 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDePlot: One-shot visual language reasoning by plot-to-table translation
Dec 20, 2022



Visual language such as charts and plots is ubiquitous in the human world. Comprehending plots and charts requires strong reasoning skills. Prior state-of-the-art (SOTA) models require at least tens of thousands of training examples and their reasoning capabilities are still much limited, especially on complex human-written queries. This paper presents the first one-shot solution to visual language reasoning. We decompose the challenge of visual language reasoning into two steps: (1) plot-to-text translation, and (2) reasoning over the translated text. The key in this method is a modality conversion module, named as DePlot, which translates the image of a plot or chart to a linearized table. The output of DePlot can then be directly used to prompt a pretrained large language model (LLM), exploiting the few-shot reasoning capabilities of LLMs. To obtain DePlot, we standardize the plot-to-table task by establishing unified task formats and metrics, and train DePlot end-to-end on this task. DePlot can then be used off-the-shelf together with LLMs in a plug-and-play fashion. Compared with a SOTA model finetuned on more than >28k data points, DePlot+LLM with just one-shot prompting achieves a 24.0% improvement over finetuned SOTA on human-written queries from the task of chart QA.
MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering
Dec 19, 2022



Visual language data such as plots, charts, and infographics are ubiquitous in the human world. However, state-of-the-art vision-language models do not perform well on these data. We propose MatCha (Math reasoning and Chart derendering pretraining) to enhance visual language models' capabilities in jointly modeling charts/plots and language data. Specifically, we propose several pretraining tasks that cover plot deconstruction and numerical reasoning which are the key capabilities in visual language modeling. We perform the MatCha pretraining starting from Pix2Struct, a recently proposed image-to-text visual language model. On standard benchmarks such as PlotQA and ChartQA, the MatCha model outperforms state-of-the-art methods by as much as nearly 20%. We also examine how well MatCha pretraining transfers to domains such as screenshots, textbook diagrams, and document figures and observe overall improvement, verifying the usefulness of MatCha pretraining on broader visual language tasks.
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
Oct 07, 2022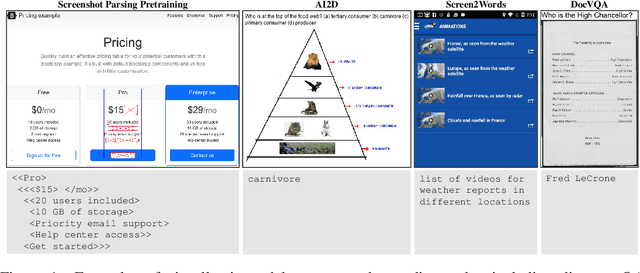


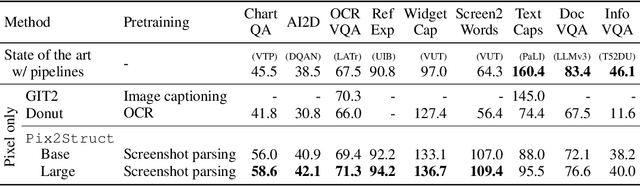
Visually-situated language is ubiquitous -- sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and forms. Perhaps due to this diversity, previous work has typically relied on domain-specific recipes with limited sharing of the underlying data, model architectures, and objectives. We present Pix2Struct, a pretrained image-to-text model for purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy, we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions are rendered directly on top of the input image. For the first time, we show that a single pretrained model can achieve state-of-the-art results in six out of nine tasks across four domains: documents, illustrations, user interfaces, and natural images.
