 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Predictive Simulation Using Structured Graphical Models and Transformers
Jun 28, 2024We propose an approach to simulating trajectories of multiple interacting agents (road users) based on transformers and probabilistic graphical models (PGMs), and apply it to the Waymo SimAgents challenge. The transformer baseline is based on the MTR model, which predicts multiple future trajectories conditioned on the past trajectories and static road layout features. We then improve upon these generated trajectories using a PGM, which contains factors which encode prior knowledge, such as a preference for smooth trajectories, and avoidance of collisions with static obstacles and other moving agents. We perform (approximate) MAP inference in this PGM using the Gauss-Newton method. Finally we sample $K=32$ trajectories for each of the $N \sim 100$ agents for the next $T=8 \Delta$ time steps, where $\Delta=10$ is the sampling rate per second. Following the Model Predictive Control (MPC) paradigm, we only return the first element of our forecasted trajectories at each step, and then we replan, so that the simulation can constantly adapt to its changing environment. We therefore call our approach "Model Predictive Simulation" or MPS. We show that MPS improves upon the MTR baseline, especially in safety critical metrics such as collision rate. Furthermore, our approach is compatible with any underlying forecasting model, and does not require extra training, so we believe it is a valuable contribution to the community.
Bayesian Online Natural Gradient (BONG)
May 30, 2024We propose a novel approach to sequential Bayesian inference based on variational Bayes. The key insight is that, in the online setting, we do not need to add the KL term to regularize to the prior (which comes from the posterior at the previous timestep); instead we can optimize just the expected log-likelihood, performing a single step of natural gradient descent starting at the prior predictive. We prove this method recovers exact Bayesian inference if the model is conjugate, and empirically outperforms other online VB methods in the non-conjugate setting, such as online learning for neural networks, especially when controlling for computational costs.
Outlier-robust Kalman Filtering through Generalised Bayes
May 09, 2024We derive a novel, provably robust, and closed-form Bayesian update rule for online filtering in state-space models in the presence of outliers and misspecified measurement models. Our method combines generalised Bayesian inference with filtering methods such as the extended and ensemble Kalman filter. We use the former to show robustness and the latter to ensure computational efficiency in the case of nonlinear models. Our method matches or outperforms other robust filtering methods (such as those based on variational Bayes) at a much lower computational cost. We show this empirically on a range of filtering problems with outlier measurements, such as object tracking, state estimation in high-dimensional chaotic systems, and online learning of neural networks.
Cooperative Modular Manipulation with Numerous Cable-Driven Robots for Assistive Construction and Gap Crossing
Mar 19, 2024



Soldiers in the field often need to cross negative obstacles, such as rivers or canyons, to reach goals or safety. Military gap crossing involves on-site temporary bridges construction. However, this procedure is conducted with dangerous, time and labor intensive operations, and specialized machinery. We envision a scalable robotic solution inspired by advancements in force-controlled and Cable Driven Parallel Robots (CDPRs); this solution can address the challenges inherent in this transportation problem, achieving fast, efficient, and safe deployment and field operations. We introduce the embodied vision in Co3MaNDR, a solution to the military gap crossing problem, a distributed robot consisting of several modules simultaneously pulling on a central payload, controlling the cables' tensions to achieve complex objectives, such as precise trajectory tracking or force amplification. Hardware experiments demonstrate teleoperation of a payload, trajectory following, and the sensing and amplification of operators' applied physical forces during slow operations. An operator was shown to manipulate a 27.2 kg (60 lb) payload with an average force utilization of 14.5\% of its weight. Results indicate that the system can be scaled up to heavier payloads without compromising performance or introducing superfluous complexity. This research lays a foundation to expand CDPR technology to uncoordinated and unstable mobile platforms in unknown environments.
BlackJAX: Composable Bayesian inference in JAX
Feb 22, 2024BlackJAX is a library implementing sampling and variational inference algorithms commonly used in Bayesian computation. It is designed for ease of use, speed, and modularity by taking a functional approach to the algorithms' implementation. BlackJAX is written in Python, using JAX to compile and run NumpPy-like samplers and variational methods on CPUs, GPUs, and TPUs. The library integrates well with probabilistic programming languages by working directly with the (un-normalized) target log density function. BlackJAX is intended as a collection of low-level, composable implementations of basic statistical 'atoms' that can be combined to perform well-defined Bayesian inference, but also provides high-level routines for ease of use. It is designed for users who need cutting-edge methods, researchers who want to create complex sampling methods, and people who want to learn how these work.
SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs
Jul 03, 2023



In this work, we introduce Semantic Pyramid AutoEncoder (SPAE) for enabling frozen LLMs to perform both understanding and generation tasks involving non-linguistic modalities such as images or videos. SPAE converts between raw pixels and interpretable lexical tokens (or words) extracted from the LLM's vocabulary. The resulting tokens capture both the semantic meaning and the fine-grained details needed for visual reconstruction, effectively translating the visual content into a language comprehensible to the LLM, and empowering it to perform a wide array of multimodal tasks. Our approach is validated through in-context learning experiments with frozen PaLM 2 and GPT 3.5 on a diverse set of image understanding and generation tasks. Our method marks the first successful attempt to enable a frozen LLM to generate image content while surpassing state-of-the-art performance in image understanding tasks, under the same setting, by over 25%.
Low-rank extended Kalman filtering for online learning of neural networks from streaming data
May 31, 2023



