 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Knowledge Conflicts in Domain-specific Data Selection: A Case Study on Medical Instruction-tuning
May 28, 2025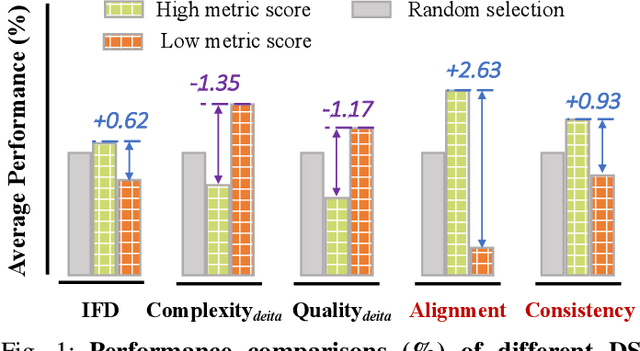
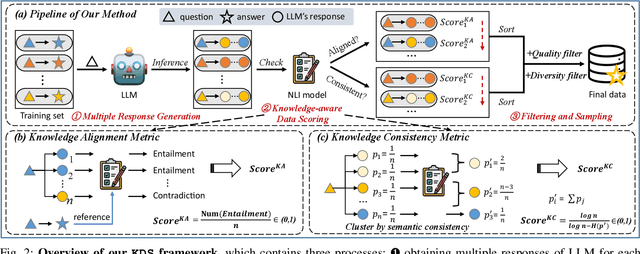
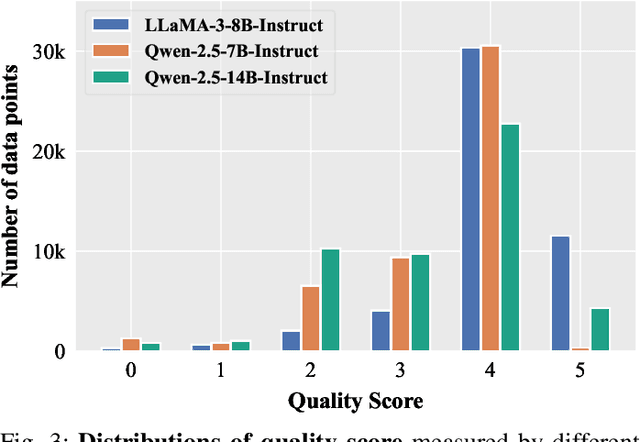
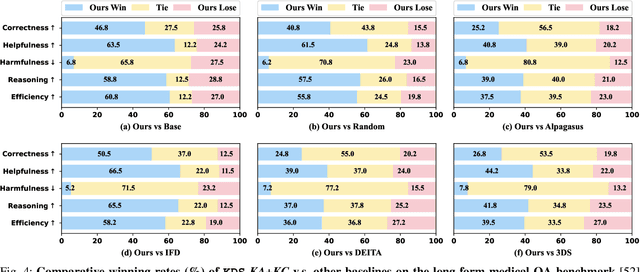
Domain-specific instruction-tuning has become the defacto standard for improving the performance of large language models (LLMs) in specialized applications, e.g., medical question answering. Since the instruction-tuning dataset might contain redundant or low-quality data, data selection (DS) is usually required to maximize the data efficiency. Despite the successes in the general domain, current DS methods often struggle to select the desired data for domain-specific instruction-tuning. One of the main reasons is that they neglect the impact of knowledge conflicts, i.e., the discrepancy between LLMs' pretrained knowledge and context knowledge of instruction data, which could damage LLMs' prior abilities and lead to hallucination. To this end, we propose a simple-yet-effective Knowledge-aware Data Selection (namely KDS) framework to select the domain-specific instruction-tuning data that meets LLMs' actual needs. The core of KDS is to leverage two knowledge-aware metrics for quantitatively measuring knowledge conflicts from two aspects: context-memory knowledge alignment and intra-memory knowledge consistency. By filtering the data with large knowledge conflicts and sampling the high-quality and diverse data, KDS can effectively stimulate the LLMs' abilities and achieve better domain-specific performance. Taking the medical domain as the testbed, we conduct extensive experiments and empirically prove that KDS surpasses the other baselines and brings significant and consistent performance gains among all LLMs. More encouragingly, KDS effectively improves the model generalization and alleviates the hallucination problem.
