 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSearchQA: Bridging the Comprehensiveness Gap for Deep Research Agents
Jan 28, 2026We introduce DeepSearchQA, a 900-prompt benchmark for evaluating agents on difficult multi-step information-seeking tasks across 17 different fields. Unlike traditional benchmarks that target single answer retrieval or broad-spectrum factuality, DeepSearchQA features a dataset of challenging, handcrafted tasks designed to evaluate an agent's ability to execute complex search plans to generate exhaustive answer lists. This shift in design explicitly tests three critical, yet under-evaluated capabilities: 1) systematic collation of fragmented information from disparate sources, 2) de-duplication and entity resolution to ensure precision, and 3) the ability to reason about stopping criteria within an open-ended search space. Each task is structured as a causal chain, where discovering information for one step is dependent on the successful completion of the previous one, stressing long-horizon planning and context retention. All tasks are grounded in the open web with objectively verifiable answer sets. Our comprehensive evaluation of state-of-the-art agent architectures reveals significant performance limitations: even the most advanced models struggle to balance high recall with precision. We observe distinct failure modes ranging from premature stopping (under-retrieval) to hedging behaviors, where agents cast an overly wide net of low-confidence answers to artificially boost recall. These findings highlight critical headroom in current agent designs and position DeepSearchQA as an essential diagnostic tool for driving future research toward more robust, deep-research capabilities.
The FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
Generating recommendations for entity-oriented exploratory search
Apr 02, 2022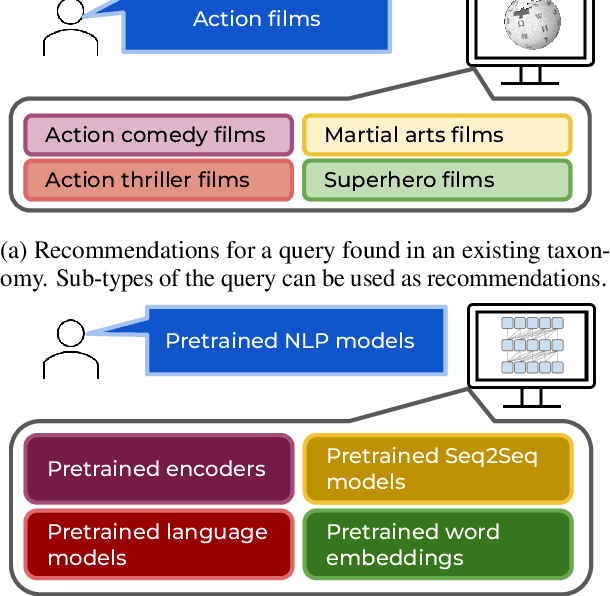
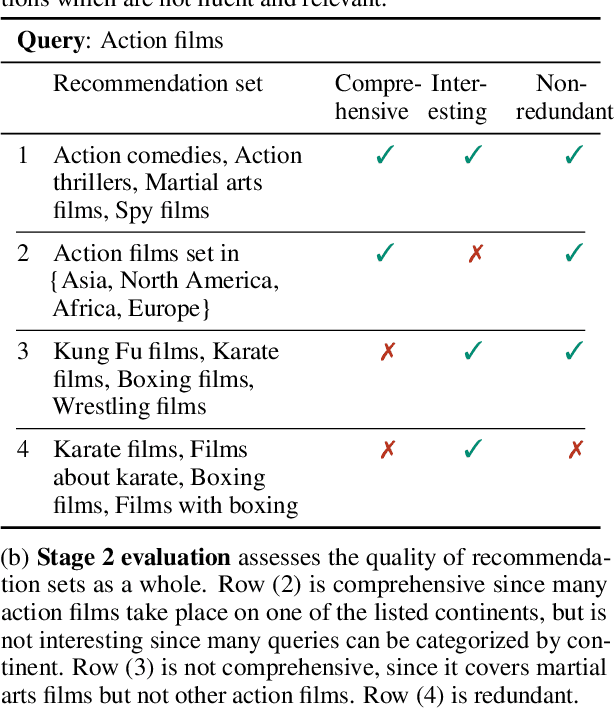
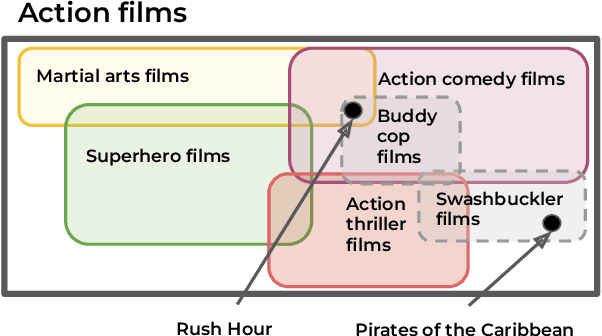

We introduce the task of recommendation set generation for entity-oriented exploratory search. Given an input search query which is open-ended or under-specified, the task is to present the user with an easily-understandable collection of query recommendations, with the goal of facilitating domain exploration or clarifying user intent. Traditional query recommendation systems select recommendations by identifying salient keywords in retrieved documents, or by querying an existing taxonomy or knowledge base for related concepts. In this work, we build a text-to-text model capable of generating a collection of recommendations directly, using the language model as a "soft" knowledge base capable of proposing new concepts not found in an existing taxonomy or set of retrieved documents. We train the model to generate recommendation sets which optimize a cost function designed to encourage comprehensiveness, interestingness, and non-redundancy. In thorough evaluations performed by crowd workers, we confirm the generalizability of our approach and the high quality of the generated recommendations.