Generating recommendations for entity-oriented exploratory search
Apr 02, 2022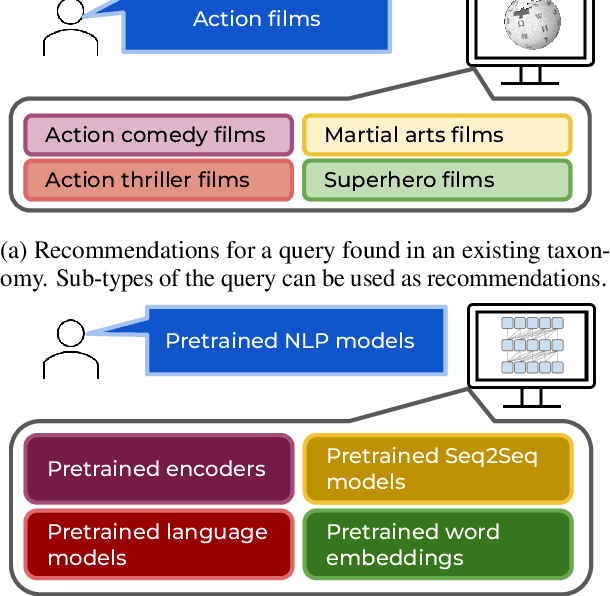
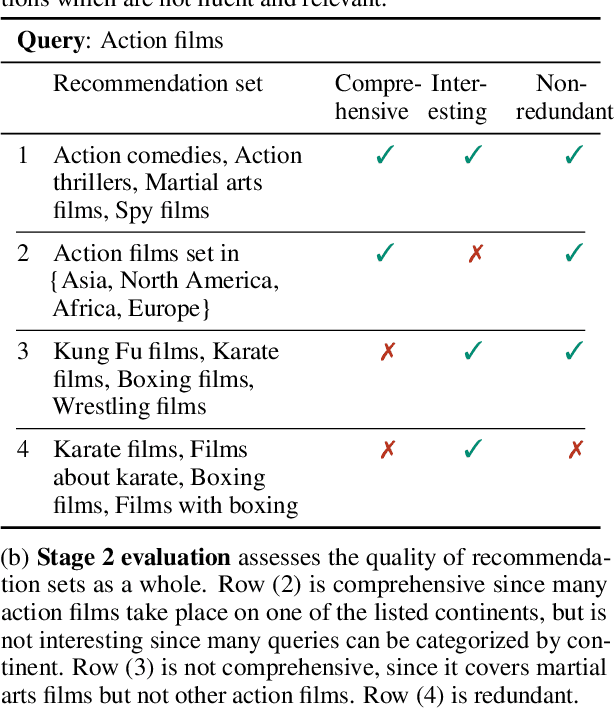
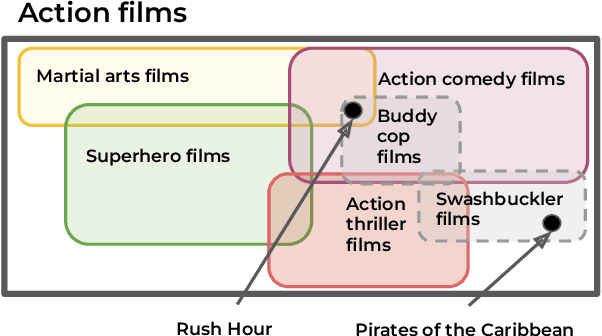

We introduce the task of recommendation set generation for entity-oriented exploratory search. Given an input search query which is open-ended or under-specified, the task is to present the user with an easily-understandable collection of query recommendations, with the goal of facilitating domain exploration or clarifying user intent. Traditional query recommendation systems select recommendations by identifying salient keywords in retrieved documents, or by querying an existing taxonomy or knowledge base for related concepts. In this work, we build a text-to-text model capable of generating a collection of recommendations directly, using the language model as a "soft" knowledge base capable of proposing new concepts not found in an existing taxonomy or set of retrieved documents. We train the model to generate recommendation sets which optimize a cost function designed to encourage comprehensiveness, interestingness, and non-redundancy. In thorough evaluations performed by crowd workers, we confirm the generalizability of our approach and the high quality of the generated recommendations.
