 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvo-Depth: A Lightweight Depth-Enhanced Vision-Language-Action Model
May 14, 2026Vision-Language-Action models have emerged as a promising paradigm for robotic manipulation by unifying perception, language grounding, and action generation. However, they often struggle in scenarios requiring precise spatial understanding, as current VLA models primarily rely on 2D visual representations that lack depth information and detailed spatial relationships. While recent approaches incorporate explicit 3D inputs such as depth maps or point clouds to address this issue, they often increase system complexity, require additional sensors, and remain vulnerable to sensing noise and reconstruction errors. Another line of work explores implicit 3D-aware spatial modeling directly from RGB observations without extra sensors, but it often relies on large geometry foundation models, resulting in higher training and deployment costs. To address these challenges, we propose Evo-Depth, a lightweight depth-enhanced VLA framework that enhances spatially grounded manipulation without relying on additional sensing hardware or compromising deployment efficiency. Evo-Depth employs a lightweight Implicit Depth Encoding Module to extract compact depth features from multi-view RGB images. These features are incorporated into vision-language representations through a Spatial Enhancement Module via depth-aware modulation, enabling efficient spatial-semantic enhancement. A Progressive Alignment Training strategy is further introduced to align the resulting depth-enhanced representations with downstream action learning. With only 0.9B parameters, Evo-Depth achieves superior performance across four simulation benchmarks. In real-world experiments, Evo-Depth attains the highest average success rate while also exhibiting the smallest model size, lowest GPU memory usage, and highest inference frequency among compared methods.
Capturing Individual Human Preferences with Reward Features
Mar 21, 2025



Reinforcement learning from human feedback usually models preferences using a reward model that does not distinguish between people. We argue that this is unlikely to be a good design choice in contexts with high potential for disagreement, like in the training of large language models. We propose a method to specialise a reward model to a person or group of people. Our approach builds on the observation that individual preferences can be captured as a linear combination of a set of general reward features. We show how to learn such features and subsequently use them to quickly adapt the reward model to a specific individual, even if their preferences are not reflected in the training data. We present experiments with large language models comparing the proposed architecture with a non-adaptive reward model and also adaptive counterparts, including models that do in-context personalisation. Depending on how much disagreement there is in the training data, our model either significantly outperforms the baselines or matches their performance with a simpler architecture and more stable training.
Doing the right thing for the right reason: Evaluating artificial moral cognition by probing cost insensitivity
May 29, 2023


Is it possible to evaluate the moral cognition of complex artificial agents? In this work, we take a look at one aspect of morality: `doing the right thing for the right reasons.' We propose a behavior-based analysis of artificial moral cognition which could also be applied to humans to facilitate like-for-like comparison. Morally-motivated behavior should persist despite mounting cost; by measuring an agent's sensitivity to this cost, we gain deeper insight into underlying motivations. We apply this evaluation to a particular set of deep reinforcement learning agents, trained by memory-based meta-reinforcement learning. Our results indicate that agents trained with a reward function that includes other-regarding preferences perform helping behavior in a way that is less sensitive to increasing cost than agents trained with more self-interested preferences.
Melting Pot 2.0
Dec 13, 2022Multi-agent artificial intelligence research promises a path to develop intelligent technologies that are more human-like and more human-compatible than those produced by "solipsistic" approaches, which do not consider interactions between agents. Melting Pot is a research tool developed to facilitate work on multi-agent artificial intelligence, and provides an evaluation protocol that measures generalization to novel social partners in a set of canonical test scenarios. Each scenario pairs a physical environment (a "substrate") with a reference set of co-players (a "background population"), to create a social situation with substantial interdependence between the individuals involved. For instance, some scenarios were inspired by institutional-economics-based accounts of natural resource management and public-good-provision dilemmas. Others were inspired by considerations from evolutionary biology, game theory, and artificial life. Melting Pot aims to cover a maximally diverse set of interdependencies and incentives. It includes the commonly-studied extreme cases of perfectly-competitive (zero-sum) motivations and perfectly-cooperative (shared-reward) motivations, but does not stop with them. As in real-life, a clear majority of scenarios in Melting Pot have mixed incentives. They are neither purely competitive nor purely cooperative and thus demand successful agents be able to navigate the resulting ambiguity. Here we describe Melting Pot 2.0, which revises and expands on Melting Pot. We also introduce support for scenarios with asymmetric roles, and explain how to integrate them into the evaluation protocol. This report also contains: (1) details of all substrates and scenarios; (2) a complete description of all baseline algorithms and results. Our intention is for it to serve as a reference for researchers using Melting Pot 2.0.
