 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Correlated Equilibria in Mean-Field Games
Aug 22, 2022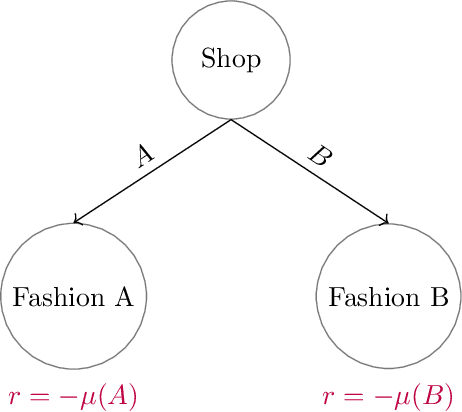
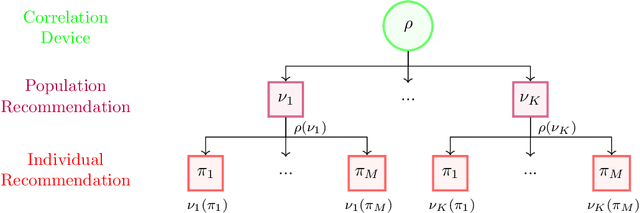
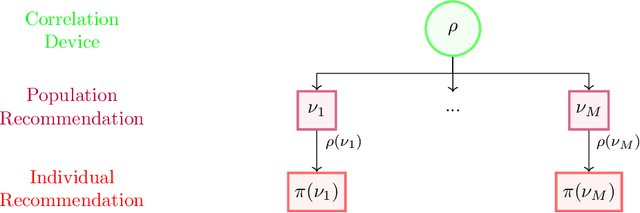
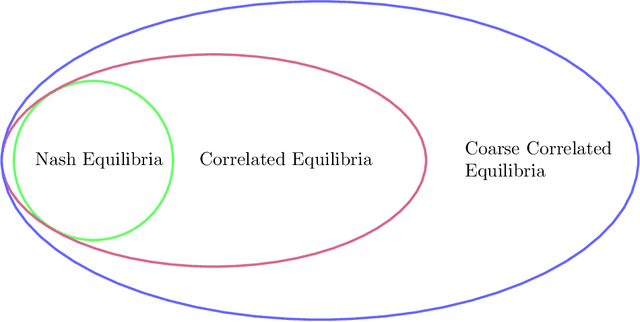
The designs of many large-scale systems today, from traffic routing environments to smart grids, rely on game-theoretic equilibrium concepts. However, as the size of an $N$-player game typically grows exponentially with $N$, standard game theoretic analysis becomes effectively infeasible beyond a low number of players. Recent approaches have gone around this limitation by instead considering Mean-Field games, an approximation of anonymous $N$-player games, where the number of players is infinite and the population's state distribution, instead of every individual player's state, is the object of interest. The practical computability of Mean-Field Nash equilibria, the most studied Mean-Field equilibrium to date, however, typically depends on beneficial non-generic structural properties such as monotonicity or contraction properties, which are required for known algorithms to converge. In this work, we provide an alternative route for studying Mean-Field games, by developing the concepts of Mean-Field correlated and coarse-correlated equilibria. We show that they can be efficiently learnt in \emph{all games}, without requiring any additional assumption on the structure of the game, using three classical algorithms. Furthermore, we establish correspondences between our notions and those already present in the literature, derive optimality bounds for the Mean-Field - $N$-player transition, and empirically demonstrate the convergence of these algorithms on simple games.
Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
Jun 30, 2022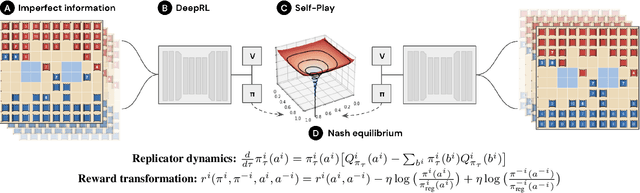
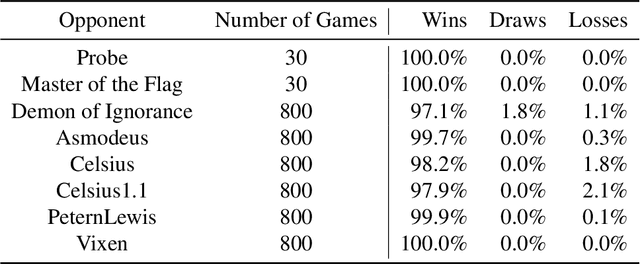
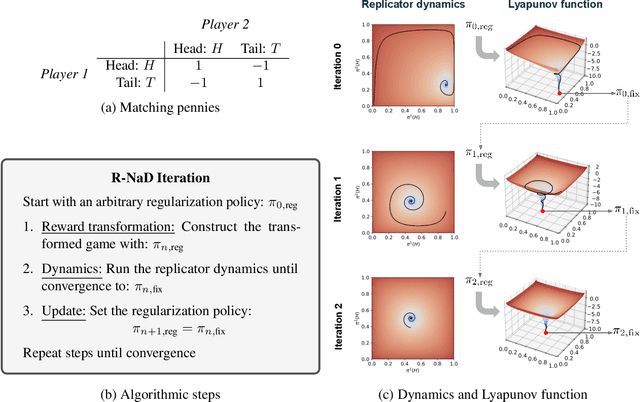

We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board games that Artificial Intelligence (AI) has not yet mastered. This popular game has an enormous game tree on the order of $10^{535}$ nodes, i.e., $10^{175}$ times larger than that of Go. It has the additional complexity of requiring decision-making under imperfect information, similar to Texas hold'em poker, which has a significantly smaller game tree (on the order of $10^{164}$ nodes). Decisions in Stratego are made over a large number of discrete actions with no obvious link between action and outcome. Episodes are long, with often hundreds of moves before a player wins, and situations in Stratego can not easily be broken down into manageably-sized sub-problems as in poker. For these reasons, Stratego has been a grand challenge for the field of AI for decades, and existing AI methods barely reach an amateur level of play. DeepNash uses a game-theoretic, model-free deep reinforcement learning method, without search, that learns to master Stratego via self-play. The Regularised Nash Dynamics (R-NaD) algorithm, a key component of DeepNash, converges to an approximate Nash equilibrium, instead of 'cycling' around it, by directly modifying the underlying multi-agent learning dynamics. DeepNash beats existing state-of-the-art AI methods in Stratego and achieved a yearly (2022) and all-time top-3 rank on the Gravon games platform, competing with human expert players.
Statistical discrimination in learning agents
