 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Robot Supervision to Hundreds of Hours with RoboTurk: Robotic Manipulation Dataset through Human Reasoning and Dexterity
Nov 11, 2019
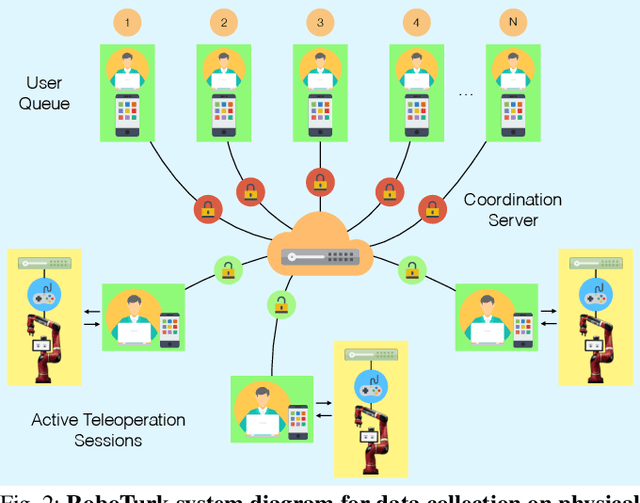

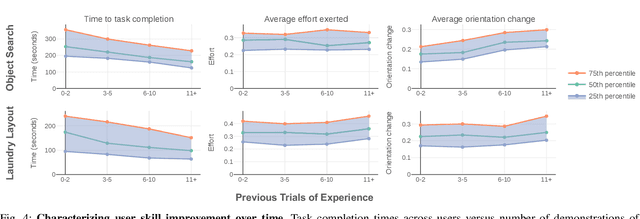
Large, richly annotated datasets have accelerated progress in fields such as computer vision and natural language processing, but replicating these successes in robotics has been challenging. While prior data collection methodologies such as self-supervision have resulted in large datasets, the data can have poor signal-to-noise ratio. By contrast, previous efforts to collect task demonstrations with humans provide better quality data, but they cannot reach the same data magnitude. Furthermore, neither approach places guarantees on the diversity of the data collected, in terms of solution strategies. In this work, we leverage and extend the RoboTurk platform to scale up data collection for robotic manipulation using remote teleoperation. The primary motivation for our platform is two-fold: (1) to address the shortcomings of prior work and increase the total quantity of manipulation data collected through human supervision by an order of magnitude without sacrificing the quality of the data and (2) to collect data on challenging manipulation tasks across several operators and observe a diverse set of emergent behaviors and solutions. We collected over 111 hours of robot manipulation data across 54 users and 3 challenging manipulation tasks in 1 week, resulting in the largest robot dataset collected via remote teleoperation. We evaluate the quality of our platform, the diversity of demonstrations in our dataset, and the utility of our dataset via quantitative and qualitative analysis. For additional results, supplementary videos, and to download our dataset, visit http://roboturk.stanford.edu/realrobotdataset .
KETO: Learning Keypoint Representations for Tool Manipulation
Oct 30, 2019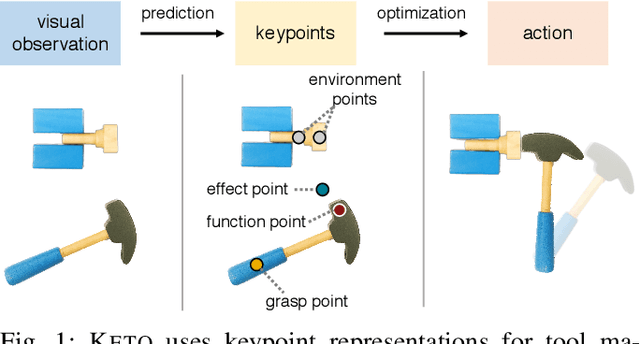
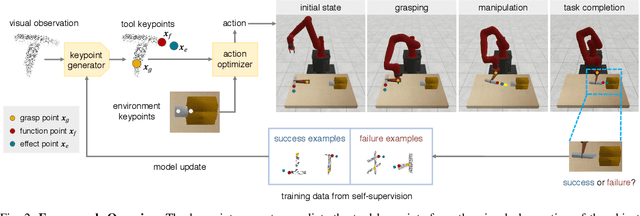
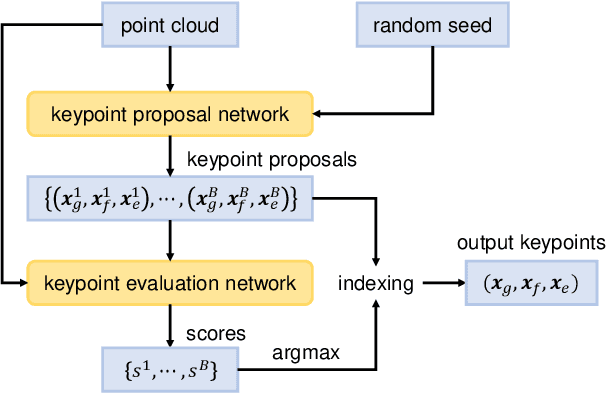
