 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Augmentation Module in Contrastive Learning: Learning Hierarchical Augmentation Invariance with Expanded Views
Jun 01, 2022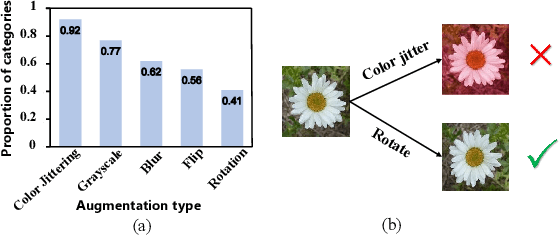


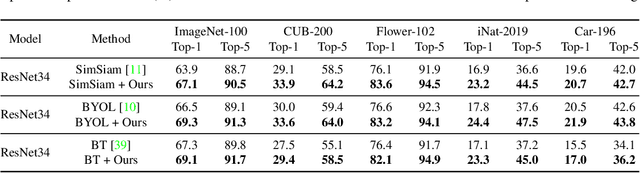
A data augmentation module is utilized in contrastive learning to transform the given data example into two views, which is considered essential and irreplaceable. However, the predetermined composition of multiple data augmentations brings two drawbacks. First, the artificial choice of augmentation types brings specific representational invariances to the model, which have different degrees of positive and negative effects on different downstream tasks. Treating each type of augmentation equally during training makes the model learn non-optimal representations for various downstream tasks and limits the flexibility to choose augmentation types beforehand. Second, the strong data augmentations used in classic contrastive learning methods may bring too much invariance in some cases, and fine-grained information that is essential to some downstream tasks may be lost. This paper proposes a general method to alleviate these two problems by considering where and what to contrast in a general contrastive learning framework. We first propose to learn different augmentation invariances at different depths of the model according to the importance of each data augmentation instead of learning representational invariances evenly in the backbone. We then propose to expand the contrast content with augmentation embeddings to reduce the misleading effects of strong data augmentations. Experiments based on several baseline methods demonstrate that we learn better representations for various benchmarks on classification, detection, and segmentation downstream tasks.
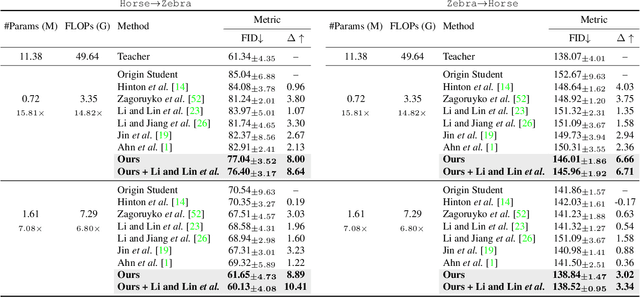
Region-aware Knowledge Distillation for Efficient Image-to-Image Translation
May 25, 2022
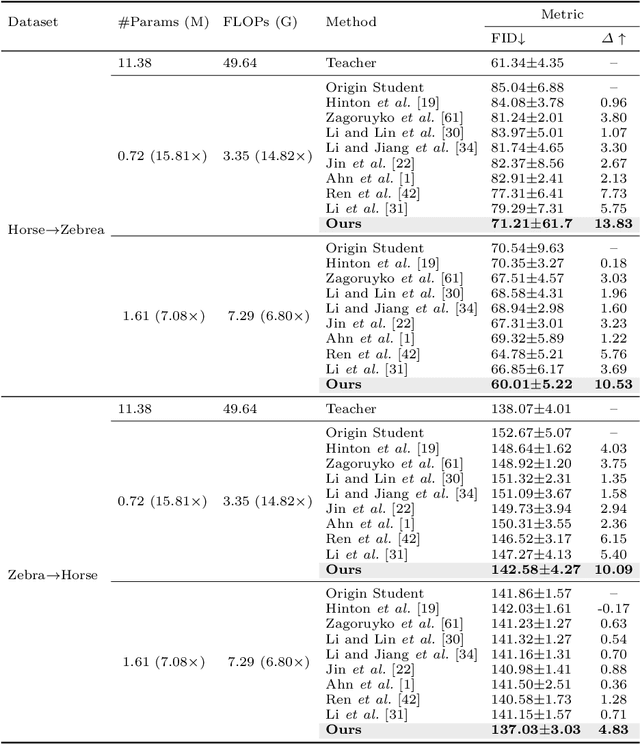
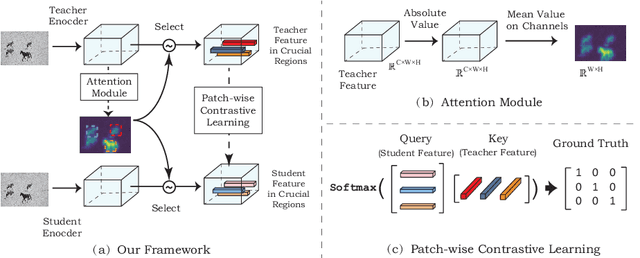
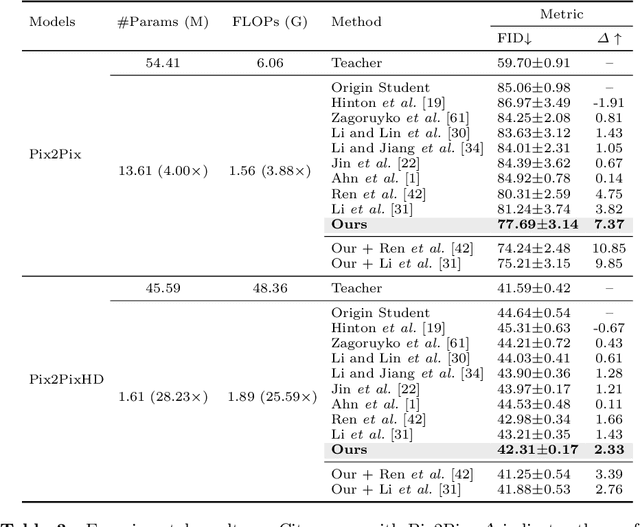
Recent progress in image-to-image translation has witnessed the success of generative adversarial networks (GANs). However, GANs usually contain a huge number of parameters, which lead to intolerant memory and computation consumption and limit their deployment on edge devices. To address this issue, knowledge distillation is proposed to transfer the knowledge from a cumbersome teacher model to an efficient student model. However, most previous knowledge distillation methods are designed for image classification