the distilled 3D pose-text model, we manage to concretize the text-pose knowledge of CLIP into a text2pose generator effectively and efficiently. As for pose2motion, drawing inspiration from the advanced language model, we pretrain a transformer-based motion model, which makes up for the lack of motion dynamics of CLIP. After that, by formulating the generated poses from the text2pose stage as prompts, the motion generator can generate motions referring to the poses in a controllable and flexible manner. Our method is validated against advanced baselines and obtains sharp improvements. The code will be released here.
Layer-wise Shared Attention Network on Dynamical System Perspective
Oct 27, 2022



Attention networks have successfully boosted accuracy in various vision problems. Previous works lay emphasis on designing a new self-attention module and follow the traditional paradigm that individually plugs the modules into each layer of a network. However, such a paradigm inevitably increases the extra parameter cost with the growth of the number of layers. From the dynamical system perspective of the residual neural network, we find that the feature maps from the layers of the same stage are homogenous, which inspires us to propose a novel-and-simple framework, called the dense and implicit attention (DIA) unit, that shares a single attention module throughout different network layers. With our framework, the parameter cost is independent of the number of layers and we further improve the accuracy of existing popular self-attention modules with significant parameter reduction without any elaborated model crafting. Extensive experiments on benchmark datasets show that the DIA is capable of emphasizing layer-wise feature interrelation and thus leads to significant improvement in various vision tasks, including image classification, object detection, and medical application. Furthermore, the effectiveness of the DIA unit is demonstrated by novel experiments where we destabilize the model training by (1) removing the skip connection of the residual neural network, (2) removing the batch normalization of the model, and (3) removing all data augmentation during training. In these cases, we verify that DIA has a strong regularization ability to stabilize the training, i.e., the dense and implicit connections formed by our method can effectively recover and enhance the information communication across layers and the value of the gradient thus alleviate the training instability.
