 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonte Carlo Augmented Actor-Critic for Sparse Reward Deep Reinforcement Learning from Suboptimal Demonstrations
Oct 14, 2022

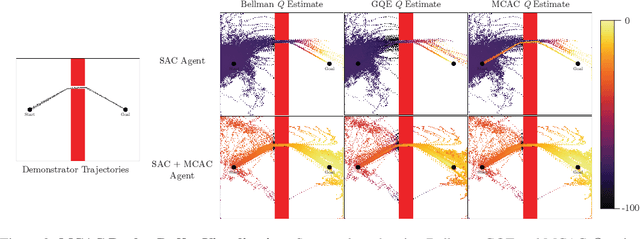

Providing densely shaped reward functions for RL algorithms is often exceedingly challenging, motivating the development of RL algorithms that can learn from easier-to-specify sparse reward functions. This sparsity poses new exploration challenges. One common way to address this problem is using demonstrations to provide initial signal about regions of the state space with high rewards. However, prior RL from demonstrations algorithms introduce significant complexity and many hyperparameters, making them hard to implement and tune. We introduce Monte Carlo Augmented Actor Critic (MCAC), a parameter free modification to standard actor-critic algorithms which initializes the replay buffer with demonstrations and computes a modified $Q$-value by taking the maximum of the standard temporal distance (TD) target and a Monte Carlo estimate of the reward-to-go. This encourages exploration in the neighborhood of high-performing trajectories by encouraging high $Q$-values in corresponding regions of the state space. Experiments across $5$ continuous control domains suggest that MCAC can be used to significantly increase learning efficiency across $6$ commonly used RL and RL-from-demonstrations algorithms. See https://sites.google.com/view/mcac-rl for code and supplementary material.
Learning to Efficiently Plan Robust Frictional Multi-Object Grasps
Oct 13, 2022

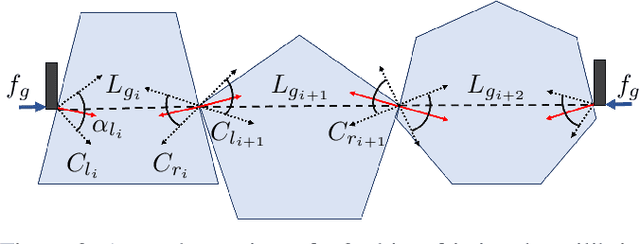

We consider a decluttering problem where multiple rigid convex polygonal objects rest in randomly placed positions and orientations on a planar surface and must be efficiently transported to a packing box using both single and multi-object grasps. Prior work considered frictionless multi-object grasping. In this paper, we introduce friction to increase picks per hour. We train a neural network using real examples to plan robust multi-object grasps. In physical experiments, we find an 11.7% increase in success rates, a 1.7x increase in picks per hour, and an 8.2x decrease in grasp planning time compared to prior work on multi-object grasping. Videos are available at https://youtu.be/pEZpHX5FZIs.
Safely Learning Visuo-Tactile Feedback Policies in Real For Industrial Insertion
Oct 04, 2022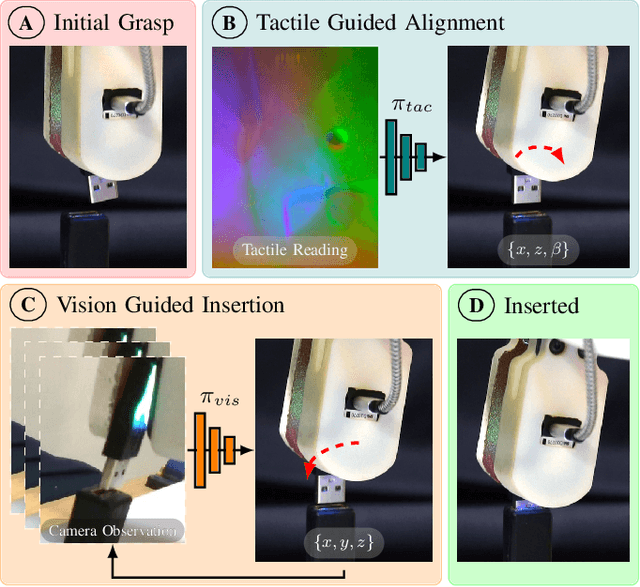
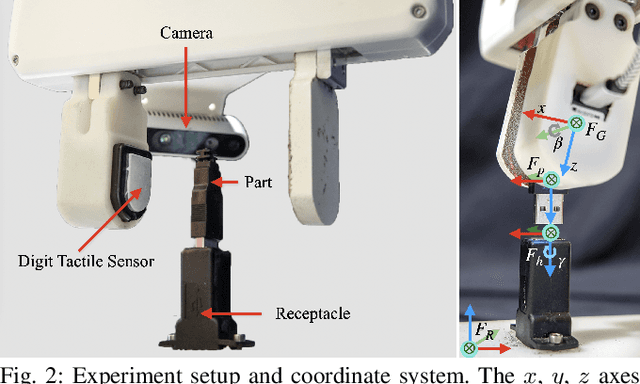

