 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASSANDRA: Programmatic and Probabilistic Learning and Inference for Stochastic World Modeling
Jan 26, 2026Building world models is essential for planning in real-world domains such as businesses. Since such domains have rich semantics, we can leverage world knowledge to effectively model complex action effects and causal relationships from limited data. In this work, we propose CASSANDRA, a neurosymbolic world modeling approach that leverages an LLM as a knowledge prior to construct lightweight transition models for planning. CASSANDRA integrates two components: (1) LLM-synthesized code to model deterministic features, and (2) LLM-guided structure learning of a probabilistic graphical model to capture causal relationships among stochastic variables. We evaluate CASSANDRA in (i) a small-scale coffee-shop simulator and (ii) a complex theme park business simulator, where we demonstrate significant improvements in transition prediction and planning over baselines.
Library Learning Doesn't: The Curious Case of the Single-Use "Library"
Oct 26, 2024



Advances in Large Language Models (LLMs) have spurred a wave of LLM library learning systems for mathematical reasoning. These systems aim to learn a reusable library of tools, such as formal Isabelle lemmas or Python programs that are tailored to a family of tasks. Many of these systems are inspired by the human structuring of knowledge into reusable and extendable concepts, but do current methods actually learn reusable libraries of tools? We study two library learning systems for mathematics which both reported increased accuracy: LEGO-Prover and TroVE. We find that function reuse is extremely infrequent on miniF2F and MATH. Our followup ablation experiments suggest that, rather than reuse, self-correction and self-consistency are the primary drivers of the observed performance gains. Our code and data are available at https://github.com/ikb-a/curious-case
Attribute Diversity Determines the Systematicity Gap in VQA
Nov 15, 2023



The degree to which neural networks can generalize to new combinations of familiar concepts, and the conditions under which they are able to do so, has long been an open question. In this work, we study the systematicity gap in visual question answering: the performance difference between reasoning on previously seen and unseen combinations of object attributes. To test, we introduce a novel diagnostic dataset, CLEVR-HOPE. We find that while increased quantity of training data does not reduce the systematicity gap, increased training data diversity of the attributes in the unseen combination does. In all, our experiments suggest that the more distinct attribute type combinations are seen during training, the more systematic we can expect the resulting model to be.
Relevance in Dialogue: Is Less More? An Empirical Comparison of Existing Metrics, and a Novel Simple Metric
Jun 03, 2022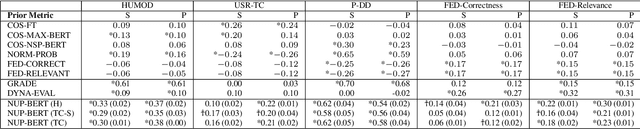

In this work, we evaluate various existing dialogue relevance metrics, find strong dependency on the dataset, often with poor correlation with human scores of relevance, and propose modifications to reduce data requirements and domain sensitivity while improving correlation. Our proposed metric achieves state-of-the-art performance on the HUMOD dataset while reducing measured sensitivity to dataset by 37%-66%. We achieve this without fine-tuning a pretrained language model, and using only 3,750 unannotated human dialogues and a single negative example. Despite these limitations, we demonstrate competitive performance on four datasets from different domains. Our code, including our metric and experiments, is open sourced.
* 18 pages, 7 figures
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Neuro-Symbolic VQA: A review from the perspective of AGI desiderata
Apr 13, 2021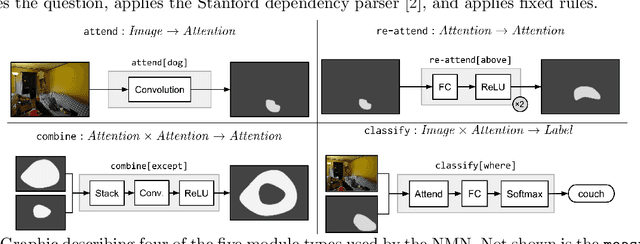
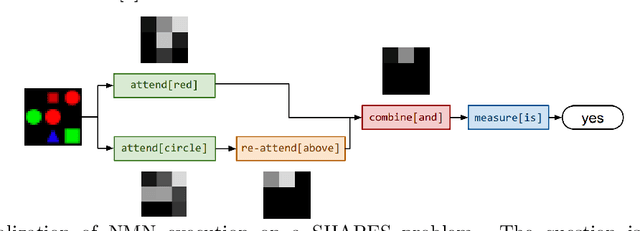