Revisiting the Primacy of English in Zero-shot Cross-lingual Transfer
Jun 30, 2021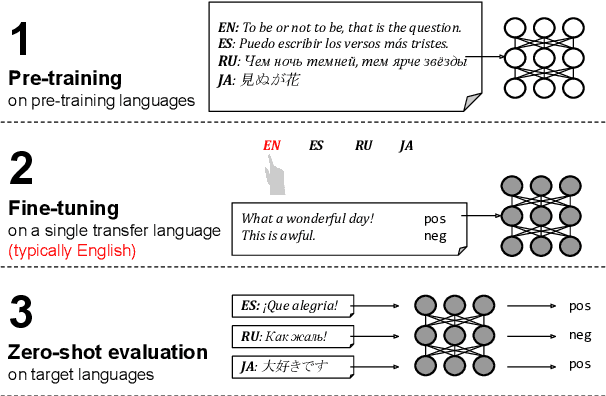
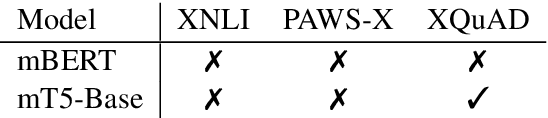
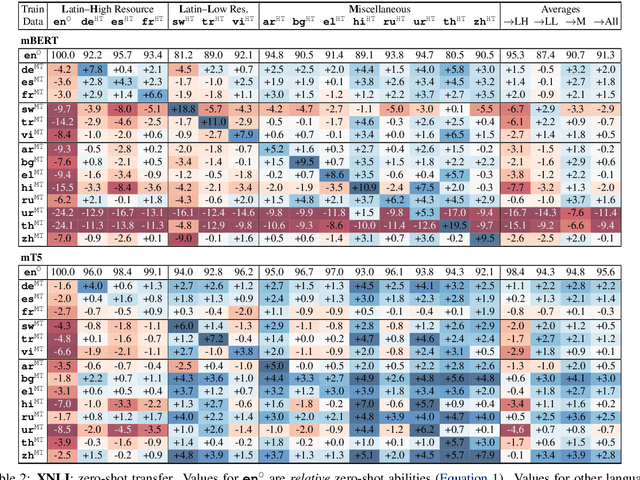
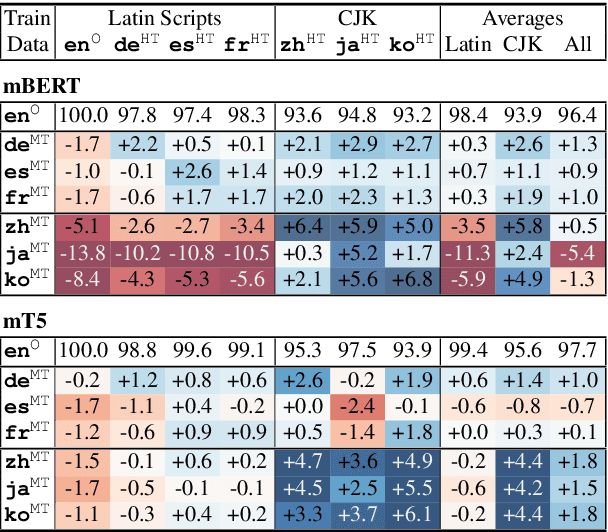
Despite their success, large pre-trained multilingual models have not completely alleviated the need for labeled data, which is cumbersome to collect for all target languages. Zero-shot cross-lingual transfer is emerging as a practical solution: pre-trained models later fine-tuned on one transfer language exhibit surprising performance when tested on many target languages. English is the dominant source language for transfer, as reinforced by popular zero-shot benchmarks. However, this default choice has not been systematically vetted. In our study, we compare English against other transfer languages for fine-tuning, on two pre-trained multilingual models (mBERT and mT5) and multiple classification and question answering tasks. We find that other high-resource languages such as German and Russian often transfer more effectively, especially when the set of target languages is diverse or unknown a priori. Unexpectedly, this can be true even when the training sets were automatically translated from English. This finding can have immediate impact on multilingual zero-shot systems, and should inform future benchmark designs.