We propose an efficient online approximate Bayesian inference algorithm for estimating the parameters of a nonlinear function from a potentially non-stationary data stream. The method is based on the extended Kalman filter (EKF), but uses a novel low-rank plus diagonal decomposition of the posterior precision matrix, which gives a cost per step which is linear in the number of model parameters. In contrast to methods based on stochastic variational inference, our method is fully deterministic, and does not require step-size tuning. We show experimentally that this results in much faster (more sample efficient) learning, which results in more rapid adaptation to changing distributions, and faster accumulation of reward when used as part of a contextual bandit algorithm.
Muse: Text-To-Image Generation via Masked Generative Transformers
Jan 02, 2023



We present Muse, a text-to-image Transformer model that achieves state-of-the-art image generation performance while being significantly more efficient than diffusion or autoregressive models. Muse is trained on a masked modeling task in discrete token space: given the text embedding extracted from a pre-trained large language model (LLM), Muse is trained to predict randomly masked image tokens. Compared to pixel-space diffusion models, such as Imagen and DALL-E 2, Muse is significantly more efficient due to the use of discrete tokens and requiring fewer sampling iterations; compared to autoregressive models, such as Parti, Muse is more efficient due to the use of parallel decoding. The use of a pre-trained LLM enables fine-grained language understanding, translating to high-fidelity image generation and the understanding of visual concepts such as objects, their spatial relationships, pose, cardinality etc. Our 900M parameter model achieves a new SOTA on CC3M, with an FID score of 6.06. The Muse 3B parameter model achieves an FID of 7.88 on zero-shot COCO evaluation, along with a CLIP score of 0.32. Muse also directly enables a number of image editing applications without the need to fine-tune or invert the model: inpainting, outpainting, and mask-free editing. More results are available at https://muse-model.github.io
Beyond Invariance: Test-Time Label-Shift Adaptation for Distributions with "Spurious" Correlations
Nov 28, 2022Spurious correlations, or correlations that change across domains where a model can be deployed, present significant challenges to real-world applications of machine learning models. However, such correlations are not always "spurious"; often, they provide valuable prior information for a prediction beyond what can be extracted from the input alone. Here, we present a test-time adaptation method that exploits the spurious correlation phenomenon, in contrast to recent approaches that attempt to eliminate spurious correlations through invariance. We consider situations where the prior distribution $p(y, z)$, which models the marginal dependence between the class label $y$ and the nuisance factors $z$, may change across domains, but the generative model for features $p(\mathbf{x}|y, z)$ is constant. We note that this is an expanded version of the label shift assumption, where the labels now also include the nuisance factors $z$. Based on this observation, we train a classifier to predict $p(y, z|\mathbf{x})$ on the source distribution, and implement a test-time label shift correction that adapts to changes in the marginal distribution $p(y, z)$ using unlabeled samples from the target domain. We call our method "Test-Time Label-Shift Adaptation" or TTLSA. We apply our method to two different image datasets -- the CheXpert chest X-ray dataset and the colored MNIST dataset -- and show that it gives better downstream results than methods that try to train classifiers which are invariant to the changes in prior distribution. Code reproducing experiments is available at https://github.com/nalzok/test-time-label-shift .
Language Model Cascades
Jul 28, 2022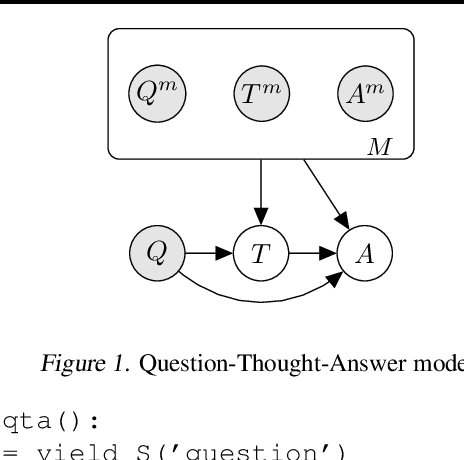
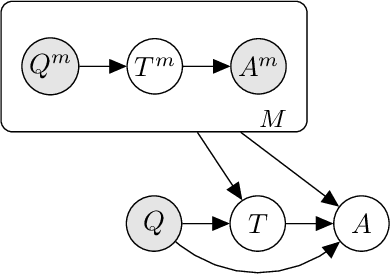
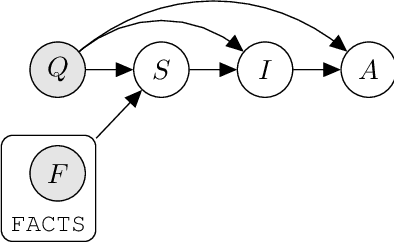
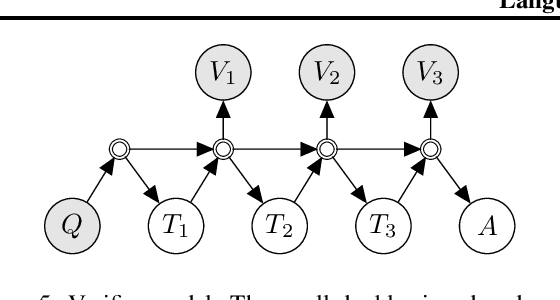
Prompted models have demonstrated impressive few-shot learning abilities. Repeated interactions at test-time with a single model, or the composition of multiple models together, further expands capabilities. These compositions are probabilistic models, and may be expressed in the language of graphical models with random variables whose values are complex data types such as strings. Cases with control flow and dynamic structure require techniques from probabilistic programming, which allow implementing disparate model structures and inference strategies in a unified language. We formalize several existing techniques from this perspective, including scratchpads / chain of thought, verifiers, STaR, selection-inference, and tool use. We refer to the resulting programs as language model cascades.