and lead to limited performance in image-to-image translation. In this paper, we propose Region-aware Knowledge Distillation ReKo to compress image-to-image translation models. Firstly, ReKo adaptively finds the crucial regions in the images with an attention module. Then, patch-wise contrastive learning is adopted to maximize the mutual information between students and teachers in these crucial regions. Experiments with eight comparison methods on nine datasets demonstrate the substantial effectiveness of ReKo on both paired and unpaired image-to-image translation. For instance, our 7.08X compressed and 6.80X accelerated CycleGAN student outperforms its teacher by 1.33 and 1.04 FID scores on Horse to Zebra and Zebra to Horse, respectively. Codes will be released on GitHub.
PointDistiller: Structured Knowledge Distillation Towards Efficient and Compact 3D Detection
May 23, 2022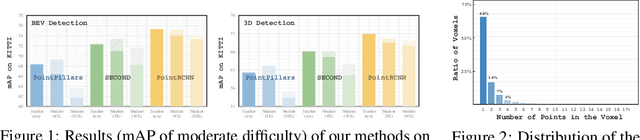
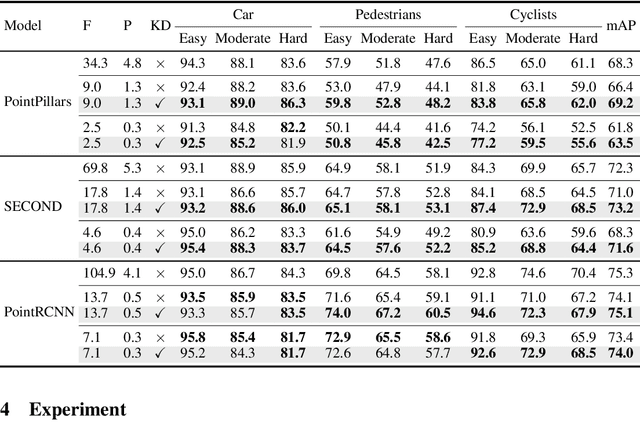
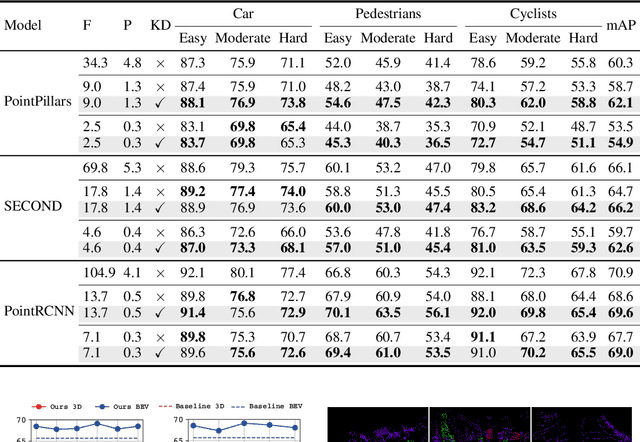
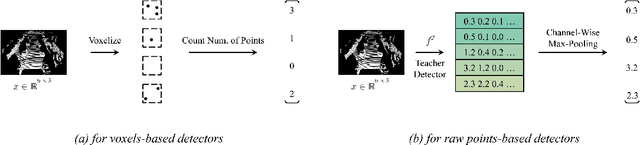
The remarkable breakthroughs in point cloud representation learning have boosted their usage in real-world applications such as self-driving cars and virtual reality. However, these applications usually have an urgent requirement for not only accurate but also efficient 3D object detection. Recently, knowledge distillation has been proposed as an effective model compression technique, which transfers the knowledge from an over-parameterized teacher to a lightweight student and achieves consistent effectiveness in 2D vision. However, due to point clouds' sparsity and irregularity, directly applying previous image-based knowledge distillation methods to point cloud detectors usually leads to unsatisfactory performance. To fill the gap, this paper proposes PointDistiller, a structured knowledge distillation framework for point clouds-based 3D detection. Concretely, PointDistiller includes local distillation which extracts and distills the local geometric structure of point clouds with dynamic graph convolution and reweighted learning strategy, which highlights student learning on the crucial points or voxels to improve knowledge distillation efficiency. Extensive experiments on both voxels-based and raw points-based detectors have demonstrated the effectiveness of our method over seven previous knowledge distillation methods. For instance, our 4X compressed PointPillars student achieves 2.8 and 3.4 mAP improvements on BEV and 3D object detection, outperforming its teacher by 0.9 and 1.8 mAP, respectively. Codes have been released at https://github.com/RunpeiDong/PointDistiller.
