 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-term Wind Power Forecasting with Hierarchical Spatial-Temporal Transformer
May 30, 2023



Wind power is attracting increasing attention around the world due to its renewable, pollution-free, and other advantages. However, safely and stably integrating the high permeability intermittent power energy into electric power systems remains challenging. Accurate wind power forecasting (WPF) can effectively reduce power fluctuations in power system operations. Existing methods are mainly designed for short-term predictions and lack effective spatial-temporal feature augmentation. In this work, we propose a novel end-to-end wind power forecasting model named Hierarchical Spatial-Temporal Transformer Network (HSTTN) to address the long-term WPF problems. Specifically, we construct an hourglass-shaped encoder-decoder framework with skip-connections to jointly model representations aggregated in hierarchical temporal scales, which benefits long-term forecasting. Based on this framework, we capture the inter-scale long-range temporal dependencies and global spatial correlations with two parallel Transformer skeletons and strengthen the intra-scale connections with downsampling and upsampling operations. Moreover, the complementary information from spatial and temporal features is fused and propagated in each other via Contextual Fusion Blocks (CFBs) to promote the prediction further. Extensive experimental results on two large-scale real-world datasets demonstrate the superior performance of our HSTTN over existing solutions.
Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models
May 23, 2023This paper presents a controllable text-to-video (T2V) diffusion model, named Video-ControlNet, that generates videos conditioned on a sequence of control signals, such as edge or depth maps. Video-ControlNet is built on a pre-trained conditional text-to-image (T2I) diffusion model by incorporating a spatial-temporal self-attention mechanism and trainable temporal layers for efficient cross-frame modeling. A first-frame conditioning strategy is proposed to facilitate the model to generate videos transferred from the image domain as well as arbitrary-length videos in an auto-regressive manner. Moreover, Video-ControlNet employs a novel residual-based noise initialization strategy to introduce motion prior from an input video, producing more coherent videos. With the proposed architecture and strategies, Video-ControlNet can achieve resource-efficient convergence and generate superior quality and consistent videos with fine-grained control. Extensive experiments demonstrate its success in various video generative tasks such as video editing and video style transfer, outperforming previous methods in terms of consistency and quality. Project Page: https://controlavideo.github.io/
Identity-Preserving Talking Face Generation with Landmark and Appearance Priors
May 15, 2023



Generating talking face videos from audio attracts lots of research interest. A few person-specific methods can generate vivid videos but require the target speaker's videos for training or fine-tuning. Existing person-generic methods have difficulty in generating realistic and lip-synced videos while preserving identity information. To tackle this problem, we propose a two-stage framework consisting of audio-to-landmark generation and landmark-to-video rendering procedures. First, we devise a novel Transformer-based landmark generator to infer lip and jaw landmarks from the audio. Prior landmark characteristics of the speaker's face are employed to make the generated landmarks coincide with the facial outline of the speaker. Then, a video rendering model is built to translate the generated landmarks into face images. During this stage, prior appearance information is extracted from the lower-half occluded target face and static reference images, which helps generate realistic and identity-preserving visual content. For effectively exploring the prior information of static reference images, we align static reference images with the target face's pose and expression based on motion fields. Moreover, auditory features are reused to guarantee that the generated face images are well synchronized with the audio. Extensive experiments demonstrate that our method can produce more realistic, lip-synced, and identity-preserving videos than existing person-generic talking face generation methods.
SUR-adapter: Enhancing Text-to-Image Pre-trained Diffusion Models with Large Language Models
May 12, 2023