Cross-Modal Causal Relational Reasoning for Event-Level Visual Question Answering
Aug 15, 2022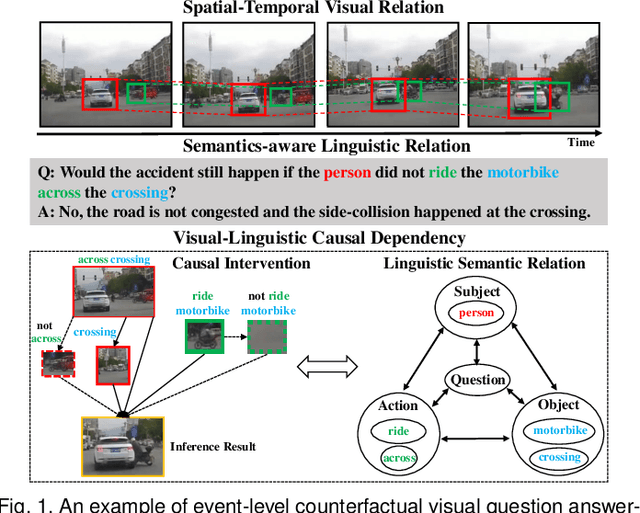
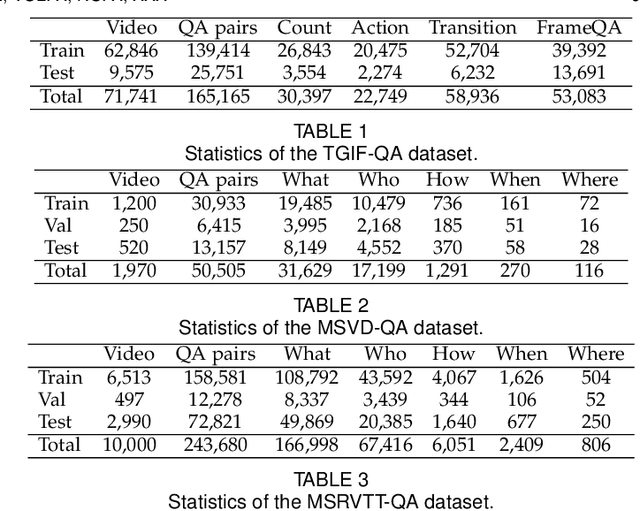
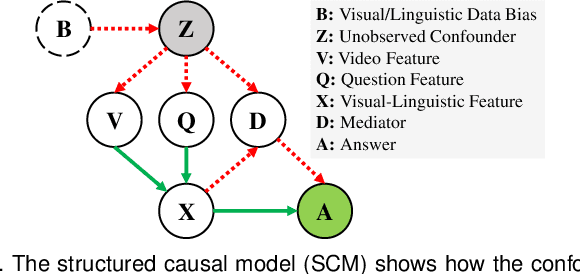
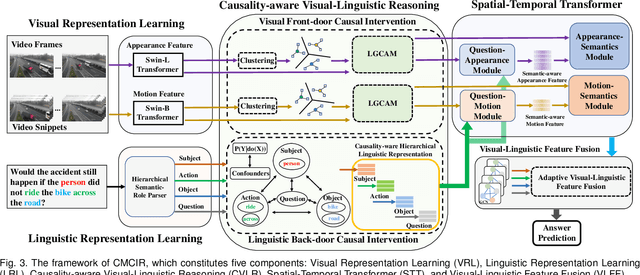
Existing visual question answering methods tend to capture the spurious correlations from visual and linguistic modalities, and fail to discover the true casual mechanism that facilitates reasoning truthfully based on the dominant visual evidence and the correct question intention. Additionally, the existing methods usually ignore the complex event-level understanding in multi-modal settings that requires a strong cognitive capability of causal inference to jointly model cross-modal event temporality, causality, and dynamics. In this work, we focus on event-level visual question answering from a new perspective, i.e., cross-modal causal relational reasoning, by introducing causal intervention methods to mitigate the spurious correlations and discover the true causal structures for the integration of visual and linguistic modalities. Specifically, we propose a novel event-level visual question answering framework named Cross-Modal Causal RelatIonal Reasoning (CMCIR), to achieve robust casuality-aware visual-linguistic question answering. To uncover the causal structures for visual and linguistic modalities, the novel Causality-aware Visual-Linguistic Reasoning (CVLR) module is proposed to collaboratively disentangle the visual and linguistic spurious correlations via elaborately designed front-door and back-door causal intervention modules. To discover the fine-grained interactions between linguistic semantics and spatial-temporal representations, we build a novel Spatial-Temporal Transformer (STT) that builds the multi-modal co-occurrence interactions between visual and linguistic content. Extensive experiments on large-scale event-level urban dataset SUTD-TrafficQA and three benchmark real-world datasets TGIF-QA, MSVD-QA, and MSRVTT-QA demonstrate the effectiveness of our CMCIR for discovering visual-linguistic causal structures.