We aim to develop an algorithm for robots to manipulate novel objects as tools for completing different task goals. An efficient and informative representation would facilitate the effectiveness and generalization of such algorithms. For this purpose, we present KETO, a framework of learning keypoint representations of tool-based manipulation. For each task, a set of task-specific keypoints is jointly predicted from 3D point clouds of the tool object by a deep neural network. These keypoints offer a concise and informative description of the object to determine grasps and subsequent manipulation actions. The model is learned from self-supervised robot interactions in the task environment without the need for explicit human annotations. We evaluate our framework in three manipulation tasks with tool use. Our model consistently outperforms state-of-the-art methods in terms of task success rates. Qualitative results of keypoint prediction and tool generation are shown to visualize the learned representations.
Dynamics Learning with Cascaded Variational Inference for Multi-Step Manipulation
Oct 29, 2019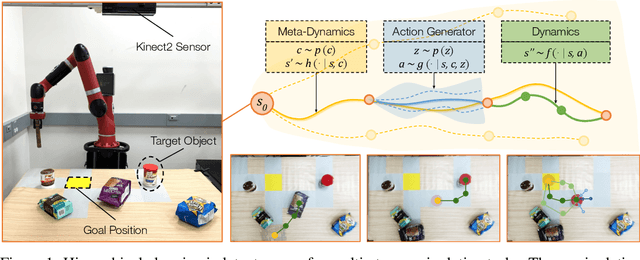
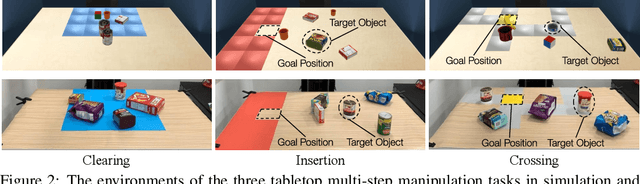
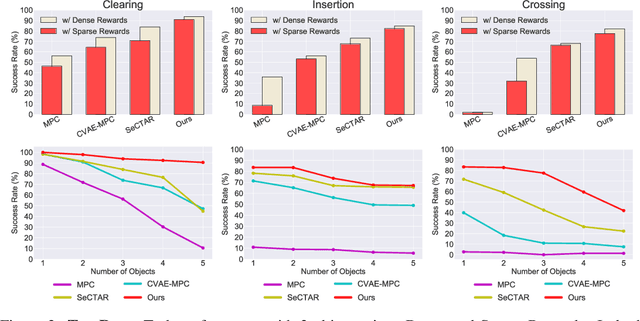

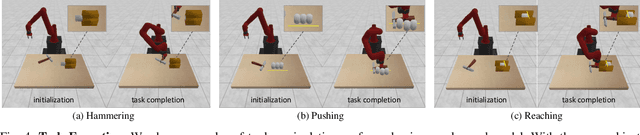
The fundamental challenge of planning for multi-step manipulation is to find effective and plausible action sequences that lead to the task goal. We present Cascaded Variational Inference (CAVIN) Planner, a model-based method that hierarchically generates plans by sampling from latent spaces. To facilitate planning over long time horizons, our method learns latent representations that decouple the prediction of high-level effects from the generation of low-level motions through cascaded variational inference. This enables us to model dynamics at two different levels of temporal resolutions for hierarchical planning. We evaluate our approach in three multi-step robotic manipulation tasks in cluttered tabletop environments given high-dimensional observations. Empirical results demonstrate that the proposed method outperforms state-of-the-art model-based methods by strategically interacting with multiple objects.
