 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Assistance Reduces Persistence and Hurts Independent Performance
Apr 07, 2026People often optimize for long-term goals in collaboration: A mentor or companion doesn't just answer questions, but also scaffolds learning, tracks progress, and prioritizes the other person's growth over immediate results. In contrast, current AI systems are fundamentally short-sighted collaborators - optimized for providing instant and complete responses, without ever saying no (unless for safety reasons). What are the consequences of this dynamic? Here, through a series of randomized controlled trials on human-AI interactions (N = 1,222), we provide causal evidence for two key consequences of AI assistance: reduced persistence and impairment of unassisted performance. Across a variety of tasks, including mathematical reasoning and reading comprehension, we find that although AI assistance improves performance in the short-term, people perform significantly worse without AI and are more likely to give up. Notably, these effects emerge after only brief interactions with AI (approximately 10 minutes). These findings are particularly concerning because persistence is foundational to skill acquisition and is one of the strongest predictors of long-term learning. We posit that persistence is reduced because AI conditions people to expect immediate answers, thereby denying them the experience of working through challenges on their own. These results suggest the need for AI model development to prioritize scaffolding long-term competence alongside immediate task completion.
Can AI mediation improve democratic deliberation?
Jan 09, 2026The strength of democracy lies in the free and equal exchange of diverse viewpoints. Living up to this ideal at scale faces inherent tensions: broad participation, meaningful deliberation, and political equality often trade off with one another (Fishkin, 2011). We ask whether and how artificial intelligence (AI) could help navigate this "trilemma" by engaging with a recent example of a large language model (LLM)-based system designed to help people with diverse viewpoints find common ground (Tessler, Bakker, et al., 2024). Here, we explore the implications of the introduction of LLMs into deliberation augmentation tools, examining their potential to enhance participation through scalability, improve political equality via fair mediation, and foster meaningful deliberation by, for example, surfacing trustworthy information. We also point to key challenges that remain. Ultimately, a range of empirical, technical, and theoretical advancements are needed to fully realize the promise of AI-mediated deliberation for enhancing citizen engagement and strengthening democratic deliberation.
Language Agents as Digital Representatives in Collective Decision-Making
Feb 13, 2025



Consider the process of collective decision-making, in which a group of individuals interactively select a preferred outcome from among a universe of alternatives. In this context, "representation" is the activity of making an individual's preferences present in the process via participation by a proxy agent -- i.e. their "representative". To this end, learned models of human behavior have the potential to fill this role, with practical implications for multi-agent scenario studies and mechanism design. In this work, we investigate the possibility of training \textit{language agents} to behave in the capacity of representatives of human agents, appropriately expressing the preferences of those individuals whom they stand for. First, we formalize the setting of \textit{collective decision-making} -- as the episodic process of interaction between a group of agents and a decision mechanism. On this basis, we then formalize the problem of \textit{digital representation} -- as the simulation of an agent's behavior to yield equivalent outcomes from the mechanism. Finally, we conduct an empirical case study in the setting of \textit{consensus-finding} among diverse humans, and demonstrate the feasibility of fine-tuning large language models to act as digital representatives.
Fine-tuning language models to find agreement among humans with diverse preferences
Nov 28, 2022



Recent work in large language modeling (LLMs) has used fine-tuning to align outputs with the preferences of a prototypical user. This work assumes that human preferences are static and homogeneous across individuals, so that aligning to a a single "generic" user will confer more general alignment. Here, we embrace the heterogeneity of human preferences to consider a different challenge: how might a machine help people with diverse views find agreement? We fine-tune a 70 billion parameter LLM to generate statements that maximize the expected approval for a group of people with potentially diverse opinions. Human participants provide written opinions on thousands of questions touching on moral and political issues (e.g., "should we raise taxes on the rich?"), and rate the LLM's generated candidate consensus statements for agreement and quality. A reward model is then trained to predict individual preferences, enabling it to quantify and rank consensus statements in terms of their appeal to the overall group, defined according to different aggregation (social welfare) functions. The model produces consensus statements that are preferred by human users over those from prompted LLMs (>70%) and significantly outperforms a tight fine-tuned baseline that lacks the final ranking step. Further, our best model's consensus statements are preferred over the best human-generated opinions (>65%). We find that when we silently constructed consensus statements from only a subset of group members, those who were excluded were more likely to dissent, revealing the sensitivity of the consensus to individual contributions. These results highlight the potential to use LLMs to help groups of humans align their values with one another.
