 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Hallucination in Text-to-Image Diffusion Models with Scene-Graph based Question-Answering Agent
Dec 07, 2024



Contemporary Text-to-Image (T2I) models frequently depend on qualitative human evaluations to assess the consistency between synthesized images and the text prompts. There is a demand for quantitative and automatic evaluation tools, given that human evaluation lacks reproducibility. We believe that an effective T2I evaluation metric should accomplish the following: detect instances where the generated images do not align with the textual prompts, a discrepancy we define as the `hallucination problem' in T2I tasks; record the types and frequency of hallucination issues, aiding users in understanding the causes of errors; and provide a comprehensive and intuitive scoring that close to human standard. To achieve these objectives, we propose a method based on large language models (LLMs) for conducting question-answering with an extracted scene-graph and created a dataset with human-rated scores for generated images. From the methodology perspective, we combine knowledge-enhanced question-answering tasks with image evaluation tasks, making the evaluation metrics more controllable and easier to interpret. For the contribution on the dataset side, we generated 12,000 synthesized images based on 1,000 composited prompts using three advanced T2I models. Subsequently, we conduct human scoring on all synthesized images and prompt pairs to validate the accuracy and effectiveness of our method as an evaluation metric. All generated images and the human-labeled scores will be made publicly available in the future to facilitate ongoing research on this crucial issue. Extensive experiments show that our method aligns more closely with human scoring patterns than other evaluation metrics.
Beyond Color and Lines: Zero-Shot Style-Specific Image Variations with Coordinated Semantics
Oct 24, 2024



Traditionally, style has been primarily considered in terms of artistic elements such as colors, brushstrokes, and lighting. However, identical semantic subjects, like people, boats, and houses, can vary significantly across different artistic traditions, indicating that style also encompasses the underlying semantics. Therefore, in this study, we propose a zero-shot scheme for image variation with coordinated semantics. Specifically, our scheme transforms the image-to-image problem into an image-to-text-to-image problem. The image-to-text operation employs vision-language models e.g., BLIP) to generate text describing the content of the input image, including the objects and their positions. Subsequently, the input style keyword is elaborated into a detailed description of this style and then merged with the content text using the reasoning capabilities of ChatGPT. Finally, the text-to-image operation utilizes a Diffusion model to generate images based on the text prompt. To enable the Diffusion model to accommodate more styles, we propose a fine-tuning strategy that injects text and style constraints into cross-attention. This ensures that the output image exhibits similar semantics in the desired style. To validate the performance of the proposed scheme, we constructed a benchmark comprising images of various styles and scenes and introduced two novel metrics. Despite its simplicity, our scheme yields highly plausible results in a zero-shot manner, particularly for generating stylized images with high-fidelity semantics.
EEG-DIF: Early Warning of Epileptic Seizures through Generative Diffusion Model-based Multi-channel EEG Signals Forecasting
Oct 22, 2024



Multi-channel EEG signals are commonly used for the diagnosis and assessment of diseases such as epilepsy. Currently, various EEG diagnostic algorithms based on deep learning have been developed. However, most research efforts focus solely on diagnosing and classifying current signal data but do not consider the prediction of future trends for early warning. Additionally, since multi-channel EEG can be essentially regarded as the spatio-temporal signal data received by detectors at different locations in the brain, how to construct spatio-temporal information representations of EEG signals to facilitate future trend prediction for multi-channel EEG becomes an important problem. This study proposes a multi-signal prediction algorithm based on generative diffusion models (EEG-DIF), which transforms the multi-signal forecasting task into an image completion task, allowing for comprehensive representation and learning of the spatio-temporal correlations and future developmental patterns of multi-channel EEG signals. Here, we employ a publicly available epilepsy EEG dataset to construct and validate the EEG-DIF. The results demonstrate that our method can accurately predict future trends for multi-channel EEG signals simultaneously. Furthermore, the early warning accuracy for epilepsy seizures based on the generated EEG data reaches 0.89. In general, EEG-DIF provides a novel approach for characterizing multi-channel EEG signals and an innovative early warning algorithm for epilepsy seizures, aiding in optimizing and enhancing the clinical diagnosis process. The code is available at https://github.com/JZK00/EEG-DIF.
DICE: Discrete Inversion Enabling Controllable Editing for Multinomial Diffusion and Masked Generative Models
Oct 10, 2024Discrete diffusion models have achieved success in tasks like image generation and masked language modeling but face limitations in controlled content editing. We introduce DICE (Discrete Inversion for Controllable Editing), the first approach to enable precise inversion for discrete diffusion models, including multinomial diffusion and masked generative models. By recording noise sequences and masking patterns during the reverse diffusion process, DICE enables accurate reconstruction and flexible editing of discrete data without the need for predefined masks or attention manipulation. We demonstrate the effectiveness of DICE across both image and text domains, evaluating it on models such as VQ-Diffusion, Paella, and RoBERTa. Our results show that DICE preserves high data fidelity while enhancing editing capabilities, offering new opportunities for fine-grained content manipulation in discrete spaces. For project webpage, see https://hexiaoxiao-cs.github.io/DICE/.
MAT-SED: A Masked Audio Transformer with Masked-Reconstruction Based Pre-training for Sound Event Detection
Aug 19, 2024