6-PACK: Category-level 6D Pose Tracker with Anchor-Based Keypoints
Oct 23, 2019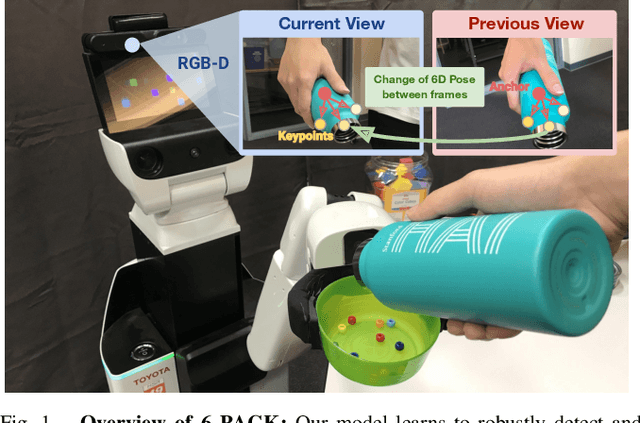
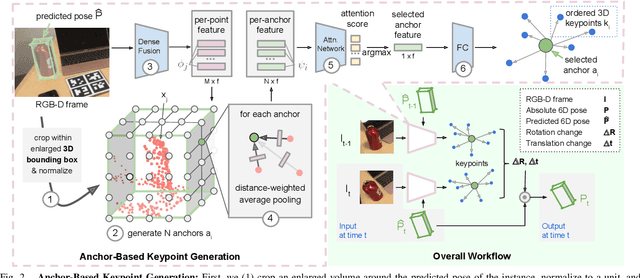
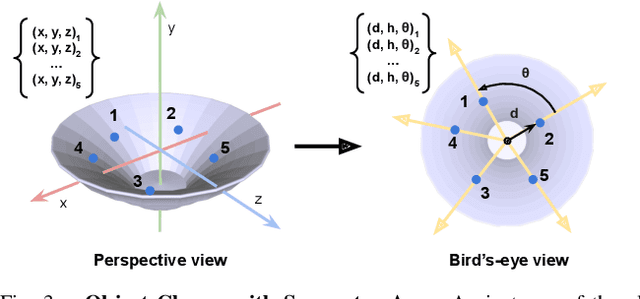
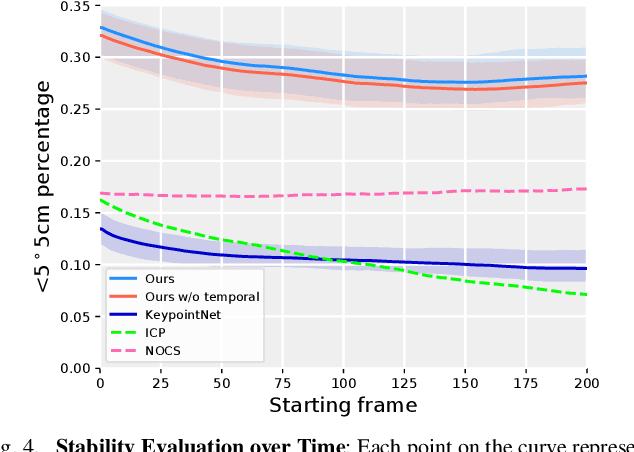
We present 6-PACK, a deep learning approach to category-level 6D object pose tracking on RGB-D data. Our method tracks in real-time novel object instances of known object categories such as bowls, laptops, and mugs. 6-PACK learns to compactly represent an object by a handful of 3D keypoints, based on which the interframe motion of an object instance can be estimated through keypoint matching. These keypoints are learned end-to-end without manual supervision in order to be most effective for tracking. Our experiments show that our method substantially outperforms existing methods on the NOCS category-level 6D pose estimation benchmark and supports a physical robot to perform simple vision-based closed-loop manipulation tasks. Our code and video are available at https://sites.google.com/view/6packtracking.