Industrial insertion tasks are often performed repetitively with parts that are subject to tight tolerances and prone to breakage. In this paper, we present a safe method to learn a visuo-tactile insertion policy that is robust against grasp pose variations while minimizing human inputs and collision between the robot and the environment. We achieve this by dividing the insertion task into two phases. In the first align phase, we learn a tactile-based grasp pose estimation model to align the insertion part with the receptacle. In the second insert phase, we learn a vision-based policy to guide the part into the receptacle. Using force-torque sensing, we also develop a safe self-supervised data collection pipeline that limits collision between the part and the surrounding environment. Physical experiments on the USB insertion task from the NIST Assembly Taskboard suggest that our approach can achieve 45/45 insertion successes on 45 different initial grasp poses, improving on two baselines: (1) a behavior cloning agent trained on 50 human insertion demonstrations (1/45) and (2) an online RL policy (TD3) trained in real (0/45).
SGTM 2.0: Autonomously Untangling Long Cables using Interactive Perception
Sep 27, 2022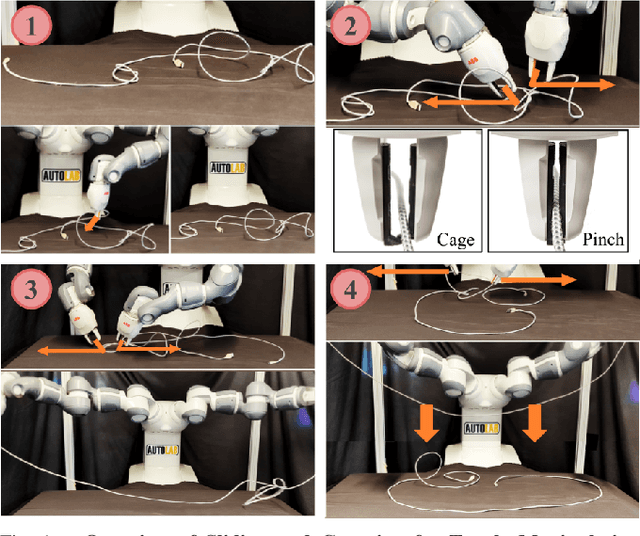