Learn from Unpaired Data for Image Restoration: A Variational Bayes Approach
Apr 21, 2022



Collecting paired training data is difficult in practice, but the unpaired samples broadly exist. Current approaches aim at generating synthesized training data from the unpaired samples by exploring the relationship between the corrupted and clean data. This work proposes LUD-VAE, a deep generative method to learn the joint probability density function from data sampled from marginal distributions. Our approach is based on a carefully designed probabilistic graphical model in which the clean and corrupted data domains are conditionally independent. Using variational inference, we maximize the evidence lower bound (ELBO) to estimate the joint probability density function. Furthermore, we show that the ELBO is computable without paired samples under the inference invariant assumption. This property provides the mathematical rationale of our approach in the unpaired setting. Finally, we apply our method to real-world image denoising and super-resolution tasks and train the models using the synthetic data generated by the LUD-VAE. Experimental results validate the advantages of our method over other learnable approaches.
Unsupervised Deep Learning Meets Chan-Vese Model
Apr 14, 2022

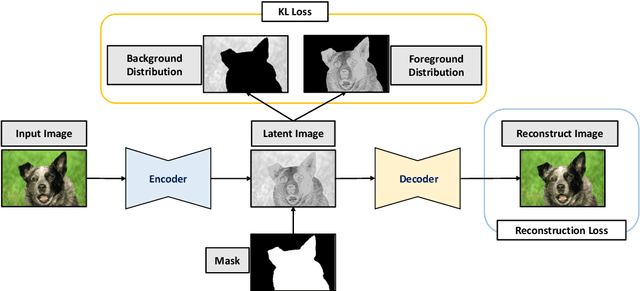
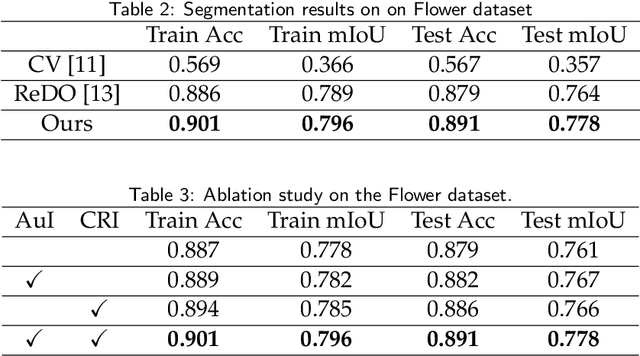
The Chan-Vese (CV) model is a classic region-based method in image segmentation. However, its piecewise constant assumption does not always hold for practical applications. Many improvements have been proposed but the issue is still far from well solved. In this work, we propose an unsupervised image segmentation approach that integrates the CV model with deep neural networks, which significantly improves the original CV model's segmentation accuracy. Our basic idea is to apply a deep neural network that maps the image into a latent space to alleviate the violation of the piecewise constant assumption in image space. We formulate this idea under the classic Bayesian framework by approximating the likelihood with an evidence lower bound (ELBO) term while keeping the prior term in the CV model. Thus, our model only needs the input image itself and does not require pre-training from external datasets. Moreover, we extend the idea to multi-phase case and dataset based unsupervised image segmentation. Extensive experiments validate the effectiveness of our model and show that the proposed method is noticeably better than other unsupervised segmentation approaches.