Oct 21, 2021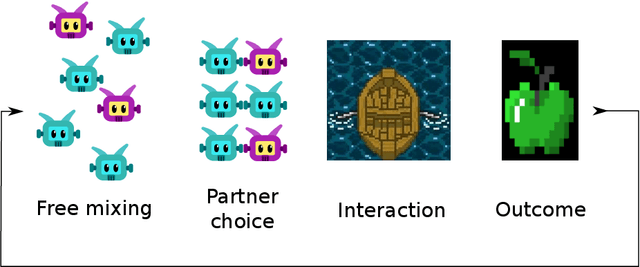
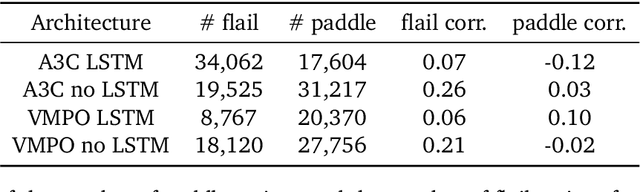
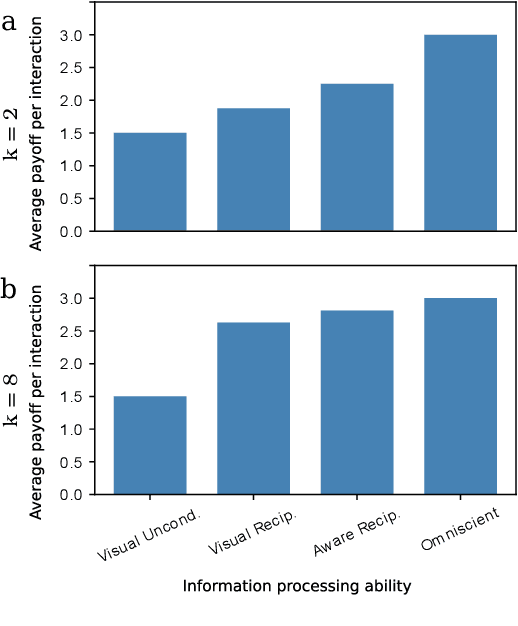
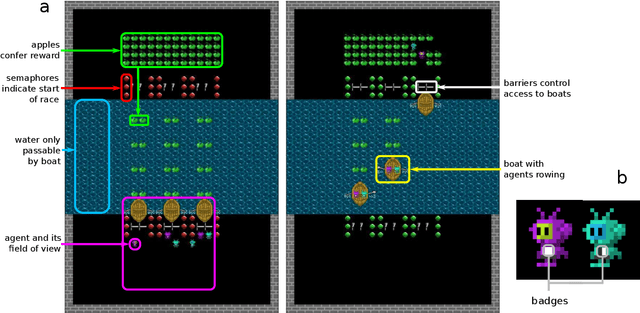
Undesired bias afflicts both human and algorithmic decision making, and may be especially prevalent when information processing trade-offs incentivize the use of heuristics. One primary example is \textit{statistical discrimination} -- selecting social partners based not on their underlying attributes, but on readily perceptible characteristics that covary with their suitability for the task at hand. We present a theoretical model to examine how information processing influences statistical discrimination and test its predictions using multi-agent reinforcement learning with various agent architectures in a partner choice-based social dilemma. As predicted, statistical discrimination emerges in agent policies as a function of both the bias in the training population and of agent architecture. All agents showed substantial statistical discrimination, defaulting to using the readily available correlates instead of the outcome relevant features. We show that less discrimination emerges with agents that use recurrent neural networks, and when their training environment has less bias. However, all agent algorithms we tried still exhibited substantial bias after learning in biased training populations.
Evolutionary Dynamics and $Φ$-Regret Minimization in Games
Jun 28, 2021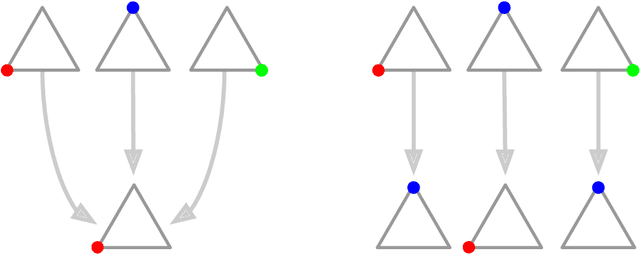
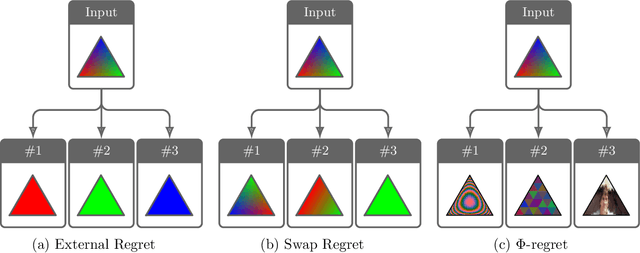
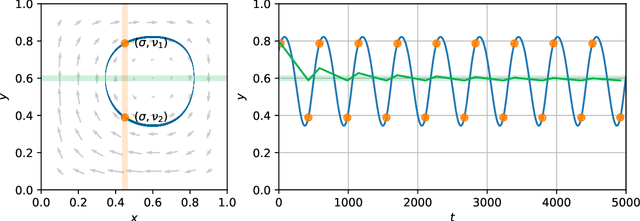
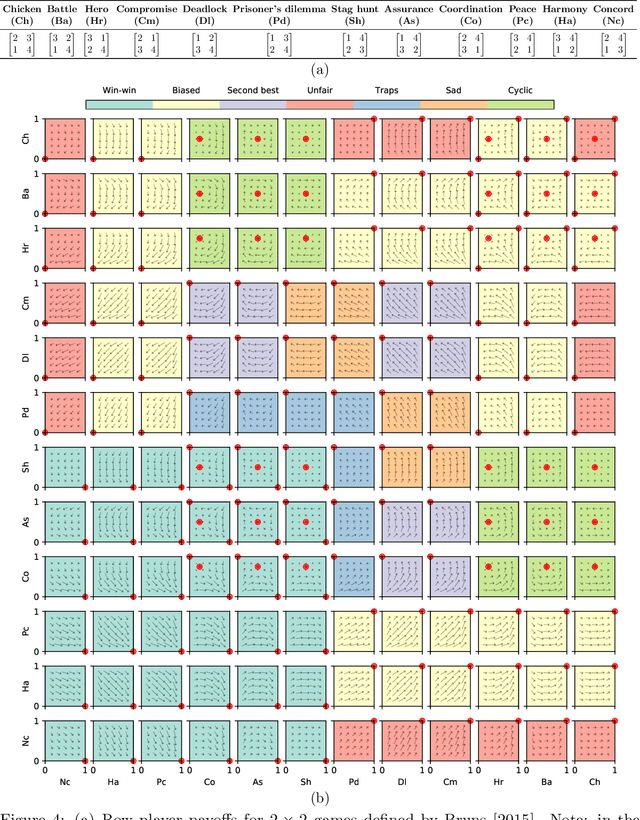