Diffusion models, which have emerged to become popular text-to-image generation models, can produce high-quality and content-rich images guided by textual prompts. However, there are limitations to semantic understanding and commonsense reasoning in existing models when the input prompts are concise narrative, resulting in low-quality image generation. To improve the capacities for narrative prompts, we propose a simple-yet-effective parameter-efficient fine-tuning approach called the Semantic Understanding and Reasoning adapter (SUR-adapter) for pre-trained diffusion models. To reach this goal, we first collect and annotate a new dataset SURD which consists of more than 57,000 semantically corrected multi-modal samples. Each sample contains a simple narrative prompt, a complex keyword-based prompt, and a high-quality image. Then, we align the semantic representation of narrative prompts to the complex prompts and transfer knowledge of large language models (LLMs) to our SUR-adapter via knowledge distillation so that it can acquire the powerful semantic understanding and reasoning capabilities to build a high-quality textual semantic representation for text-to-image generation. We conduct experiments by integrating multiple LLMs and popular pre-trained diffusion models to show the effectiveness of our approach in enabling diffusion models to understand and reason concise natural language without image quality degradation. Our approach can make text-to-image diffusion models easier to use with better user experience, which demonstrates our approach has the potential for further advancing the development of user-friendly text-to-image generation models by bridging the semantic gap between simple narrative prompts and complex keyword-based prompts. The code is released at https://github.com/Qrange-group/SUR-adapter.
Visual Causal Scene Refinement for Video Question Answering
May 07, 2023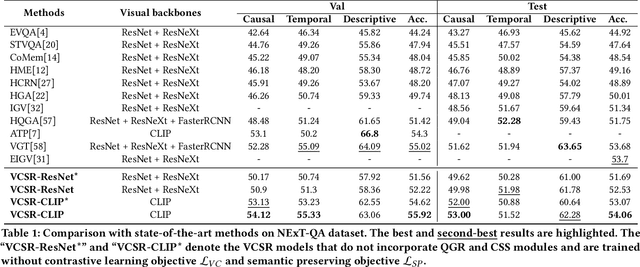
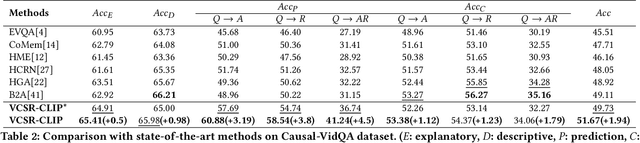
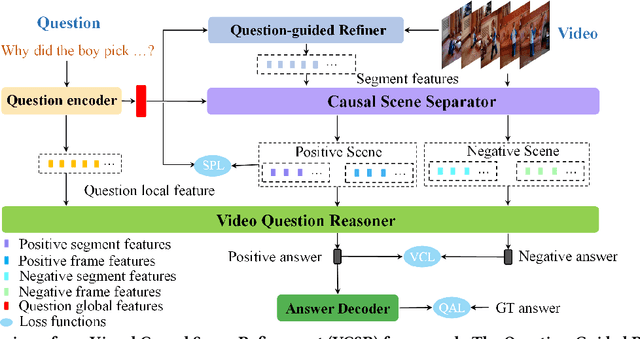
Existing methods for video question answering (VideoQA) often suffer from spurious correlations between different modalities, leading to a failure in identifying the dominant visual evidence and the intended question. Moreover, these methods function as black boxes, making it difficult to interpret the visual scene during the QA process. In this paper, to discover critical video segments and frames that serve as the visual causal scene for generating reliable answers, we present a causal analysis of VideoQA and propose a framework for cross-modal causal relational reasoning, named Visual Causal Scene Refinement (VCSR). Particularly, a set of causal front-door intervention operations is introduced to explicitly find the visual causal scenes at both segment and frame levels. Our VCSR involves two essential modules: i) the Question-Guided Refiner (QGR) module, which refines consecutive video frames guided by the question semantics to obtain more representative segment features for causal front-door intervention; ii) the Causal Scene Separator (CSS) module, which discovers a collection of visual causal and non-causal scenes based on the visual-linguistic causal relevance and estimates the causal effect of the scene-separating intervention in a contrastive learning manner. Extensive experiments on the NExT-QA, Causal-VidQA, and MSRVTT-QA datasets demonstrate the superiority of our VCSR in discovering visual causal scene and achieving robust video question answering.
Multi-object Video Generation from Single Frame Layouts
May 06, 2023



In this paper, we study video synthesis with emphasis on simplifying the generation conditions. Most existing video synthesis models or datasets are designed to address complex motions of a single object, lacking the ability of comprehensively understanding the spatio-temporal relationships among multiple objects. Besides, current methods are usually conditioned on intricate annotations (e.g. video segmentations) to generate new videos, being fundamentally less practical. These motivate us to generate multi-object videos conditioning exclusively on object layouts from a single frame. To solve above challenges and inspired by recent research on image generation from layouts, we have proposed a novel video generative framework capable of synthesizing global scenes with local objects, via implicit neural representations and layout motion self-inference. Our framework is a non-trivial adaptation from image generation methods, and is new to this field. In addition, our model has been evaluated on two widely-used video recognition benchmarks, demonstrating effectiveness compared to the baseline model.
Causality-aware Visual Scene Discovery for Cross-Modal Question Reasoning
Apr 17, 2023Existing visual question reasoning methods usually fail to explicitly discover the inherent causal mechanism and ignore the complex event-level understanding that requires jointly modeling cross-modal event temporality and causality. In this paper, we propose an event-level visual question reasoning framework named Cross-Modal Question Reasoning (CMQR), to explicitly discover temporal causal structure and mitigate visual spurious correlation by causal intervention. To explicitly discover visual causal structure, the Visual Causality Discovery (VCD) architecture is proposed to find question-critical scene temporally and disentangle the visual spurious correlations by attention-based front-door causal intervention module named Local-Global Causal Attention Module (LGCAM). To align the fine-grained interactions between linguistic semantics and spatial-temporal representations, we build an Interactive Visual-Linguistic Transformer (IVLT) that builds the multi-modal co-occurrence interactions between visual and linguistic content. Extensive experiments on four datasets demonstrate the superiority of CMQR for discovering visual causal structures and achieving robust question reasoning.
ASR: Attention-alike Structural Re-parameterization
Apr 13, 2023