Joint Passage Ranking for Diverse Multi-Answer Retrieval
Apr 17, 2021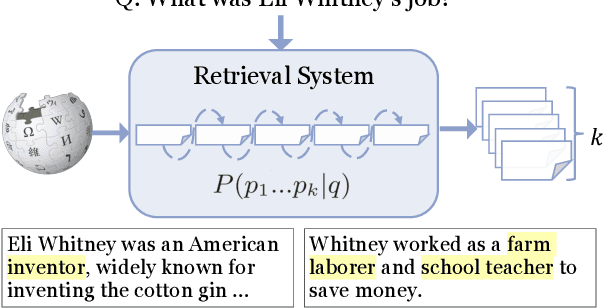

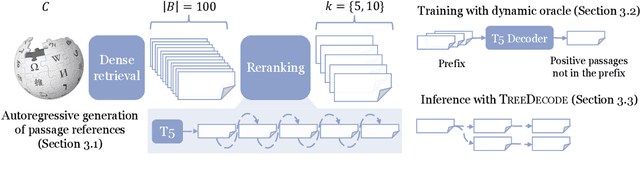
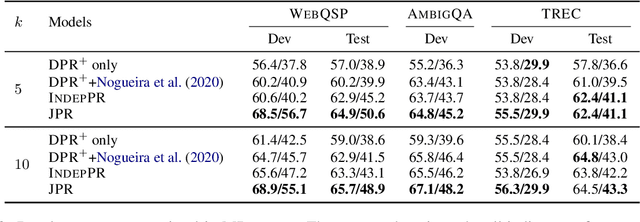
We study multi-answer retrieval, an under-explored problem that requires retrieving passages to cover multiple distinct answers for a given question. This task requires joint modeling of retrieved passages, as models should not repeatedly retrieve passages containing the same answer at the cost of missing a different valid answer. Prior work focusing on single-answer retrieval is limited as it cannot reason about the set of passages jointly. In this paper, we introduce JPR, a joint passage retrieval model focusing on reranking. To model the joint probability of the retrieved passages, JPR makes use of an autoregressive reranker that selects a sequence of passages, equipped with novel training and decoding algorithms. Compared to prior approaches, JPR achieves significantly better answer coverage on three multi-answer datasets. When combined with downstream question answering, the improved retrieval enables larger answer generation models since they need to consider fewer passages, establishing a new state-of-the-art.
Neural Data Augmentation via Example Extrapolation
Feb 02, 2021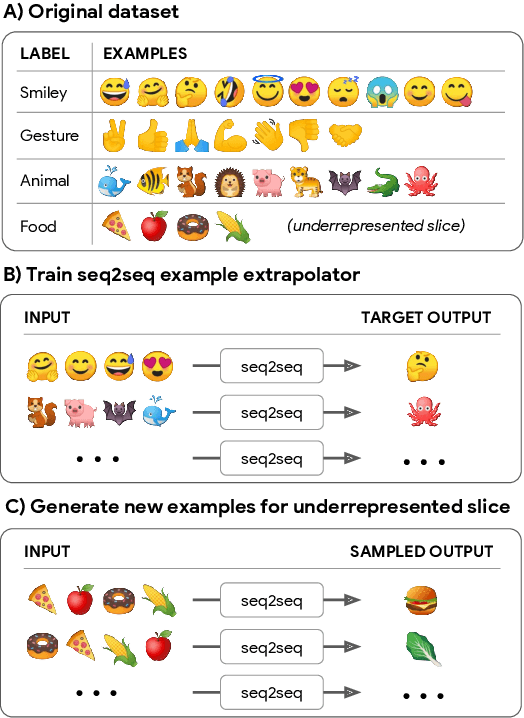

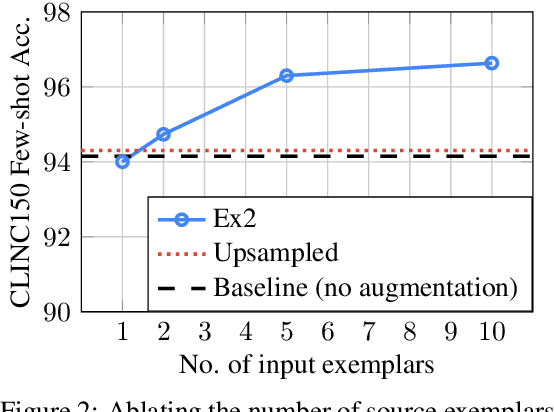
In many applications of machine learning, certain categories of examples may be underrepresented in the training data, causing systems to underperform on such "few-shot" cases at test time. A common remedy is to perform data augmentation, such as by duplicating underrepresented examples, or heuristically synthesizing new examples. But these remedies often fail to cover the full diversity and complexity of real examples. We propose a data