Regret has been established as a foundational concept in online learning, and likewise has important applications in the analysis of learning dynamics in games. Regret quantifies the difference between a learner's performance against a baseline in hindsight. It is well-known that regret-minimizing algorithms converge to certain classes of equilibria in games; however, traditional forms of regret used in game theory predominantly consider baselines that permit deviations to deterministic actions or strategies. In this paper, we revisit our understanding of regret from the perspective of deviations over partitions of the full \emph{mixed} strategy space (i.e., probability distributions over pure strategies), under the lens of the previously-established $\Phi$-regret framework, which provides a continuum of stronger regret measures. Importantly, $\Phi$-regret enables learning agents to consider deviations from and to mixed strategies, generalizing several existing notions of regret such as external, internal, and swap regret, and thus broadening the insights gained from regret-based analysis of learning algorithms. We prove here that the well-studied evolutionary learning algorithm of replicator dynamics (RD) seamlessly minimizes the strongest possible form of $\Phi$-regret in generic $2 \times 2$ games, without any modification of the underlying algorithm itself. We subsequently conduct experiments validating our theoretical results in a suite of 144 $2 \times 2$ games wherein RD exhibits a diverse set of behaviors. We conclude by providing empirical evidence of $\Phi$-regret minimization by RD in some larger games, hinting at further opportunity for $\Phi$-regret based study of such algorithms from both a theoretical and empirical perspective.