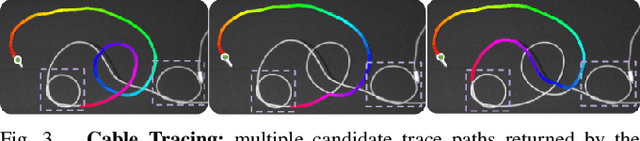
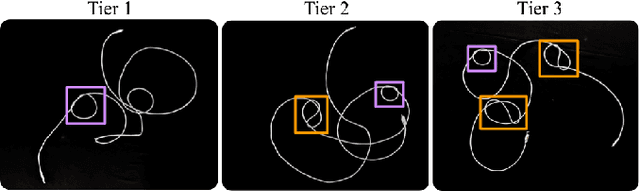
Cables are commonplace in homes, hospitals, and industrial warehouses and are prone to tangling. This paper extends prior work on autonomously untangling long cables by introducing novel uncertainty quantification metrics and actions that interact with the cable to reduce perception uncertainty. We present Sliding and Grasping for Tangle Manipulation 2.0 (SGTM 2.0), a system that autonomously untangles cables approximately 3 meters in length with a bilateral robot using estimates of uncertainty at each step to inform actions. By interactively reducing uncertainty, Sliding and Grasping for Tangle Manipulation 2.0 (SGTM 2.0) reduces the number of state-resetting moves it must take, significantly speeding up run-time. Experiments suggest that SGTM 2.0 can achieve 83% untangling success on cables with 1 or 2 overhand and figure-8 knots, and 70% termination detection success across these configurations, outperforming SGTM 1.0 by 43% in untangling accuracy and 200% in full rollout speed. Supplementary material, visualizations, and videos can be found at sites.google.com/view/sgtm2.
Learning Self-Supervised Representations from Vision and Touch for Active Sliding Perception of Deformable Surfaces
Sep 26, 2022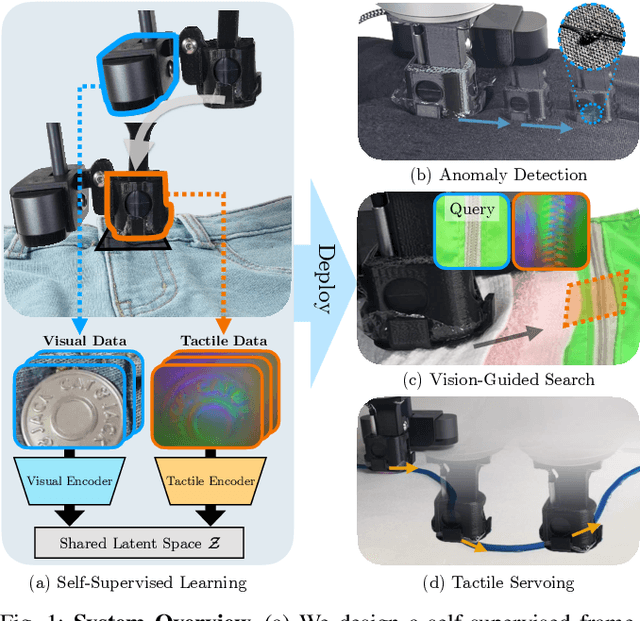
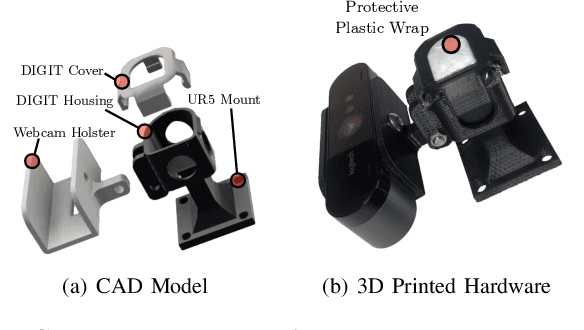

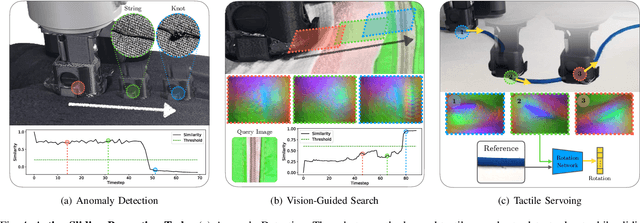
Humans make extensive use of vision and touch as complementary senses, with vision providing global information about the scene and touch measuring local information during manipulation without suffering from occlusions. In this work, we propose a novel framework for learning multi-task visuo-tactile representations in a self-supervised manner. We design a mechanism which enables a robot to autonomously collect spatially aligned visual and tactile data, a key property for downstream tasks. We then train visual and tactile encoders to embed these paired sensory inputs into a shared latent space using cross-modal contrastive loss. The learned representations are evaluated without fine-tuning on 5 perception and control tasks involving deformable surfaces: tactile classification, contact localization, anomaly detection (e.g., surgical phantom tumor palpation), tactile search from a visual query (e.g., garment feature localization under occlusion), and tactile servoing along cloth edges and cables. The learned representations achieve an 80% success rate on towel feature classification, a 73% average success rate on anomaly detection in surgical materials, a 100% average success rate on vision-guided tactile search, and 87.8% average servo distance along cables and garment seams. These results suggest the flexibility of the learned representations and pose a step toward task-agnostic visuo-tactile representation learning for robot control.
SpeedFolding: Learning Efficient Bimanual Folding of Garments
Aug 22, 2022