Statistical discrimination in learning agents
Oct 21, 2021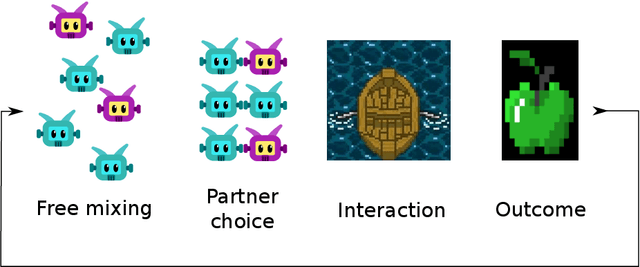
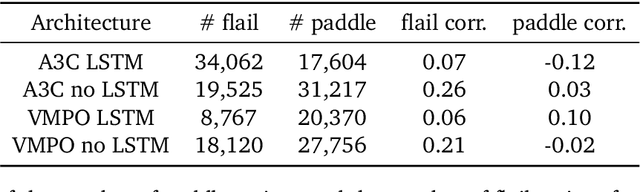
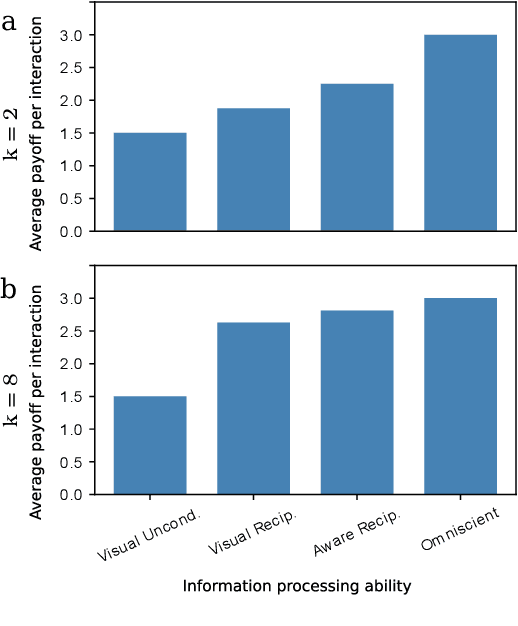
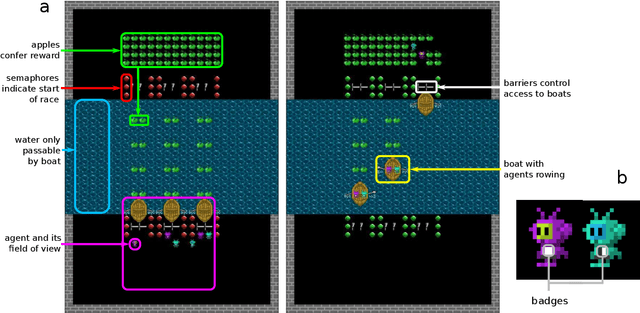
Undesired bias afflicts both human and algorithmic decision making, and may be especially prevalent when information processing trade-offs incentivize the use of heuristics. One primary example is \textit{statistical discrimination} -- selecting social partners based not on their underlying attributes, but on readily perceptible characteristics that covary with their suitability for the task at hand. We present a theoretical model to examine how information processing influences statistical discrimination and test its predictions using multi-agent reinforcement learning with various agent architectures in a partner choice-based social dilemma. As predicted, statistical discrimination emerges in agent policies as a function of both the bias in the training population and of agent architecture. All agents showed substantial statistical discrimination, defaulting to using the readily available correlates instead of the outcome relevant features. We show that less discrimination emerges with agents that use recurrent neural networks, and when their training environment has less bias. However, all agent algorithms we tried still exhibited substantial bias after learning in biased training populations.