The structural re-parameterization (SRP) technique is a novel deep learning technique that achieves interconversion between different network architectures through equivalent parameter transformations. This technique enables the mitigation of the extra costs for performance improvement during training, such as parameter size and inference time, through these transformations during inference, and therefore SRP has great potential for industrial and practical applications. The existing SRP methods have successfully considered many commonly used architectures, such as normalizations, pooling methods, multi-branch convolution. However, the widely used self-attention modules cannot be directly implemented by SRP due to these modules usually act on the backbone network in a multiplicative manner and the modules' output is input-dependent during inference, which limits the application scenarios of SRP. In this paper, we conduct extensive experiments from a statistical perspective and discover an interesting phenomenon Stripe Observation, which reveals that channel attention values quickly approach some constant vectors during training. This observation inspires us to propose a simple-yet-effective attention-alike structural re-parameterization (ASR) that allows us to achieve SRP for a given network while enjoying the effectiveness of the self-attention mechanism. Extensive experiments conducted on several standard benchmarks demonstrate the effectiveness of ASR in generally improving the performance of existing backbone networks, self-attention modules, and SRP methods without any elaborated model crafting. We also analyze the limitations and provide experimental or theoretical evidence for the strong robustness of the proposed ASR.
Open-World Pose Transfer via Sequential Test-Time Adaption
Mar 20, 2023



Pose transfer aims to transfer a given person into a specified posture, has recently attracted considerable attention. A typical pose transfer framework usually employs representative datasets to train a discriminative model, which is often violated by out-of-distribution (OOD) instances. Recently, test-time adaption (TTA) offers a feasible solution for OOD data by using a pre-trained model that learns essential features with self-supervision. However, those methods implicitly make an assumption that all test distributions have a unified signal that can be learned directly. In open-world conditions, the pose transfer task raises various independent signals: OOD appearance and skeleton, which need to be extracted and distributed in speciality. To address this point, we develop a SEquential Test-time Adaption (SETA). In the test-time phrase, SETA extracts and distributes external appearance texture by augmenting OOD data for self-supervised training. To make non-Euclidean similarity among different postures explicit, SETA uses the image representations derived from a person re-identification (Re-ID) model for similarity computation. By addressing implicit posture representation in the test-time sequentially, SETA greatly improves the generalization performance of current pose transfer models. In our experiment, we first show that pose transfer can be applied to open-world applications, including Tiktok reenactment and celebrity motion synthesis.
Urban Regional Function Guided Traffic Flow Prediction
Mar 20, 2023



The prediction of traffic flow is a challenging yet crucial problem in spatial-temporal analysis, which has recently gained increasing interest. In addition to spatial-temporal correlations, the functionality of urban areas also plays a crucial role in traffic flow prediction. However, the exploration of regional functional attributes mainly focuses on adding additional topological structures, ignoring the influence of functional attributes on regional traffic patterns. Different from the existing works, we propose a novel module named POI-MetaBlock, which utilizes the functionality of each region (represented by Point of Interest distribution) as metadata to further mine different traffic characteristics in areas with different functions. Specifically, the proposed POI-MetaBlock employs a self-attention architecture and incorporates POI and time information to generate dynamic attention parameters for each region, which enables the model to fit different traffic patterns of various areas at different times. Furthermore, our lightweight POI-MetaBlock can be easily integrated into conventional traffic flow prediction models. Extensive experiments demonstrate that our module significantly improves the performance of traffic flow prediction and outperforms state-of-the-art methods that use metadata.