Wavelet Knowledge Distillation: Towards Efficient Image-to-Image Translation
Mar 12, 2022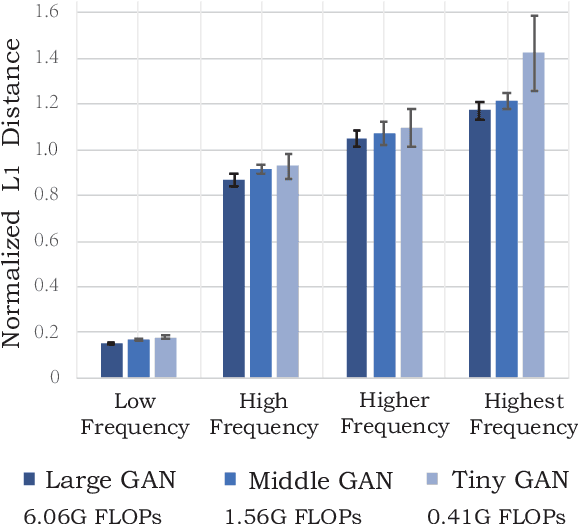
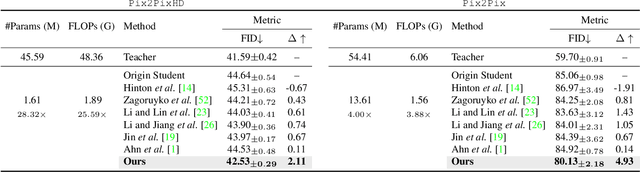
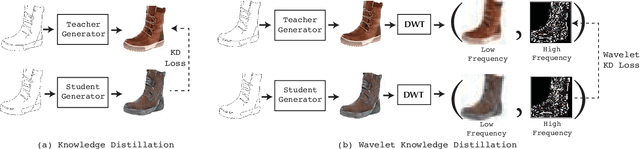
Remarkable achievements have been attained with Generative Adversarial Networks (GANs) in image-to-image translation. However, due to a tremendous amount of parameters, state-of-the-art GANs usually suffer from low efficiency and bulky memory usage. To tackle this challenge, firstly, this paper investigates GANs performance from a frequency perspective. The results show that GANs, especially small GANs lack the ability to generate high-quality high frequency information. To address this problem, we propose a novel knowledge distillation method referred to as wavelet knowledge distillation. Instead of directly distilling the generated images of teachers, wavelet knowledge distillation first decomposes the images into different frequency bands with discrete wavelet transformation and then only distills the high frequency bands. As a result, the student GAN can pay more attention to its learning on high frequency bands. Experiments demonstrate that our method leads to 7.08 times compression and 6.80 times acceleration on CycleGAN with almost no performance drop. Additionally, we have studied the relation between discriminators and generators which shows that the compression of discriminators can promote the performance of compressed generators.