augmentation approach that performs neural Example Extrapolation (Ex2). Given a handful of exemplars sampled from some distribution, Ex2 synthesizes new examples that also belong to the same distribution. The Ex2 model is learned by simulating the example generation procedure on data-rich slices of the data, and it is applied to underrepresented, few-shot slices. We apply Ex2 to a range of language understanding tasks and significantly improve over state-of-the-art methods on multiple few-shot learning benchmarks, including for relation extraction (FewRel) and intent classification + slot filling (SNIPS).
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021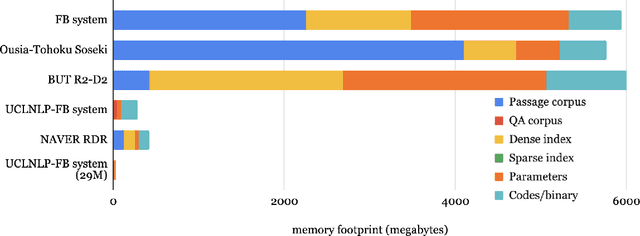
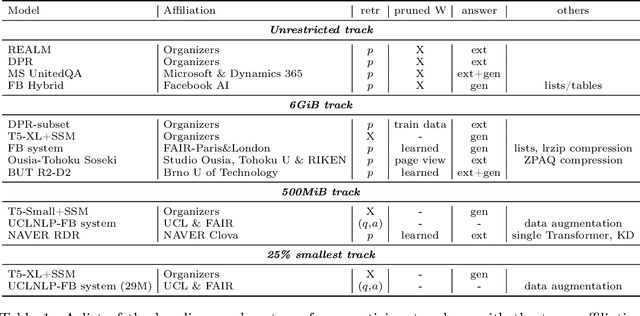
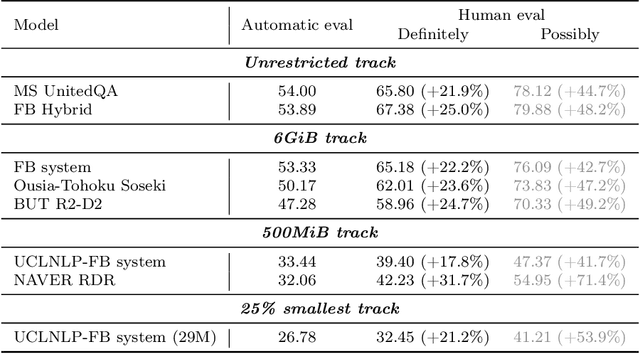
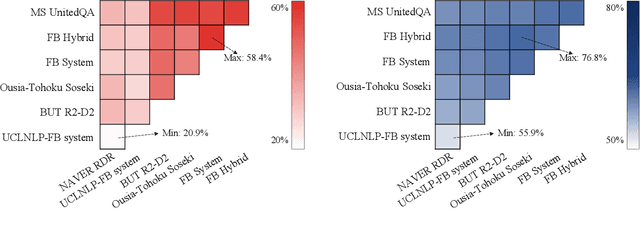
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
CapWAP: Captioning with a Purpose
Nov 09, 2020

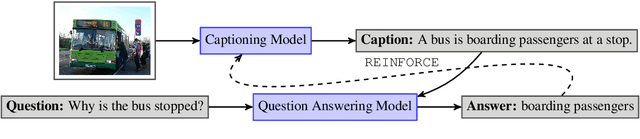

The traditional image captioning task uses generic reference captions to provide textual information about images. Different user populations, however, will care about different visual aspects of images. In this paper, we propose a new task, Captioning with a Purpose (CapWAP). Our goal is to develop systems that can be tailored to be useful for the information needs of an intended population, rather than merely provide generic information about an image. In this task, we use question-answer (QA) pairs---a natural expression of information need---from users, instead of reference captions, for both training and post-inference evaluation. We show that it is possible to use reinforcement learning to directly optimize for the intended information need, by rewarding outputs that allow a question answering model to provide correct answers