Multi-Agent Training beyond Zero-Sum with Correlated Equilibrium Meta-Solvers
Jun 22, 2021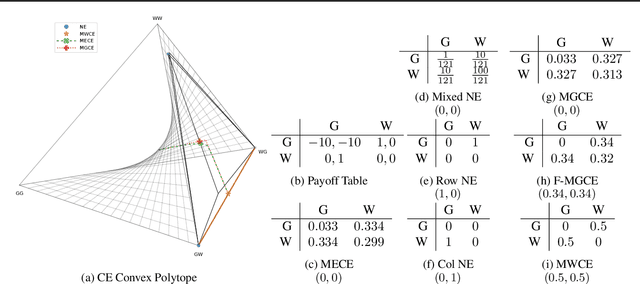
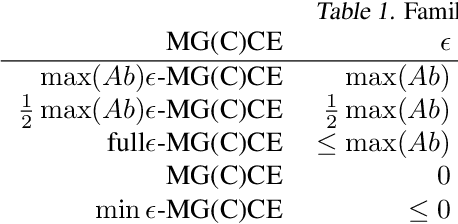
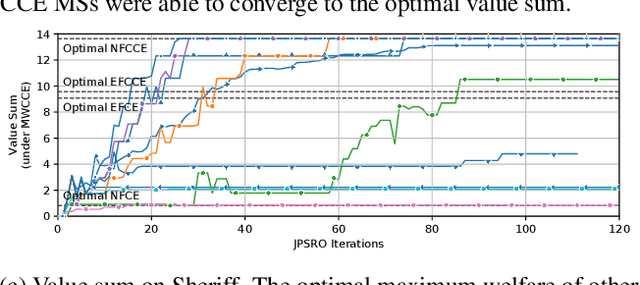
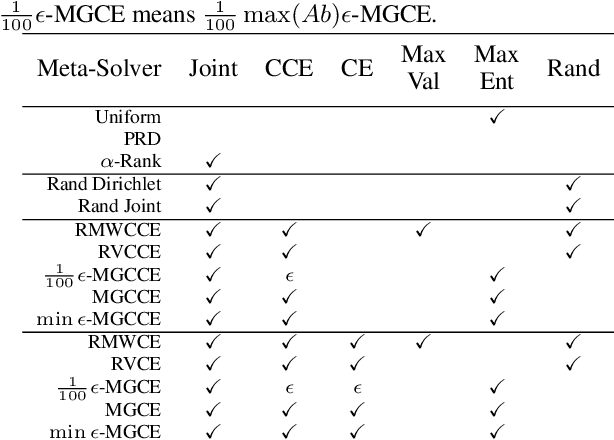
Two-player, constant-sum games are well studied in the literature, but there has been limited progress outside of this setting. We propose Joint Policy-Space Response Oracles (JPSRO), an algorithm for training agents in n-player, general-sum extensive form games, which provably converges to an equilibrium. We further suggest correlated equilibria (CE) as promising meta-solvers, and propose a novel solution concept Maximum Gini Correlated Equilibrium (MGCE), a principled and computationally efficient family of solutions for solving the correlated equilibrium selection problem. We conduct several experiments using CE meta-solvers for JPSRO and demonstrate convergence on n-player, general-sum games.
Time-series Imputation of Temporally-occluded Multiagent Trajectories
Jun 08, 2021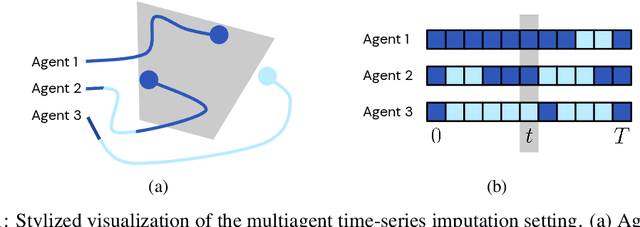
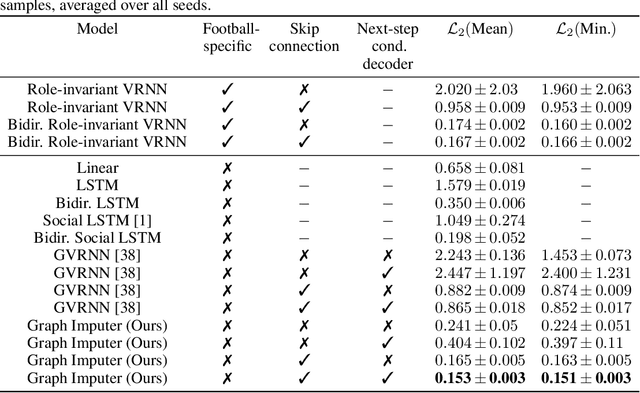
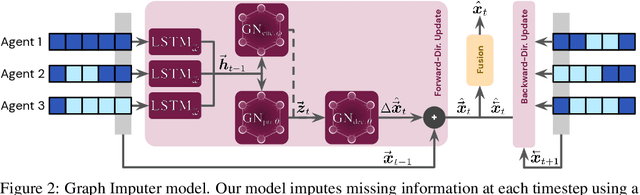
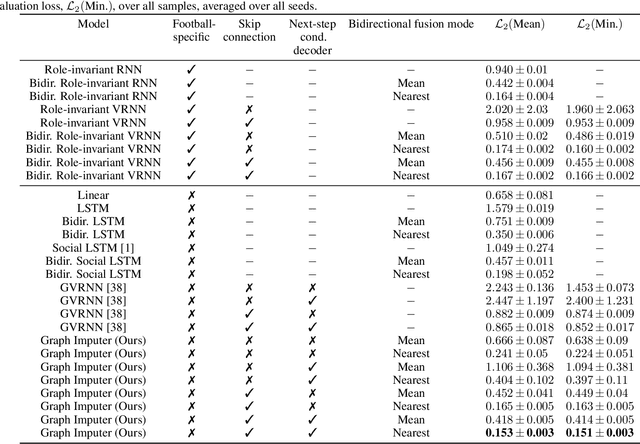
In multiagent environments, several decision-making individuals interact while adhering to the dynamics constraints imposed by the environment. These interactions, combined with the potential stochasticity of the agents' decision-making processes, make such systems complex and interesting to study from a dynamical perspective. Significant research has been conducted on learning models for forward-direction estimation of agent behaviors, for example, pedestrian predictions used for collision-avoidance in self-driving cars. However, in many settings, only sporadic observations of agents may be available in a given trajectory sequence. For instance, in football, subsets of players may come in and out of