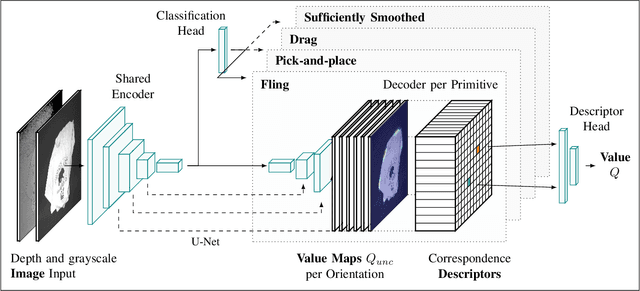
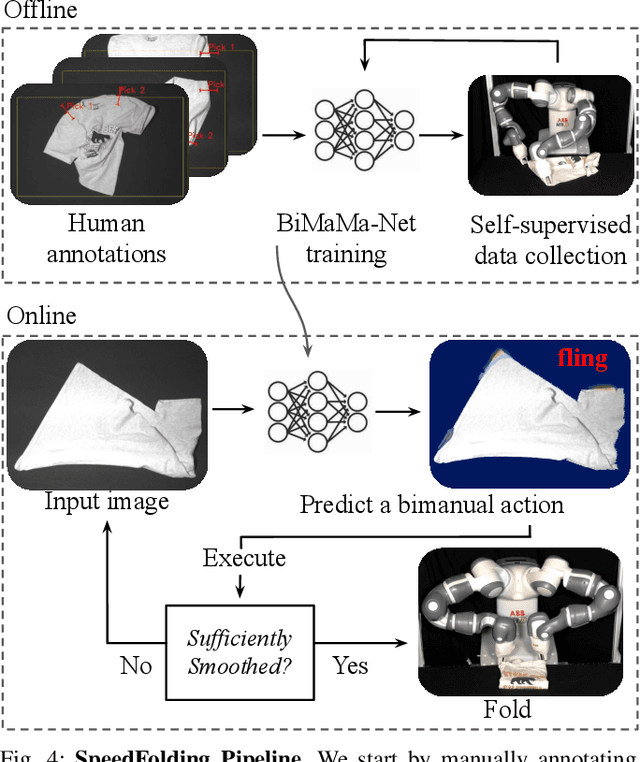
Folding garments reliably and efficiently is a long standing challenge in robotic manipulation due to the complex dynamics and high dimensional configuration space of garments. An intuitive approach is to initially manipulate the garment to a canonical smooth configuration before folding. In this work, we develop SpeedFolding, a reliable and efficient bimanual system, which given user-defined instructions as folding lines, manipulates an initially crumpled garment to (1) a smoothed and (2) a folded configuration. Our primary contribution is a novel neural network architecture that is able to predict pairs of gripper poses to parameterize a diverse set of bimanual action primitives. After learning from 4300 human-annotated and self-supervised actions, the robot is able to fold garments from a random initial configuration in under 120s on average with a success rate of 93%. Real-world experiments show that the system is able to generalize to unseen garments of different color, shape, and stiffness. While prior work achieved 3-6 Folds Per Hour (FPH), SpeedFolding achieves 30-40 FPH.
Automated Pruning of Polyculture Plants
Aug 22, 2022
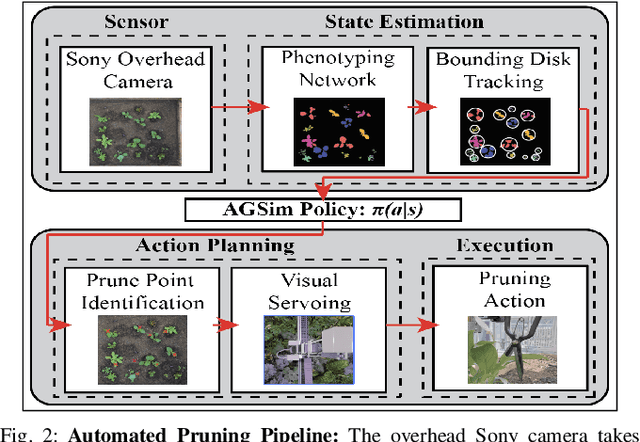
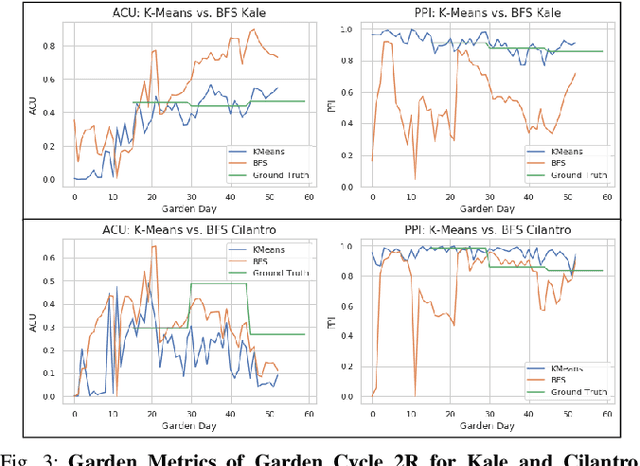