Finding the Task-Optimal Low-Bit Sub-Distribution in Deep Neural Networks
Jan 13, 2022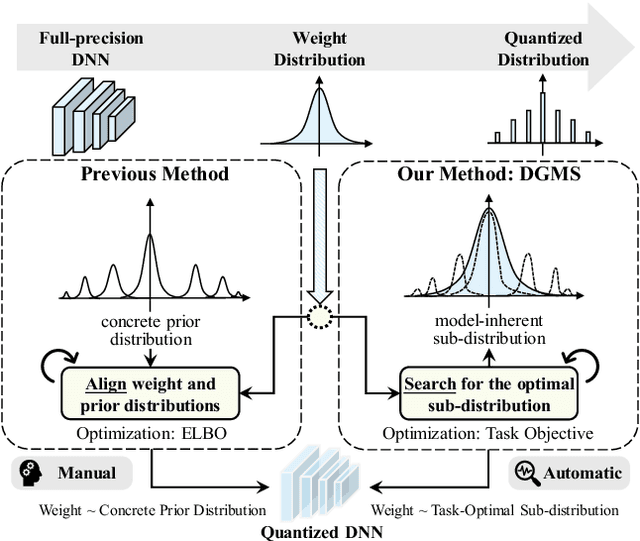
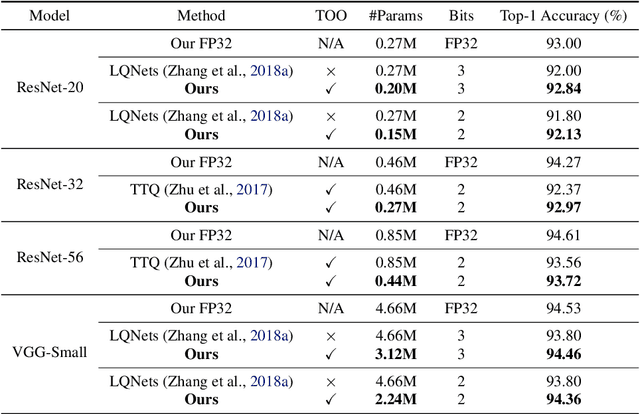
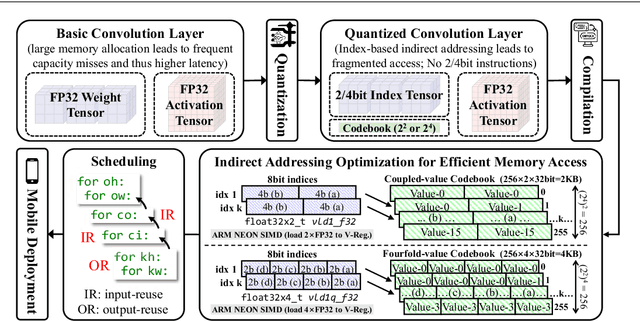
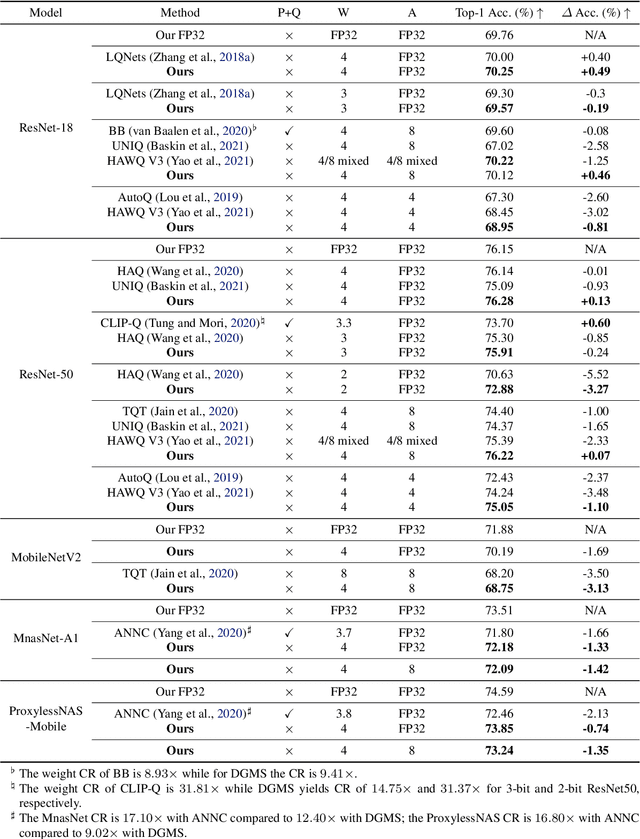
Quantized neural networks typically require smaller memory footprints and lower computation complexity, which is crucial for efficient deployment. However, quantization inevitably leads to a distribution divergence from the original network, which generally degrades the performance. To tackle this issue, massive efforts have been made, but most existing approaches lack statistical considerations and depend on several manual configurations. In this paper, we present an adaptive-mapping quantization method to learn an optimal latent sub-distribution that is inherent within models and smoothly approximated with a concrete Gaussian Mixture (GM). In particular, the network weights are projected in compliance with the GM-approximated sub-distribution. This sub-distribution evolves along with the weight update in a co-tuning schema guided by the direct task-objective optimization. Sufficient experiments on image classification and object detection over various modern architectures demonstrate the effectiveness, generalization property, and transferability of the proposed method. Besides, an efficient deployment flow for the mobile CPU is developed, achieving up to 7.46$\times$ inference acceleration on an octa-core ARM CPU. Codes have been publicly released on Github (https://github.com/RunpeiDong/DGMS).