Statistical discrimination in learning agents
Oct 21, 2021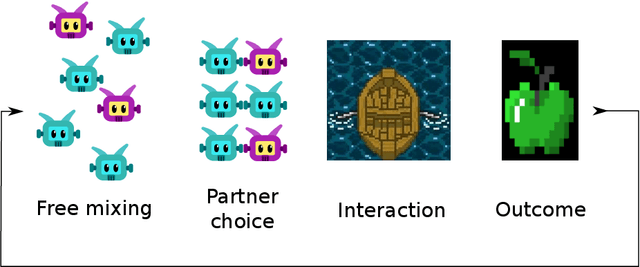
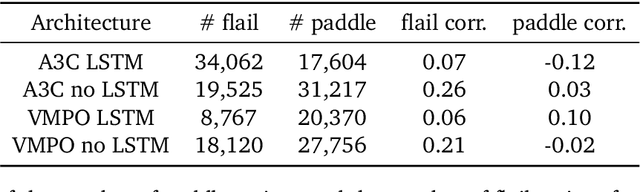
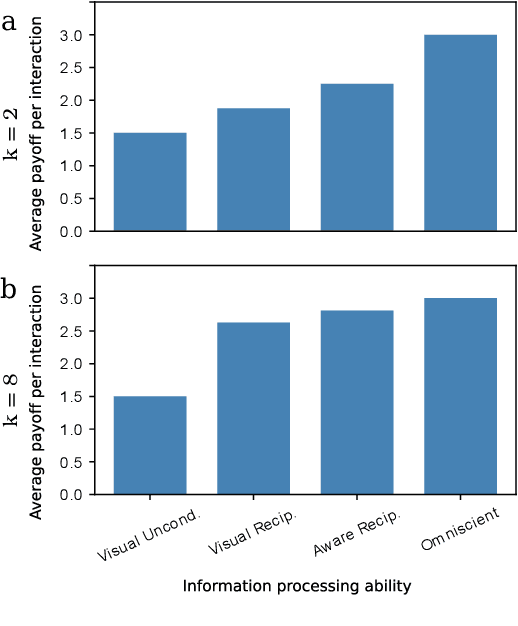
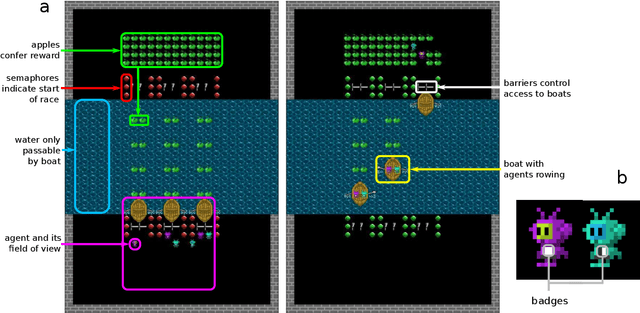
Undesired bias afflicts both human and algorithmic decision making, and may be especially prevalent when information processing trade-offs incentivize the use of heuristics. One primary example is \textit{statistical discrimination} -- selecting social partners based not on their underlying attributes, but on readily perceptible characteristics that covary with their suitability for the task at hand. We present a theoretical model to examine how information processing influences statistical discrimination and test its predictions using multi-agent reinforcement learning with various agent architectures in a partner choice-based social dilemma. As predicted, statistical discrimination emerges in agent policies as a function of both the bias in the training population and of agent architecture. All agents showed substantial statistical discrimination, defaulting to using the readily available correlates instead of the outcome relevant features. We show that less discrimination emerges with agents that use recurrent neural networks, and when their training environment has less bias. However, all agent algorithms we tried still exhibited substantial bias after learning in biased training populations.