Modelling Cooperation in Network Games with Spatio-Temporal Complexity
Feb 13, 2021

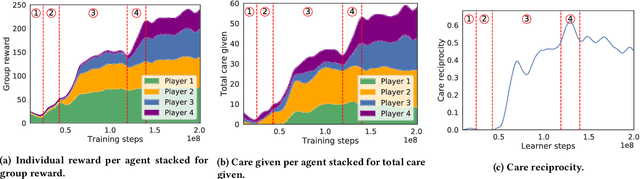
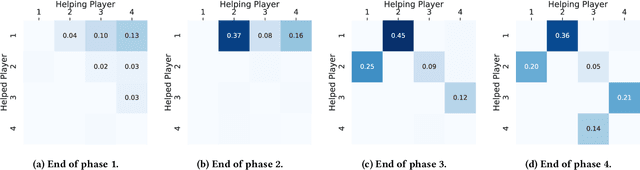
The real world is awash with multi-agent problems that require collective action by self-interested agents, from the routing of packets across a computer network to the management of irrigation systems. Such systems have local incentives for individuals, whose behavior has an impact on the global outcome for the group. Given appropriate mechanisms describing agent interaction, groups may achieve socially beneficial outcomes, even in the face of short-term selfish incentives. In many cases, collective action problems possess an underlying graph structure, whose topology crucially determines the relationship between local decisions and emergent global effects. Such scenarios have received great attention through the lens of network games. However, this abstraction typically collapses important dimensions, such as geometry and time, relevant to the design of mechanisms promoting cooperation. In parallel work, multi-agent deep reinforcement learning has shown great promise in modelling the emergence of self-organized cooperation in complex gridworld domains. Here we apply this paradigm in graph-structured collective action problems. Using multi-agent deep reinforcement learning, we simulate an agent society for a variety of plausible mechanisms, finding clear transitions between different equilibria over time. We define analytic tools inspired by related literatures to measure the social outcomes, and use these to draw conclusions about the efficacy of different environmental interventions. Our methods have implications for mechanism design in both human and artificial agent systems.
DADI: Dynamic Discovery of Fair Information with Adversarial Reinforcement Learning
Oct 30, 2019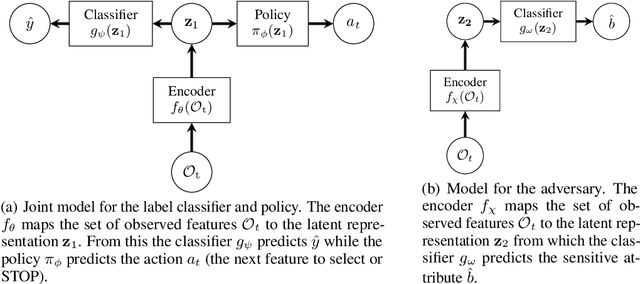
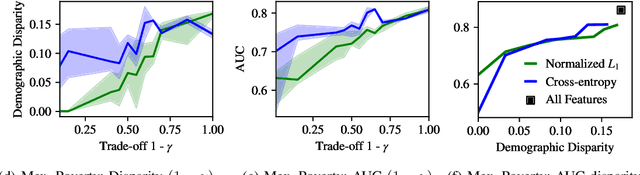