view of broadcast video footage, while unobserved players continue to interact off-screen. In this paper, we study the problem of multiagent time-series imputation, where available past and future observations of subsets of agents are used to estimate missing observations for other agents. Our approach, called the Graph Imputer, uses forward- and backward-information in combination with graph networks and variational autoencoders to enable learning of a distribution of imputed trajectories. We evaluate our approach on a dataset of football matches, using a projective camera module to train and evaluate our model for the off-screen player state estimation setting. We illustrate that our method outperforms several state-of-the-art approaches, including those hand-crafted for football.
From Motor Control to Team Play in Simulated Humanoid Football
May 25, 2021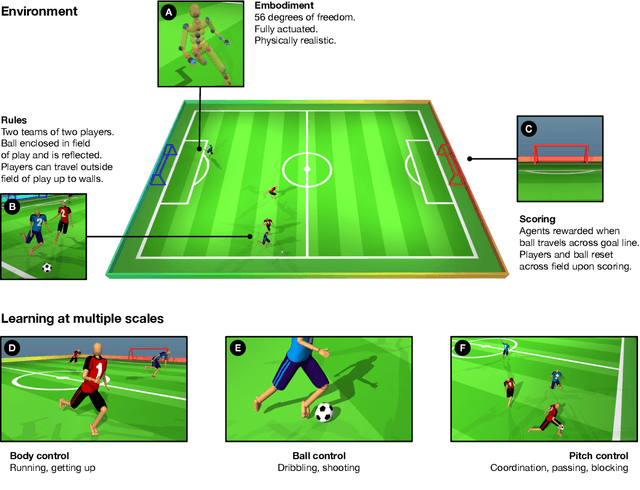

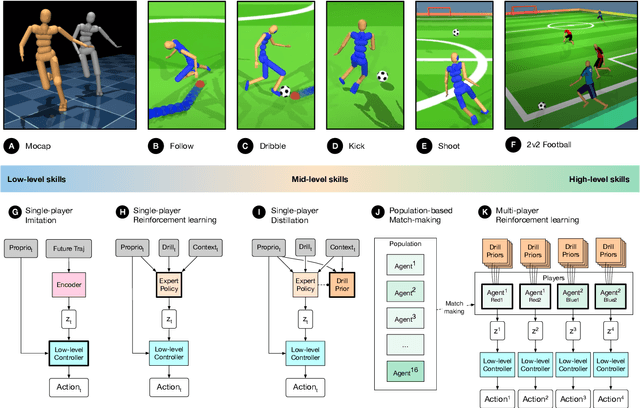

Intelligent behaviour in the physical world exhibits structure at multiple spatial and temporal scales. Although movements are ultimately executed at the level of instantaneous muscle tensions or joint torques, they must be selected to serve goals defined on much longer timescales, and in terms of relations that extend far beyond the body itself, ultimately involving coordination with other agents. Recent research in artificial intelligence has shown the promise of learning-based approaches to the respective problems of complex movement, longer-term planning and multi-agent coordination. However, there is limited research aimed at their integration. We study this problem by training teams of physically simulated humanoid avatars to play football in a realistic virtual environment. We develop a method that combines imitation learning, single- and multi-agent reinforcement learning and population-based training, and makes use of transferable representations