Accelerating Numerical Solvers for Large-Scale Simulation of Dynamical System via NeurVec
Aug 07, 2022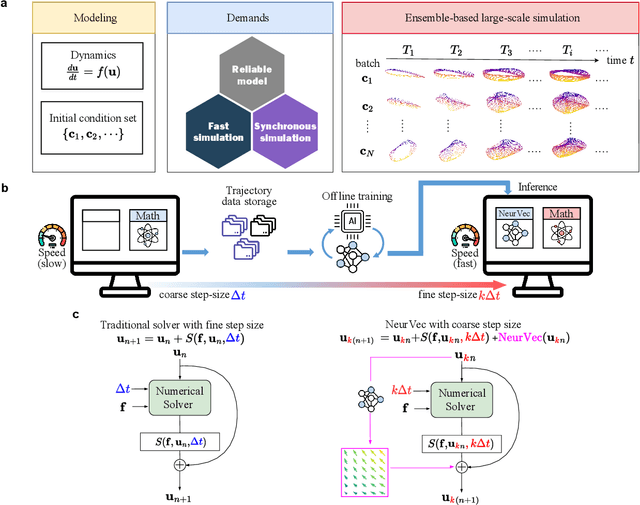

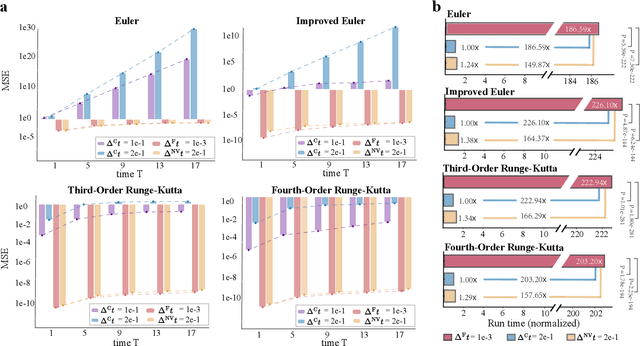
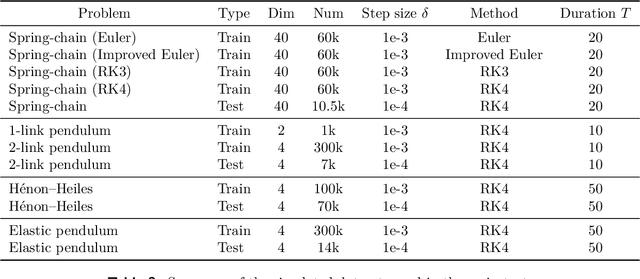
Ensemble-based large-scale simulation of dynamical systems is essential to a wide range of science and engineering problems. Conventional numerical solvers used in the simulation are significantly limited by the step size for time integration, which hampers efficiency and feasibility especially when high accuracy is desired. To overcome this limitation, we propose a data-driven corrector method that allows using large step sizes while compensating for the integration error for high accuracy. This corrector is represented in the form of a vector-valued function and is modeled by a neural network to regress the error in the phase space. Hence we name the corrector neural vector (NeurVec). We show that NeurVec can achieve the same accuracy as traditional solvers with much larger step sizes. We empirically demonstrate that NeurVec can accelerate a variety of numerical solvers significantly and overcome the stability restriction of these solvers. Our results on benchmark problems, ranging from high-dimensional problems to chaotic systems, suggest that NeurVec is capable of capturing the leading error term and maintaining the statistics of ensemble forecasts.
Robust Real-World Image Super-Resolution against Adversarial Attacks
Jul 31, 2022
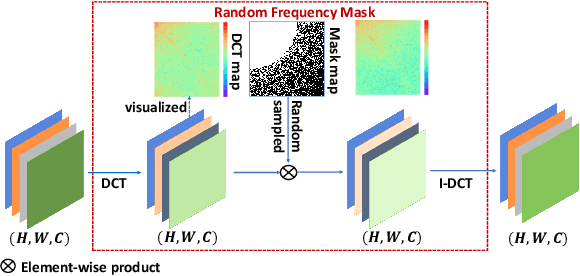
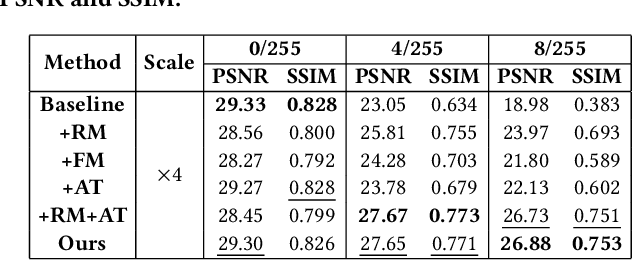
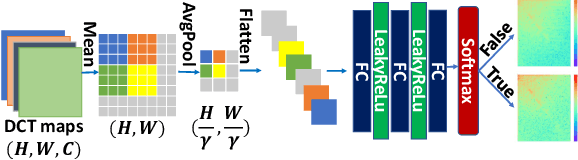
Recently deep neural networks (DNNs) have achieved significant success in real-world image super-resolution (SR). However, adversarial image samples with quasi-imperceptible noises could threaten deep learning SR models. In this paper, we propose a robust deep learning framework for real-world SR that randomly erases potential adversarial noises in the frequency domain of input images or features. The rationale is that on the SR task clean images or features have a different pattern from the attacked ones in the frequency domain. Observing that existing adversarial attacks usually add high-frequency noises to input images, we introduce a novel random frequency mask module that blocks out high-frequency components possibly containing the harmful perturbations in a stochastic manner. Since the frequency masking may not only destroys the adversarial perturbations but also affects the sharp details in a clean image, we further develop an adversarial sample classifier based on the frequency domain of images to determine if applying the proposed mask module. Based on the above ideas, we devise a novel real-world image SR framework that combines the proposed frequency mask modules and the proposed adversarial classifier with an existing super-resolution backbone network. Experiments show that our proposed method is more insensitive to adversarial attacks and presents more stable SR results than existing models and defenses.
