 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference is More Than Comparisons: Rethinking Dueling Bandits with Augmented Human Feedback
Nov 12, 2025Interactive preference elicitation (IPE) aims to substantially reduce human effort while acquiring human preferences in wide personalization systems. Dueling bandit (DB) algorithms enable optimal decision-making in IPE building on pairwise comparisons. However, they remain inefficient when human feedback is sparse. Existing methods address sparsity by heavily relying on parametric reward models, whose rigid assumptions are vulnerable to misspecification. In contrast, we explore an alternative perspective based on feedback augmentation, and introduce critical improvements to the model-free DB framework. Specifically, we introduce augmented confidence bounds to integrate augmented human feedback under generalized concentration properties, and analyze the multi-factored performance trade-off via regret analysis. Our prototype algorithm achieves competitive performance across several IPE benchmarks, including recommendation, multi-objective optimization, and response optimization for large language models, demonstrating the potential of our approach for provably efficient IPE in broader applications.
Learn the Ropes, Then Trust the Wins: Self-imitation with Progressive Exploration for Agentic Reinforcement Learning
Sep 26, 2025
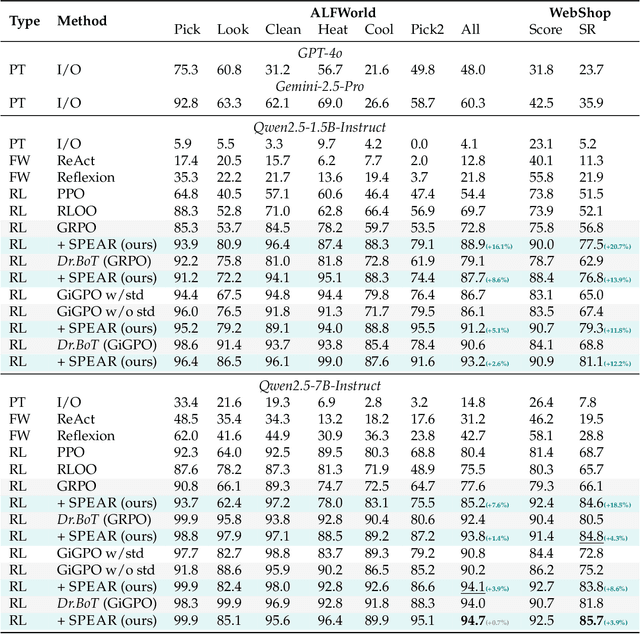
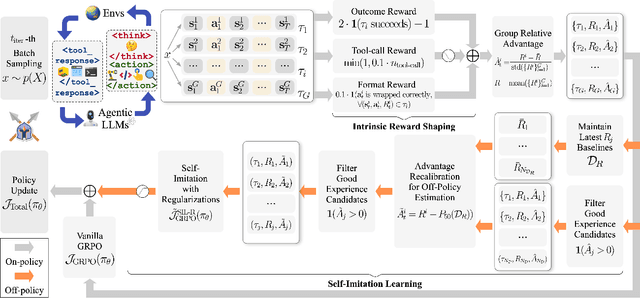
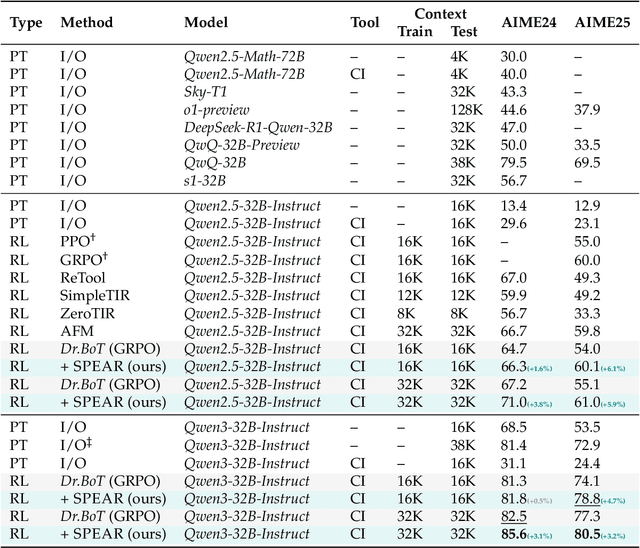
Reinforcement learning (RL) is the dominant paradigm for sharpening strategic tool use capabilities of LLMs on long-horizon, sparsely-rewarded agent tasks, yet it faces a fundamental challenge of exploration-exploitation trade-off. Existing studies stimulate exploration through the lens of policy entropy, but such mechanical entropy maximization is prone to RL training instability due to the multi-turn distribution shifting. In this paper, we target the progressive exploration-exploitation balance under the guidance of the agent own experiences without succumbing to either entropy collapsing or runaway divergence. We propose SPEAR, a curriculum-based self-imitation learning (SIL) recipe for training agentic LLMs. It extends the vanilla SIL framework, where a replay buffer stores self-generated promising trajectories for off-policy update, by gradually steering the policy evolution within a well-balanced range of entropy across stages. Specifically, our approach incorporates a curriculum to manage the exploration process, utilizing intrinsic rewards to foster skill-level exploration and facilitating action-level