SURREAL-System: Fully-Integrated Stack for Distributed Deep Reinforcement Learning
Oct 11, 2019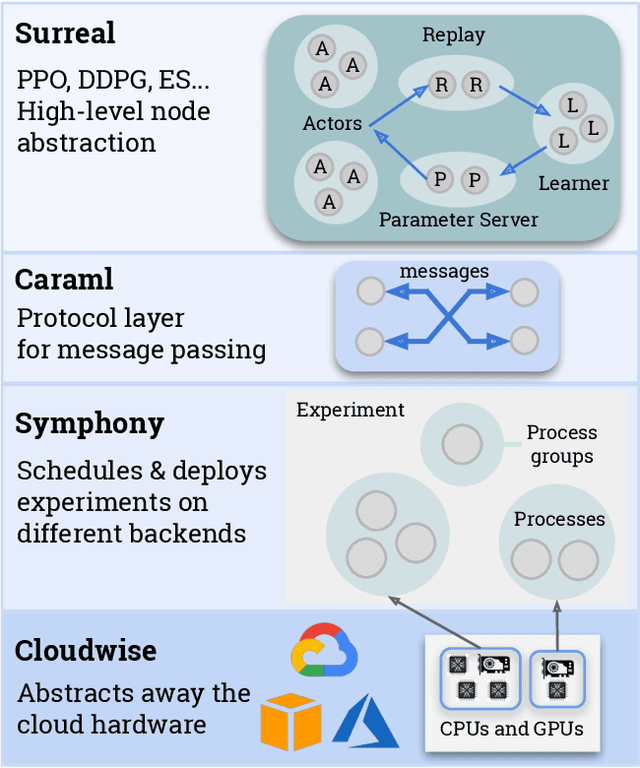

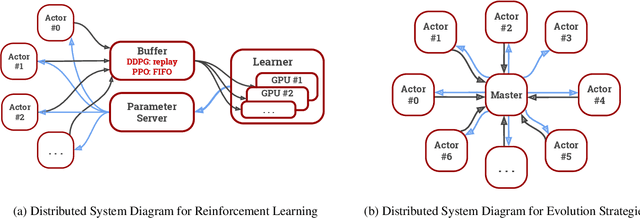
We present an overview of SURREAL-System, a reproducible, flexible, and scalable framework for distributed reinforcement learning (RL). The framework consists of a stack of four layers: Provisioner, Orchestrator, Protocol, and Algorithms. The Provisioner abstracts away the machine hardware and node pools across different cloud providers. The Orchestrator provides a unified interface for scheduling and deploying distributed algorithms by high-level description, which is capable of deploying to a wide range of hardware from a personal laptop to full-fledged cloud clusters. The Protocol provides network communication primitives optimized for RL. Finally, the SURREAL algorithms, such as Proximal Policy Optimization (PPO) and Evolution Strategies (ES), can easily scale to 1000s of CPU cores and 100s of GPUs. The learning performances of our distributed algorithms establish new state-of-the-art on OpenAI Gym and Robotics Suites tasks.
Bias-Resilient Neural Network
Oct 08, 2019
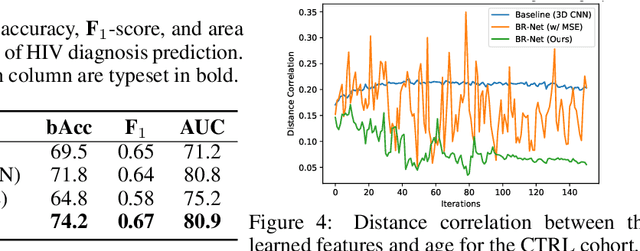
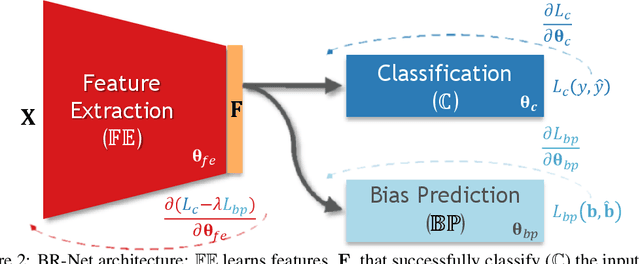

Presence of bias and confounding effects is inarguably one of the most critical challenges in machine learning applications that has alluded to pivotal debates in the recent years. Such challenges range from spurious associations of confounding variables in medical studies to the bias of race in gender or face recognition systems. One solution is to enhance datasets and organize them such that they do not reflect biases, which is a cumbersome and intensive task. The alternative is to make use of available data and build models considering these biases. Traditional statistical methods apply straightforward techniques such as residualization or stratification to precomputed features to account for confounding variables. However, these techniques are generally not suitable for end-to-end deep learning methods. In this paper, we propose a method based on the adversarial training strategy to learn discriminative features unbiased and invariant to the confounder(s). This is enabled by incorporating a new adversarial loss function that encourages a vanished correlation between the bias and learned features. We apply our method to synthetic data, medical images, and a gender classification (Gender Shades Pilot Parliaments Benchmark) dataset. Our results show that the learned features by our method not only result in superior prediction performance but also are uncorrelated with the bias or confounder variables. The code is available at http://github.com/QingyuZhao/BR-Net/.