Runaway is Ashamed, But Helpful: On the Early-Exit Behavior of Large Language Model-based Agents in Embodied Environments
May 23, 2025Agents powered by large language models (LLMs) have demonstrated strong planning and decision-making capabilities in complex embodied environments. However, such agents often suffer from inefficiencies in multi-turn interactions, frequently trapped in repetitive loops or issuing ineffective commands, leading to redundant computational overhead. Instead of relying solely on learning from trajectories, we take a first step toward exploring the early-exit behavior for LLM-based agents. We propose two complementary approaches: 1. an $\textbf{intrinsic}$ method that injects exit instructions during generation, and 2. an $\textbf{extrinsic}$ method that verifies task completion to determine when to halt an agent's trial. To evaluate early-exit mechanisms, we introduce two metrics: one measures the reduction of $\textbf{redundant steps}$ as a positive effect, and the other evaluates $\textbf{progress degradation}$ as a negative effect. Experiments with 4 different LLMs across 5 embodied environments show significant efficiency improvements, with only minor drops in agent performance. We also validate a practical strategy where a stronger agent assists after an early-exit agent, achieving better performance with the same total steps. We will release our code to support further research.
Chinese Toxic Language Mitigation via Sentiment Polarity Consistent Rewrites
May 21, 2025Detoxifying offensive language while preserving the speaker's original intent is a challenging yet critical goal for improving the quality of online interactions. Although large language models (LLMs) show promise in rewriting toxic content, they often default to overly polite rewrites, distorting the emotional tone and communicative intent. This problem is especially acute in Chinese, where toxicity often arises implicitly through emojis, homophones, or discourse context. We present ToxiRewriteCN, the first Chinese detoxification dataset explicitly designed to preserve sentiment polarity. The dataset comprises 1,556 carefully annotated triplets, each containing a toxic sentence, a sentiment-aligned non-toxic rewrite, and labeled toxic spans. It covers five real-world scenarios: standard expressions, emoji-induced and homophonic toxicity, as well as single-turn and multi-turn dialogues. We evaluate 17 LLMs, including commercial and open-source models with variant architectures, across four dimensions: detoxification accuracy, fluency, content preservation, and sentiment polarity. Results show that while commercial and MoE models perform best overall, all models struggle to balance safety with emotional fidelity in more subtle or context-heavy settings such as emoji, homophone, and dialogue-based inputs. We release ToxiRewriteCN to support future research on controllable, sentiment-aware detoxification for Chinese.
KaFT: Knowledge-aware Fine-tuning for Boosting LLMs' Domain-specific Question-Answering Performance
May 21, 2025Supervised fine-tuning (SFT) is a common approach to improve the domain-specific question-answering (QA) performance of large language models (LLMs). However, recent literature reveals that due to the conflicts between LLMs' internal knowledge and the context knowledge of training data, vanilla SFT using the full QA training set is usually suboptimal. In this paper, we first design a query diversification strategy for robust conflict detection and then conduct a series of experiments to analyze the impact of knowledge conflict. We find that 1) training samples with varied conflicts contribute differently, where SFT on the data with large conflicts leads to catastrophic performance drops; 2) compared to directly filtering out the conflict data, appropriately applying the conflict data would be more beneficial. Motivated by this, we propose a simple-yet-effective Knowledge-aware Fine-tuning (namely KaFT) approach to effectively boost LLMs' performance. The core of KaFT is to adapt the training weight by assigning different rewards for different training samples according to conflict level. Extensive experiments show that KaFT brings consistent and significant improvements across four LLMs. More analyses prove that KaFT effectively improves the model generalization and alleviates the hallucination.
Entropy-Guided Watermarking for LLMs: A Test-Time Framework for Robust and Traceable Text Generation
Apr 16, 2025The rapid development of Large Language Models (LLMs) has intensified concerns about content traceability and potential misuse. Existing watermarking schemes for sampled text often face trade-offs between maintaining text quality and ensuring robust detection against various attacks. To address these issues, we propose a novel watermarking scheme that improves both detectability and text quality by introducing a cumulative watermark entropy threshold. Our approach is compatible with and generalizes existing sampling functions, enhancing adaptability. Experimental results across multiple LLMs show that our scheme significantly outperforms existing methods, achieving over 80\% improvements on widely-used datasets, e.g., MATH and GSM8K, while maintaining high detection accuracy.
VisuoThink: Empowering LVLM Reasoning with Multimodal Tree Search
Apr 12, 2025Recent advancements in Large Vision-Language Models have showcased remarkable capabilities. However, they often falter when confronted with complex reasoning tasks that humans typically address through visual aids and deliberate, step-by-step thinking. While existing methods have explored text-based slow thinking or rudimentary visual assistance, they fall short of capturing the intricate, interleaved nature of human visual-verbal reasoning processes. To overcome these limitations and inspired by the mechanisms of slow thinking in human cognition, we introduce VisuoThink, a novel framework that seamlessly integrates visuospatial and linguistic domains. VisuoThink facilitates multimodal slow thinking by enabling progressive visual-textual reasoning and incorporates test-time scaling through look-ahead tree search. Extensive experiments demonstrate that VisuoThink significantly enhances reasoning capabilities via inference-time scaling, even without fine-tuning, achieving state-of-the-art performance in tasks involving geometry and spatial reasoning.