* ACM-MM 2021, Code: https://github.com/lhaof/Robust-SR-against-Adversarial-Attacks
Adversarially-Aware Robust Object Detector
Jul 22, 2022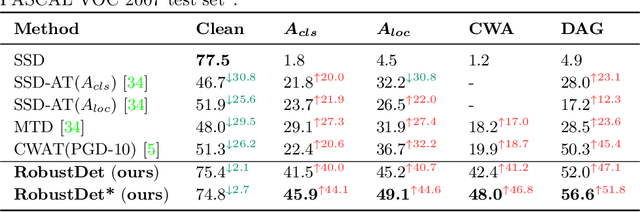
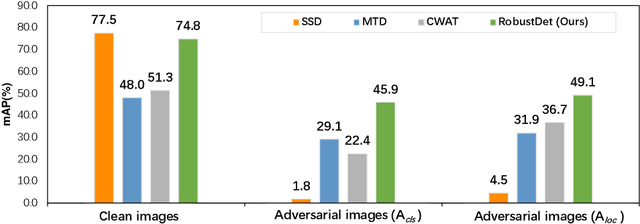
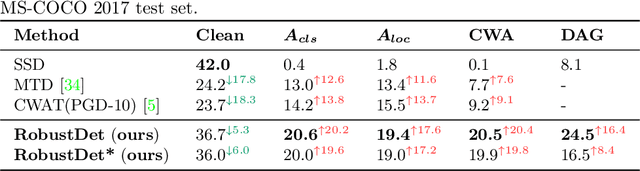
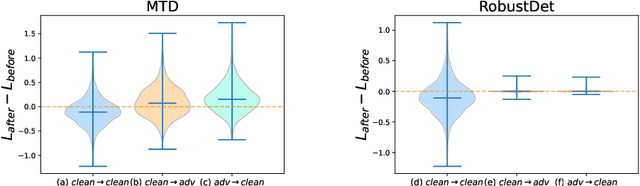
Object detection, as a fundamental computer vision task, has achieved a remarkable progress with the emergence of deep neural networks. Nevertheless, few works explore the adversarial robustness of object detectors to resist adversarial attacks for practical applications in various real-world scenarios. Detectors have been greatly challenged by unnoticeable perturbation, with sharp performance drop on clean images and extremely poor performance on adversarial images. In this work, we empirically explore the model training for adversarial robustness in object detection, which greatly attributes to the conflict between learning clean images and adversarial images. To mitigate this issue, we propose a Robust Detector (RobustDet) based on adversarially-aware convolution to disentangle gradients for model learning on clean and adversarial images. RobustDet also employs the Adversarial Image Discriminator (AID) and Consistent Features with Reconstruction (CFR) to ensure a reliable robustness. Extensive experiments on PASCAL VOC and MS-COCO demonstrate that our model effectively disentangles gradients and significantly enhances the detection robustness with maintaining the detection ability on clean images.
* ECCV2022 oral paper