Polyculture farming has environmental advantages but requires substantially more pruning than monoculture farming. We present novel hardware and algorithms for automated pruning. Using an overhead camera to collect data from a physical scale garden testbed, the autonomous system utilizes a learned Plant Phenotyping convolutional neural network and a Bounding Disk Tracking algorithm to evaluate the individual plant distribution and estimate the state of the garden each day. From this garden state, AlphaGardenSim selects plants to autonomously prune. A trained neural network detects and targets specific prune points on the plant. Two custom-designed pruning tools, compatible with a FarmBot gantry system, are experimentally evaluated and execute autonomous cuts through controlled algorithms. We present results for four 60-day garden cycles. Results suggest the system can autonomously achieve 0.94 normalized plant diversity with pruning shears while maintaining an average canopy coverage of 0.84 by the end of the cycles. For code, videos, and datasets, see https://sites.google.com/berkeley.edu/pruningpolyculture.
Autonomously Untangling Long Cables
Jul 16, 2022


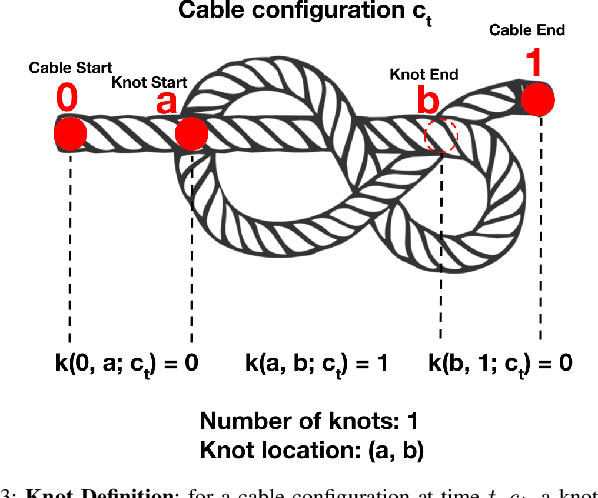
Cables are ubiquitous in many settings, but are prone to self-occlusions and knots, making them difficult to perceive and manipulate. The challenge often increases with cable length: long cables require more complex slack management and strategies to facilitate observability and reachability. In this paper, we focus on autonomously untangling cables up to 3 meters in length using a bilateral robot. We develop new motion primitives to efficiently untangle long cables and novel gripper jaws specialized for this task. We present Sliding and Grasping for Tangle Manipulation (SGTM), an algorithm that composes these primitives with RGBD vision to iteratively untangle. SGTM untangles cables with success rates of 67% on isolated overhand and figure eight knots and 50% on more complex configurations. Supplementary material, visualizations, and videos can be found at https://sites.google.com/view/rss-2022-untangling/home.
Mechanical Search on Shelves with Efficient Stacking and Destacking of Objects
Jul 05, 2022
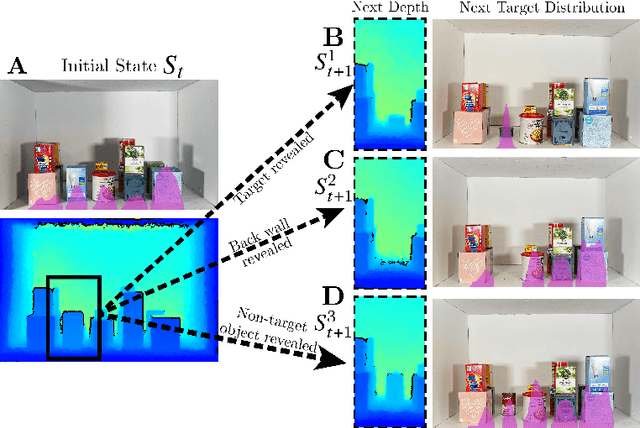
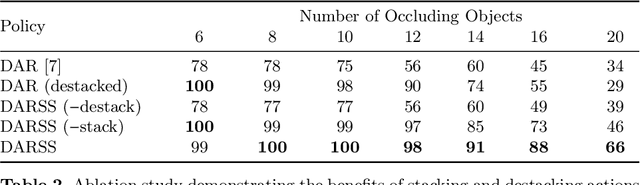
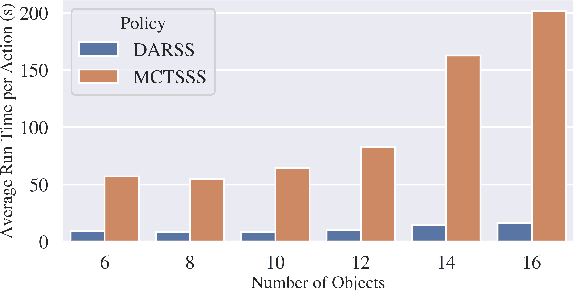