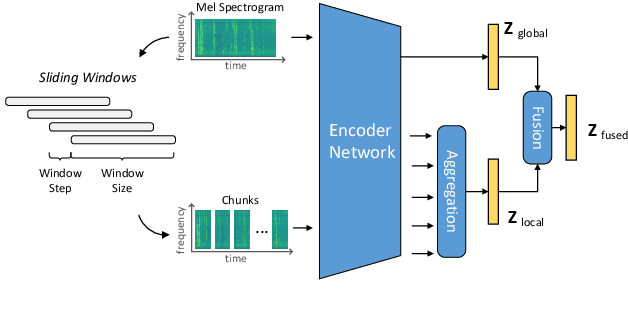

Sound event detection (SED) methods that leverage a large pre-trained Transformer encoder network have shown promising performance in recent DCASE challenges. However, they still rely on an RNN-based context network to model temporal dependencies, largely due to the scarcity of labeled data. In this work, we propose a pure Transformer-based SED model with masked-reconstruction based pre-training, termed MAT-SED. Specifically, a Transformer with relative positional encoding is first designed as the context network, pre-trained by the masked-reconstruction task on all available target data in a self-supervised way. Both the encoder and the context network are jointly fine-tuned in a semi-supervised manner. Furthermore, a global-local feature fusion strategy is proposed to enhance the localization capability. Evaluation of MAT-SED on DCASE2023 task4 surpasses state-of-the-art performance, achieving 0.587/0.896 PSDS1/PSDS2 respectively.
MAT-SED: AMasked Audio Transformer with Masked-Reconstruction Based Pre-training for Sound Event Detection
Aug 16, 2024Sound event detection (SED) methods that leverage a large pre-trained Transformer encoder network have shown promising performance in recent DCASE challenges. However, they still rely on an RNN-based context network to model temporal dependencies, largely due to the scarcity of labeled data. In this work, we propose a pure Transformer-based SED model with masked-reconstruction based pre-training, termed MAT-SED. Specifically, a Transformer with relative positional encoding is first designed as the context network, pre-trained by the masked-reconstruction task on all available target data in a self-supervised way. Both the encoder and the context network are jointly fine-tuned in a semi-supervised manner. Furthermore, a global-local feature fusion strategy is proposed to enhance the localization capability. Evaluation of MAT-SED on DCASE2023 task4 surpasses state-of-the-art performance, achieving 0.587/0.896 PSDS1/PSDS2 respectively.
Make Your Home Safe: Time-aware Unsupervised User Behavior Anomaly Detection in Smart Homes via Loss-guided Mask
Jun 18, 2024



Smart homes, powered by the Internet of Things, offer great convenience but also pose security concerns due to abnormal behaviors, such as improper operations of users and potential attacks from malicious attackers. Several behavior modeling methods have been proposed to identify abnormal behaviors and mitigate potential risks. However, their performance often falls short because they do not effectively learn less frequent behaviors, consider temporal context, or account for the impact of noise in human behaviors. In this paper, we propose SmartGuard, an autoencoder-based unsupervised user behavior anomaly detection framework. First, we design a Loss-guided Dynamic Mask Strategy (LDMS) to encourage the model to learn less frequent behaviors, which are often overlooked during learning. Second, we propose a Three-level Time-aware Position Embedding (TTPE) to incorporate temporal information into positional embedding to detect temporal context anomaly. Third, we propose a Noise-aware Weighted Reconstruction Loss (NWRL) that assigns different weights for routine behaviors and noise behaviors to mitigate the interference of noise behaviors during inference. Comprehensive experiments on three datasets with ten types of anomaly behaviors demonstrates that SmartGuard consistently outperforms state-of-the-art baselines and also offers highly interpretable results.
Unified Modeling Enhanced Multimodal Learning for Precision Neuro-Oncology
Jun 11, 2024