Causal Induction from Visual Observations for Goal Directed Tasks
Oct 03, 2019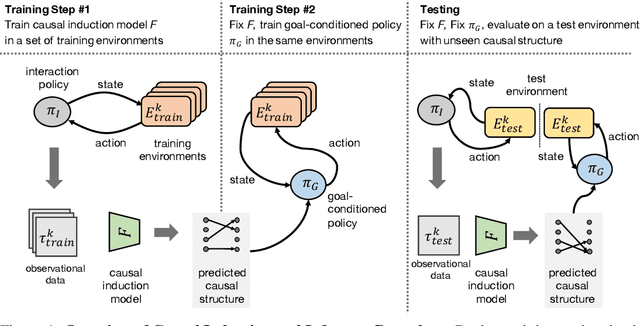
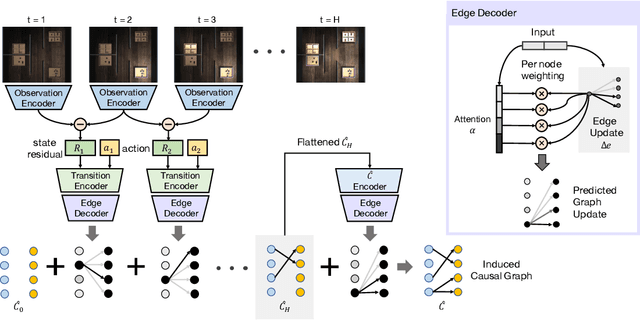
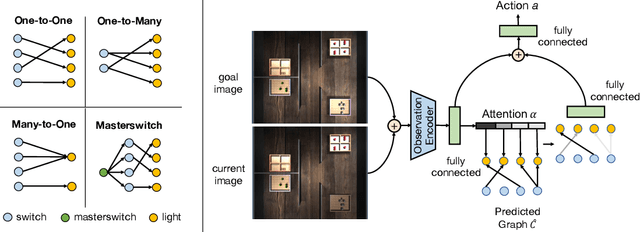
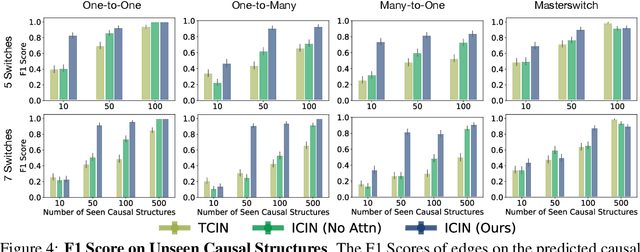
Causal reasoning has been an indispensable capability for humans and other intelligent animals to interact with the physical world. In this work, we propose to endow an artificial agent with the capability of causal reasoning for completing goal-directed tasks. We develop learning-based approaches to inducing causal knowledge in the form of directed acyclic graphs, which can be used to contextualize a learned goal-conditional policy to perform tasks in novel environments with latent causal structures. We leverage attention mechanisms in our causal induction model and goal-conditional policy, enabling us to incrementally generate the causal graph from the agent's visual observations and to selectively use the induced graph for determining actions. Our experiments show that our method effectively generalizes towards completing new tasks in novel environments with previously unseen causal structures.