exploration through SIL. At first, the auxiliary tool call reward plays a critical role in the accumulation of tool-use skills, enabling broad exposure to the unfamiliar distributions of the environment feedback with an upward entropy trend. As training progresses, self-imitation gets strengthened to exploit existing successful patterns from replayed experiences for comparative action-level exploration, accelerating solution iteration without unbounded entropy growth. To further stabilize training, we recalibrate the advantages of experiences in the replay buffer to address the potential policy drift. Reugularizations such as the clipping of tokens with high covariance between probability and advantage are introduced to the trajectory-level entropy control to curb over-confidence.
HEAPr: Hessian-based Efficient Atomic Expert Pruning in Output Space
Sep 26, 2025Mixture-of-Experts (MoE) architectures in large language models (LLMs) deliver exceptional performance and reduced inference costs compared to dense LLMs. However, their large parameter counts result in prohibitive memory requirements, limiting practical deployment. While existing pruning methods primarily focus on expert-level pruning, this coarse granularity often leads to substantial accuracy degradation. In this work, we introduce HEAPr, a novel pruning algorithm that decomposes experts into smaller, indivisible atomic experts, enabling more precise and flexible atomic expert pruning. To measure the importance of each atomic expert, we leverage second-order information based on principles similar to Optimal Brain Surgeon (OBS) theory. To address the computational and storage challenges posed by second-order information, HEAPr exploits the inherent properties of atomic experts to transform the second-order information from expert parameters into that of atomic expert parameters, and further simplifies it to the second-order information of atomic expert outputs. This approach reduces the space complexity from $O(d^4)$, where d is the model's dimensionality, to $O(d^2)$. HEAPr requires only two forward passes and one backward pass on a small calibration set to compute the importance of atomic experts. Extensive experiments on MoE models, including DeepSeek MoE and Qwen MoE family, demonstrate that HEAPr outperforms existing expert-level pruning methods across a wide range of compression ratios and benchmarks. Specifically, HEAPr achieves nearly lossless compression at compression ratios of 20% ~ 25% in most models, while also reducing FLOPs nearly by 20%. The code can be found at \href{https://github.com/LLIKKE/HEAPr}{https://github.com/LLIKKE/HEAPr}.