Multimodal learning, integrating histology images and genomics, promises to enhance precision oncology with comprehensive views at microscopic and molecular levels. However, existing methods may not sufficiently model the shared or complementary information for more effective integration. In this study, we introduce a Unified Modeling Enhanced Multimodal Learning (UMEML) framework that employs a hierarchical attention structure to effectively leverage shared and complementary features of both modalities of histology and genomics. Specifically, to mitigate unimodal bias from modality imbalance, we utilize a query-based cross-attention mechanism for prototype clustering in the pathology encoder. Our prototype assignment and modularity strategy are designed to align shared features and minimizes modality gaps. An additional registration mechanism with learnable tokens is introduced to enhance cross-modal feature integration and robustness in multimodal unified modeling. Our experiments demonstrate that our method surpasses previous state-of-the-art approaches in glioma diagnosis and prognosis tasks, underscoring its superiority in precision neuro-Oncology.
P-MSDiff: Parallel Multi-Scale Diffusion for Remote Sensing Image Segmentation
May 30, 2024



Diffusion models and multi-scale features are essential components in semantic segmentation tasks that deal with remote-sensing images. They contribute to improved segmentation boundaries and offer significant contextual information. U-net-like architectures are frequently employed in diffusion models for segmentation tasks. These architectural designs include dense skip connections that may pose challenges for interpreting intermediate features. Consequently, they might not efficiently convey semantic information throughout various layers of the encoder-decoder architecture. To address these challenges, we propose a new model for semantic segmentation known as the diffusion model with parallel multi-scale branches. This model consists of Parallel Multiscale Diffusion modules (P-MSDiff) and a Cross-Bridge Linear Attention mechanism (CBLA). P-MSDiff enhances the understanding of semantic information across multiple levels of granularity and detects repetitive distribution data through the integration of recursive denoising branches. It further facilitates the amalgamation of data by connecting relevant branches to the primary framework to enable concurrent denoising. Furthermore, within the interconnected transformer architecture, the LA module has been substituted with the CBLA module. This module integrates a semidefinite matrix linked to the query into the dot product computation of keys and values. This integration enables the adaptation of queries within the LA framework. This adjustment enhances the structure for multi-head attention computation, leading to enhanced network performance and CBLA is a plug-and-play module. Our model demonstrates superior performance based on the J1 metric on both the UAVid and Vaihingen Building datasets, showing improvements of 1.60% and 1.40% over strong baseline models, respectively.
Evaluating the Application of ChatGPT in Outpatient Triage Guidance: A Comparative Study
Apr 27, 2024



The integration of Artificial Intelligence (AI) in healthcare presents a transformative potential for enhancing operational efficiency and health outcomes. Large Language Models (LLMs), such as ChatGPT, have shown their capabilities in supporting medical decision-making. Embedding LLMs in medical systems is becoming a promising trend in healthcare development. The potential of ChatGPT to address the triage problem in emergency departments has been examined, while few studies have explored its application in outpatient departments. With a focus on streamlining workflows and enhancing efficiency for outpatient triage, this study specifically aims to evaluate the consistency of responses provided by ChatGPT in outpatient guidance, including both within-version response analysis and between-version comparisons. For within-version, the results indicate that the internal response consistency for ChatGPT-4.0 is significantly higher than ChatGPT-3.5 (p=0.03) and both have a moderate consistency (71.2% for 4.0 and 59.6% for 3.5) in their top recommendation. However, the between-version consistency is relatively low (mean consistency score=1.43/3, median=1), indicating few recommendations match between the two versions. Also, only 50% top recommendations match perfectly in the comparisons. Interestingly, ChatGPT-3.5 responses are more likely to be complete than those from ChatGPT-4.0 (p=0.02), suggesting possible differences in information processing and response generation between the two versions. The findings offer insights into AI-assisted outpatient operations, while also facilitating the exploration of potentials and limitations of LLMs in healthcare utilization. Future research may focus on carefully optimizing LLMs and AI integration in healthcare systems based on ergonomic and human factors principles, precisely aligning with the specific needs of effective outpatient triage.