to sampled user questions. We convert several visual question answering datasets into CapWAP datasets, and demonstrate that under a variety of scenarios our purposeful captioning system learns to anticipate and fulfill specific information needs better than its generic counterparts, as measured by QA performance on user questions from unseen images, when using the caption alone as context.
XOR QA: Cross-lingual Open-Retrieval Question Answering
Oct 24, 2020
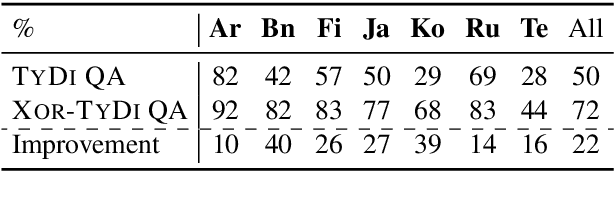
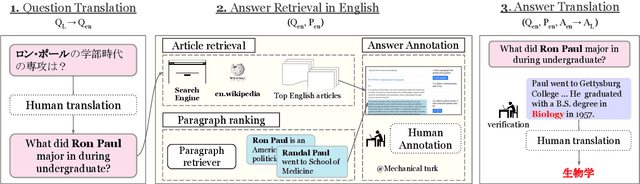
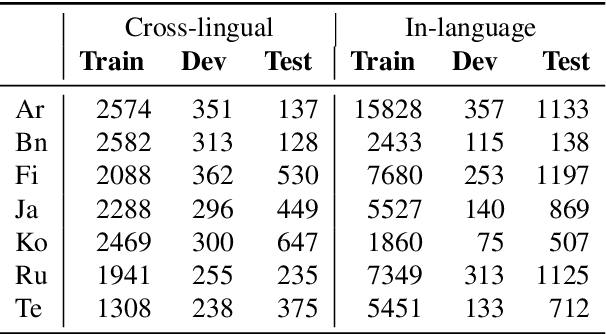
Multilingual question answering tasks typically assume answers exist in the same language as the question. Yet in practice, many languages face both information scarcity---where languages have few reference articles---and information asymmetry---where questions reference concepts from other cultures. This work extends open-retrieval question answering to a cross-lingual setting enabling questions from one language to be answered via answer content from another language. We construct a large-scale dataset built on questions from TyDi QA lacking same-language answers. Our task formulation, called Cross-lingual Open Retrieval Question Answering (XOR QA), includes 40k information-seeking questions from across 7 diverse non-English languages. Based on this dataset, we introduce three new tasks that involve cross-lingual document retrieval using multi-lingual and English resources. We establish baselines with state-of-the-art machine translation systems and cross-lingual pretrained models. Experimental results suggest that XOR QA is a challenging task that will facilitate the development of novel techniques for multilingual question answering. Our data and code are available at https://nlp.cs.washington.edu/xorqa.