Amadeus: Autoregressive Model with Bidirectional Attribute Modelling for Symbolic Music
Aug 28, 2025Existing state-of-the-art symbolic music generation models predominantly adopt autoregressive or hierarchical autoregressive architectures, modelling symbolic music as a sequence of attribute tokens with unidirectional temporal dependencies, under the assumption of a fixed, strict dependency structure among these attributes. However, we observe that using different attributes as the initial token in these models leads to comparable performance. This suggests that the attributes of a musical note are, in essence, a concurrent and unordered set, rather than a temporally dependent sequence. Based on this insight, we introduce Amadeus, a novel symbolic music generation framework. Amadeus adopts a two-level architecture: an autoregressive model for note sequences and a bidirectional discrete diffusion model for attributes. To enhance performance, we propose Music Latent Space Discriminability Enhancement Strategy(MLSDES), incorporating contrastive learning constraints that amplify discriminability of intermediate music representations. The Conditional Information Enhancement Module (CIEM) simultaneously strengthens note latent vector representation via attention mechanisms, enabling more precise note decoding. We conduct extensive experiments on unconditional and text-conditioned generation tasks. Amadeus significantly outperforms SOTA models across multiple metrics while achieving at least 4$\times$ speed-up. Furthermore, we demonstrate training-free, fine-grained note attribute control feasibility using our model. To explore the upper performance bound of the Amadeus architecture, we compile the largest open-source symbolic music dataset to date, AMD (Amadeus MIDI Dataset), supporting both pre-training and fine-tuning.
Spontaneous Spatial Cognition Emerges during Egocentric Video Viewing through Non-invasive BCI
Jul 16, 2025



Humans possess a remarkable capacity for spatial cognition, allowing for self-localization even in novel or unfamiliar environments. While hippocampal neurons encoding position and orientation are well documented, the large-scale neural dynamics supporting spatial representation, particularly during naturalistic, passive experience, remain poorly understood. Here, we demonstrate for the first time that non-invasive brain-computer interfaces (BCIs) based on electroencephalography (EEG) can decode spontaneous, fine-grained egocentric 6D pose, comprising three-dimensional position and orientation, during passive viewing of egocentric video. Despite EEG's limited spatial resolution and high signal noise, we find that spatially coherent visual input (i.e., continuous and structured motion) reliably evokes decodable spatial representations, aligning with participants' subjective sense of spatial engagement. Decoding performance further improves when visual input is presented at a frame rate of 100 ms per image, suggesting alignment with intrinsic neural temporal dynamics. Using gradient-based backpropagation through a neural decoding model, we identify distinct EEG channels contributing to position -- and orientation specific -- components, revealing a distributed yet complementary neural encoding scheme. These findings indicate that the brain's spatial systems operate spontaneously and continuously, even under passive conditions, challenging traditional distinctions between active and passive spatial cognition. Our results offer a non-invasive window into the automatic construction of egocentric spatial maps and advance our understanding of how the human mind transforms everyday sensory experience into structured internal representations.
GEM: Empowering LLM for both Embedding Generation and Language Understanding
Jun 04, 2025Large decoder-only language models (LLMs) have achieved remarkable success in generation and reasoning tasks, where they generate text responses given instructions. However, many applications, e.g., retrieval augmented generation (RAG), still rely on separate embedding models to generate text embeddings, which can complicate the system and introduce discrepancies in understanding of the query between the embedding model and LLMs. To address this limitation, we propose a simple self-supervised approach, Generative Embedding large language Model (GEM), that enables any large decoder-only LLM to generate high-quality text embeddings while maintaining its original text generation and reasoning capabilities. Our method inserts new special token(s) into a text body, and generates summarization embedding of the text by manipulating the attention mask. This method could be easily integrated into post-training or fine tuning stages of any existing LLMs. We demonstrate the effectiveness of our approach by applying it to two popular LLM families, ranging from 1B to 8B parameters, and evaluating the transformed models on both text embedding benchmarks (MTEB) and NLP benchmarks (MMLU). The results show that our proposed method significantly improves the original LLMs on MTEB while having a minimal impact on MMLU. Our strong results indicate that our approach can empower LLMs with state-of-the-art text embedding capabilities while maintaining their original NLP performance
Zooming from Context to Cue: Hierarchical Preference Optimization for Multi-Image MLLMs
May 28, 2025Multi-modal Large Language Models (MLLMs) excel at single-image tasks but struggle with multi-image understanding due to cross-modal misalignment, leading to hallucinations (context omission, conflation, and misinterpretation). Existing methods using Direct Preference Optimization (DPO) constrain optimization to a solitary image reference within the input sequence, neglecting holistic context modeling. We propose Context-to-Cue Direct Preference Optimization (CcDPO), a multi-level preference optimization framework that enhances per-image perception in multi-image settings by zooming into visual clues -- from sequential context to local details. It features: (i) Context-Level Optimization : Re-evaluates cognitive biases underlying MLLMs' multi-image context comprehension and integrates a spectrum of low-cost global sequence preferences for bias mitigation. (ii) Needle-Level Optimization : Directs attention to fine-grained visual details through region-targeted visual prompts and multimodal preference supervision. To support scalable optimization, we also construct MultiScope-42k, an automatically generated dataset with high-quality multi-level preference pairs. Experiments show that CcDPO significantly reduces hallucinations and yields consistent performance gains across general single- and multi-image tasks.