of behaviour for decision making at different levels of abstraction. In a sequence of stages, players first learn to control a fully articulated body to perform realistic, human-like movements such as running and turning; they then acquire mid-level football skills such as dribbling and shooting; finally, they develop awareness of others and play as a team, bridging the gap between low-level motor control at a timescale of milliseconds, and coordinated goal-directed behaviour as a team at the timescale of tens of seconds. We investigate the emergence of behaviours at different levels of abstraction, as well as the representations that underlie these behaviours using several analysis techniques, including statistics from real-world sports analytics. Our work constitutes a complete demonstration of integrated decision-making at multiple scales in a physically embodied multi-agent setting. See project video at https://youtu.be/KHMwq9pv7mg.
Scaling up Mean Field Games with Online Mirror Descent
Feb 28, 2021
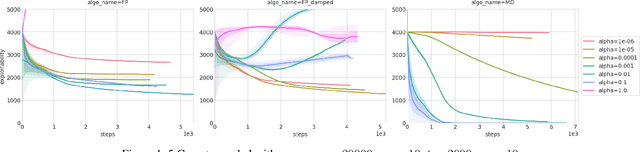

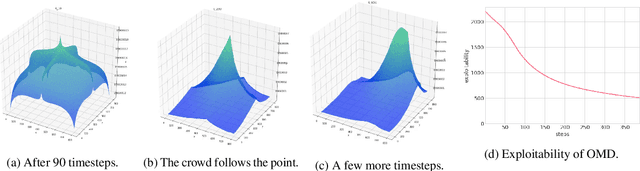
We address scaling up equilibrium computation in Mean Field Games (MFGs) using Online Mirror Descent (OMD). We show that continuous-time OMD provably converges to a Nash equilibrium under a natural and well-motivated set of monotonicity assumptions. This theoretical result nicely extends to multi-population games and to settings involving common noise. A thorough experimental investigation on various single and multi-population MFGs shows that OMD outperforms traditional algorithms such as Fictitious Play (FP). We empirically show that OMD scales up and converges significantly faster than FP by solving, for the first time to our knowledge, examples of MFGs with hundreds of billions states. This study establishes the state-of-the-art for learning in large-scale multi-agent and multi-population games.