Stacking increases storage efficiency in shelves, but the lack of visibility and accessibility makes the mechanical search problem of revealing and extracting target objects difficult for robots. In this paper, we extend the lateral-access mechanical search problem to shelves with stacked items and introduce two novel policies -- Distribution Area Reduction for Stacked Scenes (DARSS) and Monte Carlo Tree Search for Stacked Scenes (MCTSSS) -- that use destacking and restacking actions. MCTSSS improves on prior lookahead policies by considering future states after each potential action. Experiments in 1200 simulated and 18 physical trials with a Fetch robot equipped with a blade and suction cup suggest that destacking and restacking actions can reveal the target object with 82--100% success in simulation and 66--100% in physical experiments, and are critical for searching densely packed shelves. In the simulation experiments, both policies outperform a baseline and achieve similar success rates but take more steps compared with an oracle policy that has full state information. In simulation and physical experiments, DARSS outperforms MCTSSS in median number of steps to reveal the target, but MCTSSS has a higher success rate in physical experiments, suggesting robustness to perception noise. See https://sites.google.com/berkeley.edu/stax-ray for supplementary material.
Learning Switching Criteria for Sim2Real Transfer of Robotic Fabric Manipulation Policies
Jul 02, 2022
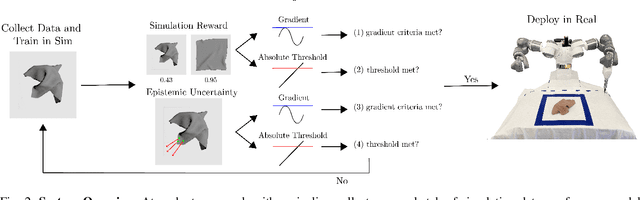

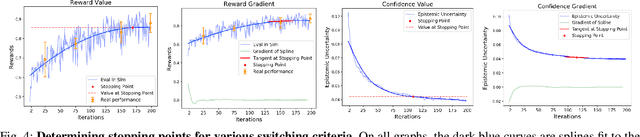
Simulation-to-reality transfer has emerged as a popular and highly successful method to train robotic control policies for a wide variety of tasks. However, it is often challenging to determine when policies trained in simulation are ready to be transferred to the physical world. Deploying policies that have been trained with very little simulation data can result in unreliable and dangerous behaviors on physical hardware. On the other hand, excessive training in simulation can cause policies to overfit to the visual appearance and dynamics of the simulator. In this work, we study strategies to automatically determine when policies trained in simulation can be reliably transferred to a physical robot. We specifically study these ideas in the context of robotic fabric manipulation, in which successful sim2real transfer is especially challenging due to the difficulties of precisely modeling the dynamics and visual appearance of fabric. Results in a fabric smoothing task suggest that our switching criteria correlate well with performance in real. In particular, our confidence-based switching criteria achieve average final fabric coverage of 87.2-93.7% within 55-60% of the total training budget. See https://tinyurl.com/lsc-case for code and supplemental materials.