Regression Planning Networks
Sep 28, 2019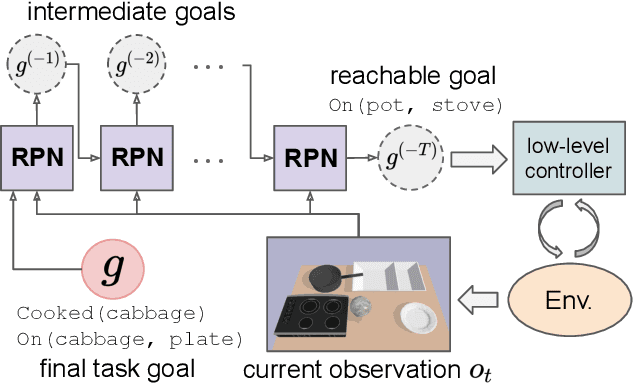
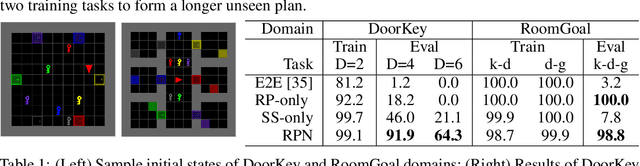
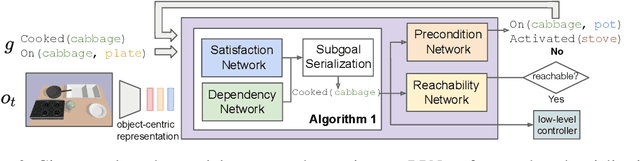
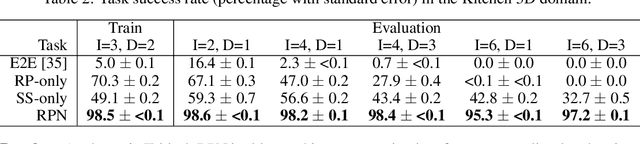
Recent learning-to-plan methods have shown promising results on planning directly from observation space. Yet, their ability to plan for long-horizon tasks is limited by the accuracy of the prediction model. On the other hand, classical symbolic planners show remarkable capabilities in solving long-horizon tasks, but they require predefined symbolic rules and symbolic states, restricting their real-world applicability. In this work, we combine the benefits of these two paradigms and propose a learning-to-plan method that can directly generate a long-term symbolic plan conditioned on high-dimensional observations. We borrow the idea of regression (backward) planning from classical planning literature and introduce Regression Planning Networks (RPN), a neural network architecture that plans backward starting at a task goal and generates a sequence of intermediate goals that reaches the current observation. We show that our model not only inherits many favorable traits from symbolic planning, e.g., the ability to solve previously unseen tasks but also can learn from visual inputs in an end-to-end manner. We evaluate the capabilities of RPN in a grid world environment and a simulated 3D kitchen environment featuring complex visual scenes and long task horizons, and show that it achieves near-optimal performance in completely new task instances.
Dual Sequential Monte Carlo: Tunneling Filtering and Planning in Continuous POMDPs
Sep 28, 2019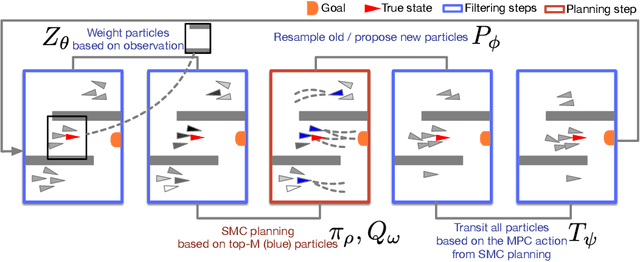
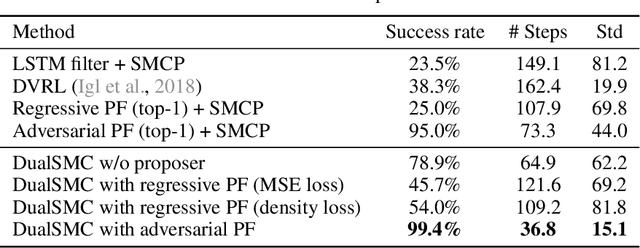
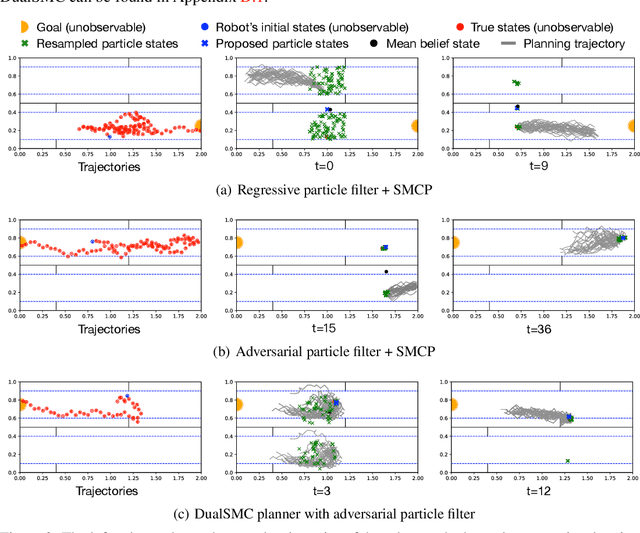