Beyond Templates: Dynamic Adaptation of Reasoning Demonstrations via Feasibility-Aware Exploration
May 27, 2025Large language models (LLMs) have shown remarkable reasoning capabilities, yet aligning such abilities to small language models (SLMs) remains a challenge due to distributional mismatches and limited model capacity. Existing reasoning datasets, typically designed for powerful LLMs, often lead to degraded performance when directly applied to weaker models. In this work, we introduce Dynamic Adaptation of Reasoning Trajectories (DART), a novel data adaptation framework that bridges the capability gap between expert reasoning trajectories and diverse SLMs. Instead of uniformly imitating expert steps, DART employs a selective imitation strategy guided by step-wise adaptability estimation via solution simulation. When expert steps surpass the student's capacity -- signaled by an Imitation Gap -- the student autonomously explores alternative reasoning paths, constrained by outcome consistency. We validate DART across multiple reasoning benchmarks and model scales, demonstrating that it significantly improves generalization and data efficiency over static fine-tuning. Our method enhances supervision quality by aligning training signals with the student's reasoning capabilities, offering a scalable solution for reasoning alignment in resource-constrained models.
Conversational Exploration of Literature Landscape with LitChat
May 25, 2025We are living in an era of "big literature", where the volume of digital scientific publications is growing exponentially. While offering new opportunities, this also poses challenges for understanding literature landscapes, as traditional manual reviewing is no longer feasible. Recent large language models (LLMs) have shown strong capabilities for literature comprehension, yet they are incapable of offering "comprehensive, objective, open and transparent" views desired by systematic reviews due to their limited context windows and trust issues like hallucinations. Here we present LitChat, an end-to-end, interactive and conversational literature agent that augments LLM agents with data-driven discovery tools to facilitate literature exploration. LitChat automatically interprets user queries, retrieves relevant sources, constructs knowledge graphs, and employs diverse data-mining techniques to generate evidence-based insights addressing user needs. We illustrate the effectiveness of LitChat via a case study on AI4Health, highlighting its capacity to quickly navigate the users through large-scale literature landscape with data-based evidence that is otherwise infeasible with traditional means.
Time Tracker: Mixture-of-Experts-Enhanced Foundation Time Series Forecasting Model with Decoupled Training Pipelines
May 21, 2025



In the past few years, time series foundation models have achieved superior predicting accuracy. However, real-world time series often exhibit significant diversity in their temporal patterns across different time spans and domains, making it challenging for a single model architecture to fit all complex scenarios. In addition, time series data may have multiple variables exhibiting complex correlations between each other. Recent mainstream works have focused on modeling times series in a channel-independent manner in both pretraining and finetuning stages, overlooking the valuable inter-series dependencies. To this end, we propose \textbf{Time Tracker} for better predictions on multivariate time series data. Firstly, we leverage sparse mixture of experts (MoE) within Transformers to handle the modeling of diverse time series patterns, thereby alleviating the learning difficulties of a single model while improving its generalization. Besides, we propose Any-variate Attention, enabling a unified model structure to seamlessly handle both univariate and multivariate time series, thereby supporting channel-independent modeling during pretraining and channel-mixed modeling for finetuning. Furthermore, we design a graph learning module that constructs relations among sequences from frequency-domain features, providing more precise guidance to capture inter-series dependencies in channel-mixed modeling. Based on these advancements, Time Tracker achieves state-of-the-art performance in predicting accuracy, model generalization and adaptability.