Game Plan: What AI can do for Football, and What Football can do for AI
Nov 18, 2020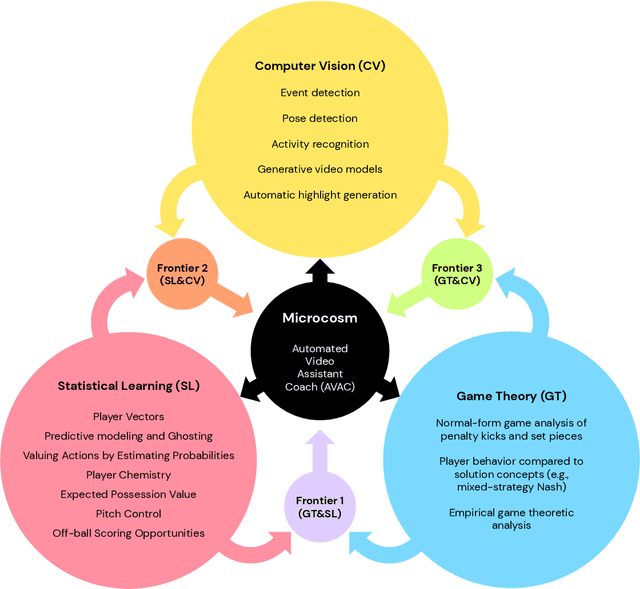



The rapid progress in artificial intelligence (AI) and machine learning has opened unprecedented analytics possibilities in various team and individual sports, including baseball, basketball, and tennis. More recently, AI techniques have been applied to football, due to a huge increase in data collection by professional teams, increased computational power, and advances in machine learning, with the goal of better addressing new scientific challenges involved in the analysis of both individual players' and coordinated teams' behaviors. The research challenges associated with predictive and prescriptive football analytics require new developments and progress at the intersection of statistical learning, game theory, and computer vision. In this paper, we provide an overarching perspective highlighting how the combination of these fields, in particular, forms a unique microcosm for AI research, while offering mutual benefits for professional teams, spectators, and broadcasters in the years to come. We illustrate that this duality makes football analytics a game changer of tremendous value, in terms of not only changing the game of football itself, but also in terms of what this domain can mean for the field of AI. We review the state-of-the-art and exemplify the types of analysis enabled by combining the aforementioned fields, including illustrative examples of counterfactual analysis using predictive models, and the combination of game-theoretic analysis of penalty kicks with statistical learning of player attributes. We conclude by highlighting envisioned downstream impacts, including possibilities for extensions to other sports (real and virtual).
The Advantage Regret-Matching Actor-Critic
Aug 27, 2020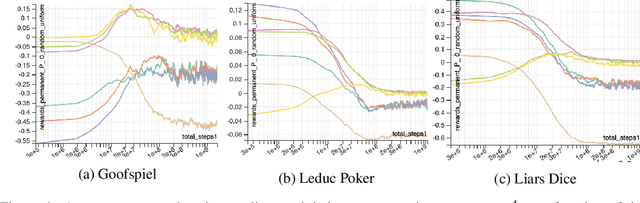
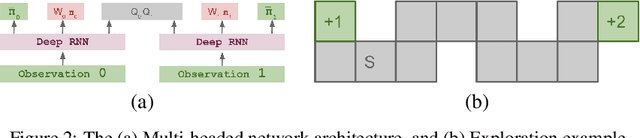
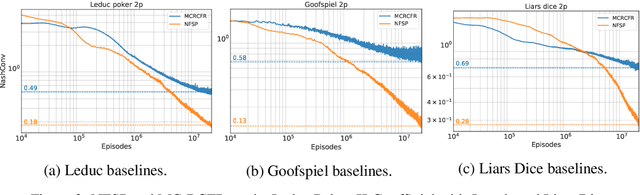
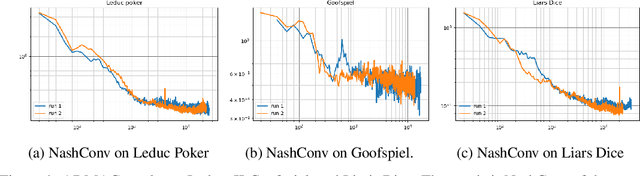
Regret minimization has played a key role in online learning, equilibrium computation in games, and reinforcement learning (RL). In this paper, we describe a general model-free RL method for no-regret learning based on repeated reconsideration of past behavior. We propose a model-free RL algorithm, the AdvantageRegret-Matching Actor-Critic (ARMAC): rather than saving past state-action data, ARMAC saves a buffer of past policies, replaying through them to reconstruct hindsight assessments of past behavior. These retrospective value estimates are used to predict conditional advantages which, combined with regret matching, produces a new policy. In particular, ARMAC learns from sampled trajectories in a centralized training setting, without requiring the application of importance sampling commonly used in Monte Carlo counterfactual regret (CFR) minimization; hence, it does not suffer from excessive variance in large environments. In the single-agent setting, ARMAC shows an interesting form of exploration by keeping past policies intact. In the multiagent setting, ARMAC in self-play approaches Nash equilibria on some partially-observable zero-sum benchmarks. We provide exploitability estimates in the significantly larger game of betting-abstracted no-limit Texas Hold'em.