AgentDropout: Dynamic Agent Elimination for Token-Efficient and High-Performance LLM-Based Multi-Agent Collaboration
Mar 24, 2025Multi-agent systems (MAS) based on large language models (LLMs) have demonstrated significant potential in collaborative problem-solving. However, they still face substantial challenges of low communication efficiency and suboptimal task performance, making the careful design of the agents' communication topologies particularly important. Inspired by the management theory that roles in an efficient team are often dynamically adjusted, we propose AgentDropout, which identifies redundant agents and communication across different communication rounds by optimizing the adjacency matrices of the communication graphs and eliminates them to enhance both token efficiency and task performance. Compared to state-of-the-art methods, AgentDropout achieves an average reduction of 21.6% in prompt token consumption and 18.4% in completion token consumption, along with a performance improvement of 1.14 on the tasks. Furthermore, the extended experiments demonstrate that AgentDropout achieves notable domain transferability and structure robustness, revealing its reliability and effectiveness. We release our code at https://github.com/wangzx1219/AgentDropout.
Retrieval-Augmented Perception: High-Resolution Image Perception Meets Visual RAG
Mar 03, 2025



High-resolution (HR) image perception remains a key challenge in multimodal large language models (MLLMs). To overcome the limitations of existing methods, this paper shifts away from prior dedicated heuristic approaches and revisits the most fundamental idea to HR perception by enhancing the long-context capability of MLLMs, driven by recent advances in long-context techniques like retrieval-augmented generation (RAG) for general LLMs. Towards this end, this paper presents the first study exploring the use of RAG to address HR perception challenges. Specifically, we propose Retrieval-Augmented Perception (RAP), a training-free framework that retrieves and fuses relevant image crops while preserving spatial context using the proposed Spatial-Awareness Layout. To accommodate different tasks, the proposed Retrieved-Exploration Search (RE-Search) dynamically selects the optimal number of crops based on model confidence and retrieval scores. Experimental results on HR benchmarks demonstrate the significant effectiveness of RAP, with LLaVA-v1.5-13B achieving a 43% improvement on $V^*$ Bench and 19% on HR-Bench.
Edit Once, Update Everywhere: A Simple Framework for Cross-Lingual Knowledge Synchronization in LLMs
Feb 20, 2025



Knowledge editing allows for efficient adaptation of large language models (LLMs) to new information or corrections without requiring full retraining. However, prior methods typically focus on either single-language editing or basic multilingual editing, failing to achieve true cross-linguistic knowledge synchronization. To address this, we present a simple and practical state-of-the-art (SOTA) recipe Cross-Lingual Knowledge Democracy Edit (X-KDE), designed to propagate knowledge from a dominant language to other languages effectively. Our X-KDE comprises two stages: (i) Cross-lingual Edition Instruction Tuning (XE-IT), which fine-tunes the model on a curated parallel dataset to modify in-scope knowledge while preserving unrelated information, and (ii) Target-language Preference Optimization (TL-PO), which applies advanced optimization techniques to ensure consistency across languages, fostering the transfer of updates. Additionally, we contribute a high-quality, cross-lingual dataset, specifically designed to enhance knowledge transfer across languages. Extensive experiments on the Bi-ZsRE and MzsRE benchmarks show that X-KDE significantly enhances cross-lingual performance, achieving an average improvement of +8.19%, while maintaining high accuracy in monolingual settings.
Enhancing Input-Label Mapping in In-Context Learning with Contrastive Decoding
Feb 19, 2025Large language models (LLMs) excel at a range of tasks through in-context learning (ICL), where only a few task examples guide their predictions. However, prior research highlights that LLMs often overlook input-label mapping information in ICL, relying more on their pre-trained knowledge. To address this issue, we introduce In-Context Contrastive Decoding (ICCD), a novel method that emphasizes input-label mapping by contrasting the output distributions between positive and negative in-context examples. Experiments on 7 natural language understanding (NLU) tasks show that our ICCD method brings consistent and significant improvement (up to +2.1 improvement on average) upon 6 different scales of LLMs without requiring additional training. Our approach is versatile, enhancing performance with various demonstration selection methods, demonstrating its broad applicability and effectiveness. The code and scripts will be publicly released.