 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Recognition of Basic Surgical Actions Enables Skill Assessment and Vision-Language-Model-based Surgical Planning
Mar 13, 2026Artificial intelligence, imaging, and large language models have the potential to transform surgical practice, training, and automation. Understanding and modeling of basic surgical actions (BSA), the fundamental unit of operation in any surgery, is important to drive the evolution of this field. In this paper, we present a BSA dataset comprising 10 basic actions across 6 surgical specialties with over 11,000 video clips, which is the largest to date. Based on the BSA dataset, we developed a new foundation model that conducts general-purpose recognition of basic actions. Our approach demonstrates robust cross-specialist performance in experiments validated on datasets from different procedural types and various body parts. Furthermore, we demonstrate downstream applications enabled by the BAS foundation model through surgical skill assessment in prostatectomy using domain-specific knowledge, and action planning in cholecystectomy and nephrectomy using large vision-language models. Multinational surgeons' evaluation of the language model's output of the action planning explainable texts demonstrated clinical relevance. These findings indicate that basic surgical actions can be robustly recognized across scenarios, and an accurate BSA understanding model can essentially facilitate complex applications and speed up the realization of surgical superintelligence.
From Pets to Robots: MojiKit as a Data-Informed Toolkit for Affective HRI Design
Mar 12, 2026Designing affective behaviors for animal-inspired social robots often relies on intuition and personal experience, leading to fragmented outcomes. To provide more systematic guidance, we first coded and analyzed human-pet interaction videos, validated insights through literature and interviews, and created structured reference cards that map the design space of pet-inspired affective interactions. Building on this, we developed MojiKit, a toolkit combining reference cards, a zoomorphic robot prototype (MomoBot), and a behavior control studio. We evaluated MojiKit in co-creation workshops with 18 participants, finding that MojiKit helped them design 35 affective interaction patterns beyond their own pet experiences, while the code-free studio lowered the technical barrier and enhanced creative agency. Our contributions include the data-informed structured resource for pet-inspired affective HRI design, an integrated toolkit that bridges reference materials with hands-on prototyping, and empirical evidence showing how MojiKit empowers users to systematically create richer, more diverse affective robot behaviors.
Rethinking Multilingual Vision-Language Translation: Dataset, Evaluation, and Adaptation
Jun 13, 2025Vision-Language Translation (VLT) is a challenging task that requires accurately recognizing multilingual text embedded in images and translating it into the target language with the support of visual context. While recent Large Vision-Language Models (LVLMs) have demonstrated strong multilingual and visual understanding capabilities, there is a lack of systematic evaluation and understanding of their performance on VLT. In this work, we present a comprehensive study of VLT from three key perspectives: data quality, model architecture, and evaluation metrics. (1) We identify critical limitations in existing datasets, particularly in semantic and cultural fidelity, and introduce AibTrans -- a multilingual, parallel, human-verified dataset with OCR-corrected annotations. (2) We benchmark 11 commercial LVLMs/LLMs and 6 state-of-the-art open-source models across end-to-end and cascaded architectures, revealing their OCR dependency and contrasting generation versus reasoning behaviors. (3) We propose Density-Aware Evaluation to address metric reliability issues under varying contextual complexity, introducing the DA Score as a more robust measure of translation quality. Building upon these findings, we establish a new evaluation benchmark for VLT. Notably, we observe that fine-tuning LVLMs on high-resource language pairs degrades cross-lingual performance, and we propose a balanced multilingual fine-tuning strategy that effectively adapts LVLMs to VLT without sacrificing their generalization ability.
Chinese Toxic Language Mitigation via Sentiment Polarity Consistent Rewrites
May 21, 2025