We introduce a framework for dynamic adversarial discovery of information (DADI), motivated by a scenario where information (a feature set) is used by third parties with unknown objectives. We train a reinforcement learning agent to sequentially acquire a subset of the information while balancing accuracy and fairness of predictors downstream. Based on the set of already acquired features, the agent decides dynamically to either collect more information from the set of available features or to stop and predict using the information that is currently available. Building on previous work exploring adversarial representation learning, we attain group fairness (demographic parity) by rewarding the agent with the adversary's loss, computed over the final feature set. Importantly, however, the framework provides a more general starting point for fair or private dynamic information discovery. Finally, we demonstrate empirically, using two real-world datasets, that we can trade-off fairness and predictive performance
VizML: A Machine Learning Approach to Visualization Recommendation
Aug 14, 2018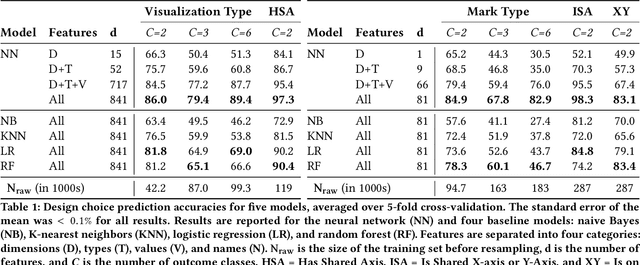
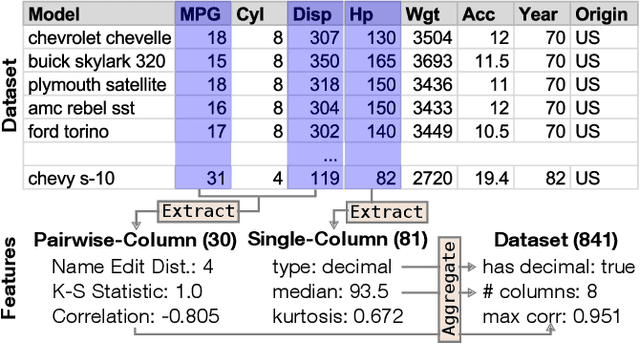
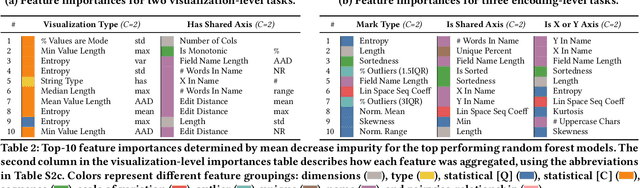
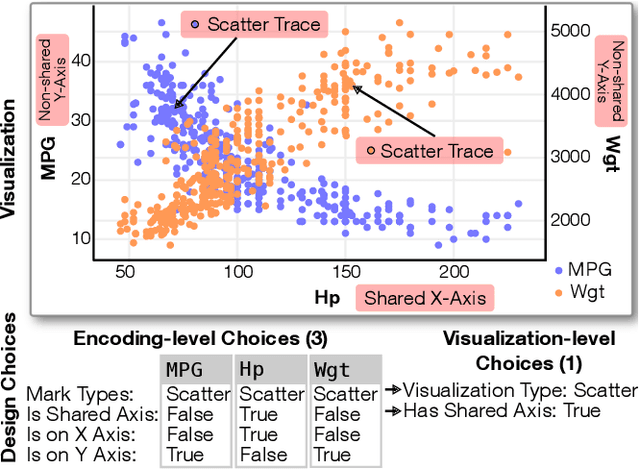
Data visualization should be accessible for all analysts with data, not just the few with technical expertise. Visualization recommender systems aim to lower the barrier to exploring basic visualizations by automatically generating results for analysts to search and select, rather than manually specify. Here, we demonstrate a novel machine learning-based approach to visualization recommendation that learns visualization design choices from a large corpus of datasets and associated visualizations. First, we identify five key design choices made by analysts while creating visualizations, such as selecting a visualization type and choosing to encode a column along the X- or Y-axis. We train models to predict these design choices using one million dataset-visualization pairs collected from a popular online visualization platform. Neural networks predict these design choices with high accuracy compared to baseline models. We report and interpret feature importances from one of these baseline models. To evaluate the generalizability and uncertainty of our approach, we benchmark with a crowdsourced test set, and show that the performance of our model is comparable to human performance when predicting consensus visualization type, and exceeds that of other ML-based systems.