We present the DualSMC network that solves continuous POMDPs by learning belief representations and then leveraging them for planning. It is based on the fact that filtering, i.e. state estimation, and planning can be viewed as two related sequential Monte Carlo processes, with one in the belief space and the other in the future planning trajectory space. In particular, we first introduce a novel particle filter network that makes better use of the adversarial relationship between the proposer model and the observation model. We then introduce a new planning algorithm over the belief representations, which learns uncertainty-dependent policies. We allow these two parts to be trained jointly with each other. We testify the effectiveness of our approach on three continuous control and planning tasks: the floor positioning, the 3D light-dark navigation, and a modified Reacher task.
Situational Fusion of Visual Representation for Visual Navigation
Aug 24, 2019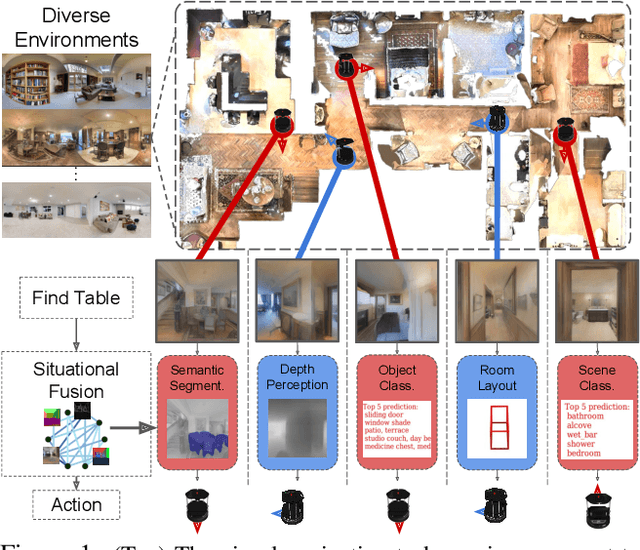

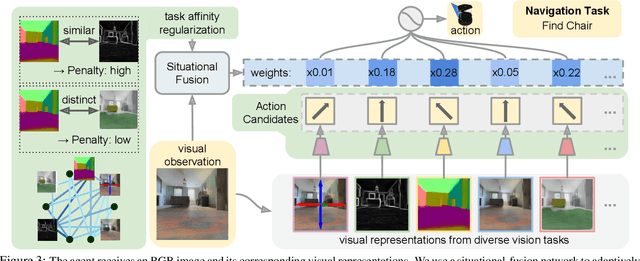
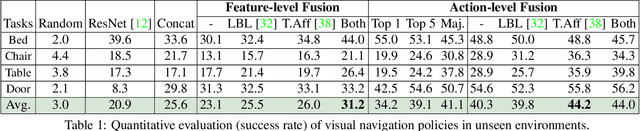
A complex visual navigation task puts an agent in different situations which call for a diverse range of visual perception abilities. For example, to "go to the nearest chair'', the agent might need to identify a chair in a living room using semantics, follow along a hallway using vanishing point cues, and avoid obstacles using depth. Therefore, utilizing the appropriate visual perception abilities based on a situational understanding of the visual environment can empower these navigation models in unseen visual environments. We propose to train an agent to fuse a large set of visual representations that correspond to diverse visual perception abilities. To fully utilize each representation, we develop an action-level representation fusion scheme, which predicts an action candidate from each representation and adaptively consolidate these action candidates into the final action. Furthermore, we employ a data-driven inter-task affinity regularization to reduce redundancies and improve generalization. Our approach leads to a significantly improved performance in novel environments over ImageNet-pretrained baseline and other fusion methods.