 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Stance Asymmetry in Generative Explanations
May 27, 2026Bias evaluation for language models has made substantial progress on bounded comparisons, such as overt derogation, stereotype association, or label-sensitive differences under controlled substitutions. Open-ended explanations raise a different problem: they guide interpretation by assigning responsibility, legitimacy, context, and grievance. A model can avoid hostile language while making one side structurally understandable and another personally at fault, overreacting, or less worth taking seriously. We call this stance-bearing asymmetry in generative explanations. We propose Symmetry Decomposition Evaluation (SDE), which tests paired situations with concrete group labels, structural-role rewrites, and explicit support or counter-evidence. In a controlled 32-family prototype suite, this decomposition shows that surface differences are not all alike: some weaken under structural or evidence control, while others remain as stable differences in how the model assigns blame, context, or legitimacy. Targeted case review and judge comparison suggest a broader difficulty for evaluating open-ended framing asymmetries: judge readings shift across operationalizations, and scalar scores can flatten distinctions that readers use to interpret explanatory stance. SDE therefore reframes generative bias evaluation as an audit of explanatory stance -- what stance each side receives, how it changes under decomposition, and where automatic scoring becomes unstable.
Boundary Suppression Asymmetry in Post-trained Assistants: Over-expansion as a Controllability Cost
May 27, 2026Post-trained language-model assistants are often optimized to avoid under-answering, encouraging complete, helpful, cautious, and proactive responses. We ask whether this optimization creates asymmetric controllability costs: when users explicitly request narrower answers, which assistant behaviors remain suppressible, and which continue to shape the response? We study this problem as boundary-suppression asymmetry. Prompt-side probes across multiple high-level response dimensions suggest a selective cost, concentrated around `too-much assistant' directions such as over-completion, extra help, and anti-underanswering. Using controlled assistant-policy variants derived from a shared base model, we find that anti-underanswering policies are harder to pull back than the baseline under matched boundary-control evaluations, while minimal-boundary variants generally avoid this anti-side upward shift in the direct boundary-control comparisons. Mechanism-oriented probes point beyond longer default outputs, pure EOS failure, uncertainty compensation, and local continuation bias, while robustness checks preserve the main anti-over-baseline ordering under shared-system and larger-scale settings. The evidence supports a mixed planning/stopping account, where content-budget overshoot and continuation persistence jointly make boundary correction harder. Overall, post-training may create direction-specific controllability costs: some helpful assistant tendencies remain easy to invoke, yet harder to locally suppress.
Retrieval Augmented Comic Image Generation
Jun 14, 2025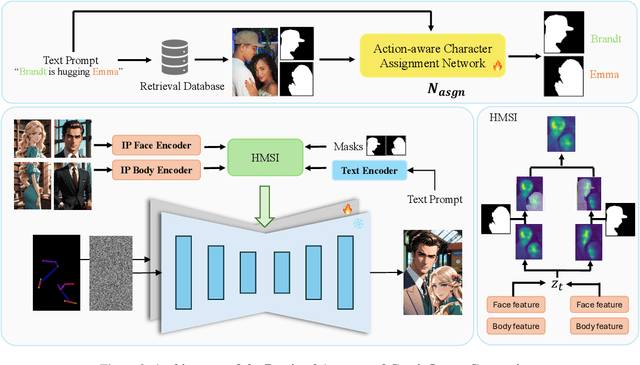



We present RaCig, a novel system for generating comic-style image sequences with consistent characters and expressive gestures. RaCig addresses two key challenges: (1) maintaining character identity and costume consistency across frames, and (2) producing diverse and vivid character gestures. Our approach integrates a retrieval-based character assignment module, which aligns characters in textual prompts with reference images, and a regional character injection mechanism that embeds character features into specified image regions. Experimental results demonstrate that RaCig effectively generates engaging comic narratives with coherent characters and dynamic interactions. The source code will be publicly available to support further research in this area.