An ultimate goal of the AI and ML fields is artificial general intelligence (AGI); although such systems remain science fiction, various models exhibit aspects of AGI. In this work, we look at neuro-symbolic (NS)approaches to visual question answering (VQA) from the perspective of AGI desiderata. We see how well these systems meet these desiderata, and how the desiderata often pull the scientist in opposing directions. It is my hope that through this work we can temper model evaluation on benchmarks with a discussion of the properties of these systems and their potential for future extension.
On the Use of Linguistic Features for the Evaluation of Generative Dialogue Systems
Apr 13, 2021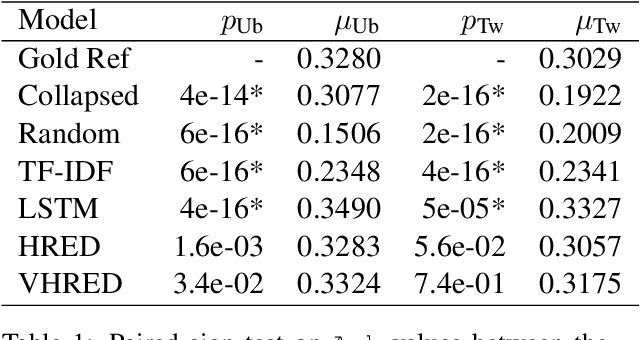
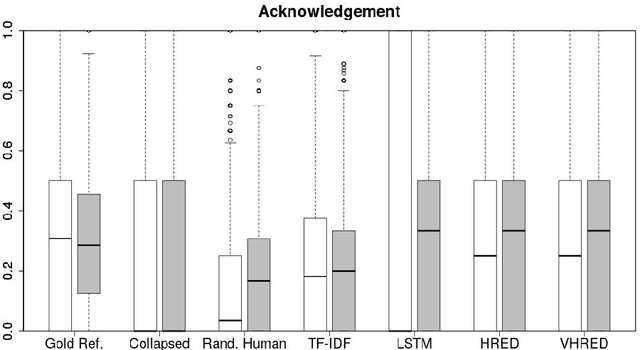
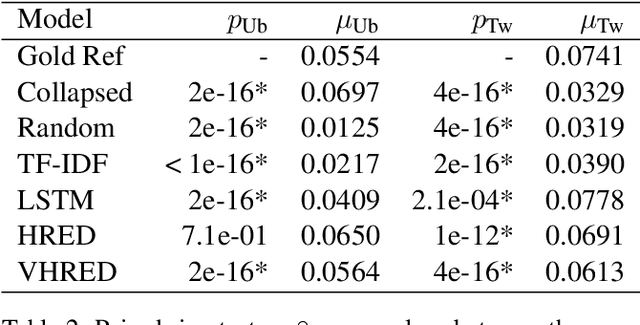
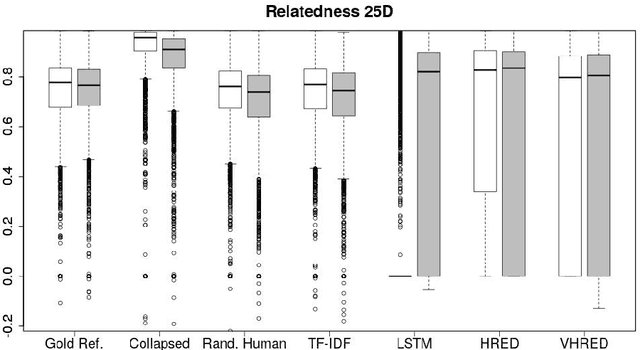
Automatically evaluating text-based, non-task-oriented dialogue systems (i.e., `chatbots') remains an open problem. Previous approaches have suffered challenges ranging from poor correlation with human judgment to poor generalization and have often required a gold standard reference for comparison or human-annotated data. Extending existing evaluation methods, we propose that a metric based on linguistic features may be able to maintain good correlation with human judgment and be interpretable, without requiring a gold-standard reference or human-annotated data. To support this proposition, we measure and analyze various linguistic features on dialogues produced by multiple dialogue models. We find that the features' behaviour is consistent with the known properties of the models tested, and is similar across domains. We also demonstrate that this approach exhibits promising properties such as zero-shot generalization to new domains on the related task of evaluating response relevance.