Detoxifying offensive language while preserving the speaker's original intent is a challenging yet critical goal for improving the quality of online interactions. Although large language models (LLMs) show promise in rewriting toxic content, they often default to overly polite rewrites, distorting the emotional tone and communicative intent. This problem is especially acute in Chinese, where toxicity often arises implicitly through emojis, homophones, or discourse context. We present ToxiRewriteCN, the first Chinese detoxification dataset explicitly designed to preserve sentiment polarity. The dataset comprises 1,556 carefully annotated triplets, each containing a toxic sentence, a sentiment-aligned non-toxic rewrite, and labeled toxic spans. It covers five real-world scenarios: standard expressions, emoji-induced and homophonic toxicity, as well as single-turn and multi-turn dialogues. We evaluate 17 LLMs, including commercial and open-source models with variant architectures, across four dimensions: detoxification accuracy, fluency, content preservation, and sentiment polarity. Results show that while commercial and MoE models perform best overall, all models struggle to balance safety with emotional fidelity in more subtle or context-heavy settings such as emoji, homophone, and dialogue-based inputs. We release ToxiRewriteCN to support future research on controllable, sentiment-aware detoxification for Chinese.
Enhancing Trust Management System for Connected Autonomous Vehicles Using Machine Learning Methods: A Survey
May 10, 2025Connected Autonomous Vehicles (CAVs) operate in dynamic, open, and multi-domain networks, rendering them vulnerable to various threats. Trust Management Systems (TMS) systematically organize essential steps in the trust mechanism, identifying malicious nodes against internal threats and external threats, as well as ensuring reliable decision-making for more cooperative tasks. Recent advances in machine learning (ML) offer significant potential to enhance TMS, especially for the strict requirements of CAVs, such as CAV nodes moving at varying speeds, and opportunistic and intermittent network behavior. Those features distinguish ML-based TMS from social networks, static IoT, and Social IoT. This survey proposes a novel three-layer ML-based TMS framework for CAVs in the vehicle-road-cloud integration system, i.e., trust data layer, trust calculation layer and trust incentive layer. A six-dimensional taxonomy of objectives is proposed. Furthermore, the principles of ML methods for each module in each layer are analyzed. Then, recent studies are categorized based on traffic scenarios that are against the proposed objectives. Finally, future directions are suggested, addressing the open issues and meeting the research trend. We maintain an active repository that contains up-to-date literature and open-source projects at https://github.com/octoberzzzzz/ML-based-TMS-CAV-Survey.
WayFAST: Traversability Predictive Navigation for Field Robots
Mar 22, 2022

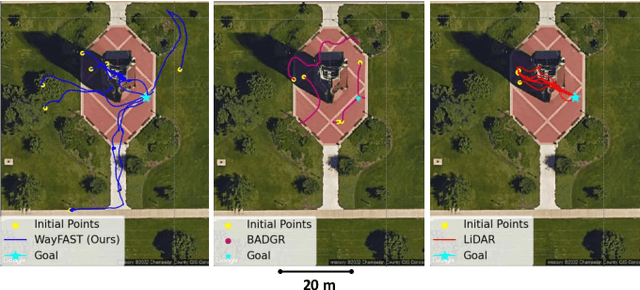

We present a self-supervised approach for learning to predict traversable paths for wheeled mobile robots that require good traction to navigate. Our algorithm, termed WayFAST (Waypoint Free Autonomous Systems for Traversability), uses RGB and depth data, along with navigation experience, to autonomously generate traversable paths in outdoor unstructured environments. Our key inspiration is that traction can be estimated for rolling robots using kinodynamic models. Using traction estimates provided by an online receding horizon estimator, we are able to train a traversability prediction neural network in a self-supervised manner, without requiring heuristics utilized by previous methods. We demonstrate the effectiveness of WayFAST through extensive field testing in varying environments, ranging from sandy dry beaches to forest canopies and snow covered grass fields. Our results clearly demonstrate that WayFAST can learn to avoid geometric obstacles as well as untraversable terrain, such as snow, which would be difficult to avoid with sensors that provide only geometric data, such as LiDAR. Furthermore, we show that our training pipeline based on online traction estimates is more data-efficient than other heuristic-based methods.