AFEC: Active Forgetting of Negative Transfer in Continual Learning
Nov 04, 2021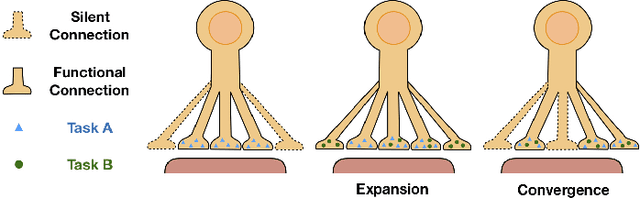
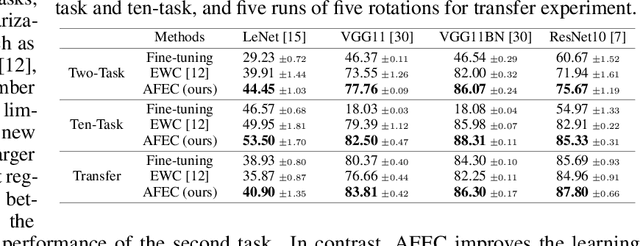
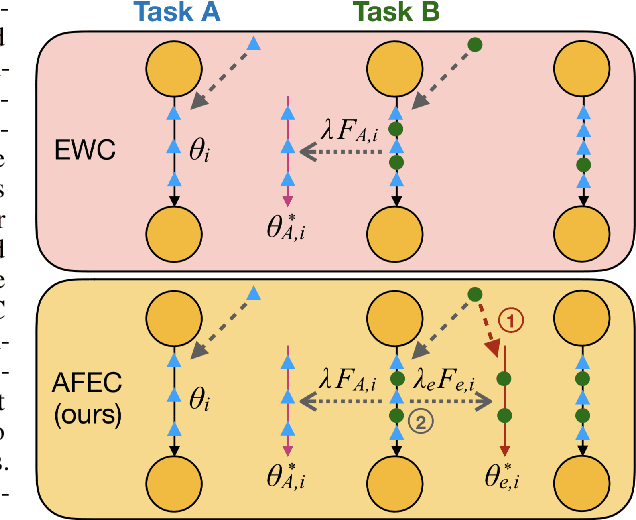
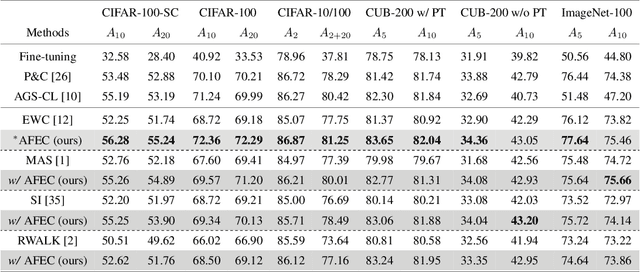
Continual learning aims to learn a sequence of tasks from dynamic data distributions. Without accessing to the old training samples, knowledge transfer from the old tasks to each new task is difficult to determine, which might be either positive or negative. If the old knowledge interferes with the learning of a new task, i.e., the forward knowledge transfer is negative, then precisely remembering the old tasks will further aggravate the interference, thus decreasing the performance of continual learning. By contrast, biological neural networks can actively forget the old knowledge that conflicts with the learning of a new experience, through regulating the learning-triggered synaptic expansion and synaptic convergence. Inspired by the biological active forgetting, we propose to actively forget the old knowledge that limits the learning of new tasks to benefit continual learning. Under the framework of Bayesian continual learning, we develop a novel approach named Active Forgetting with synaptic Expansion-Convergence (AFEC). Our method dynamically expands parameters to learn each new task and then selectively combines them, which is formally consistent with the underlying mechanism of biological active forgetting. We extensively evaluate AFEC on a variety of continual learning benchmarks, including CIFAR-10 regression tasks, visual classification tasks and Atari reinforcement tasks, where AFEC effectively improves the learning of new tasks and achieves the state-of-the-art performance in a plug-and-play way.
Multi-Glimpse Network: A Robust and Efficient Classification Architecture based on Recurrent Downsampled Attention
Nov 03, 2021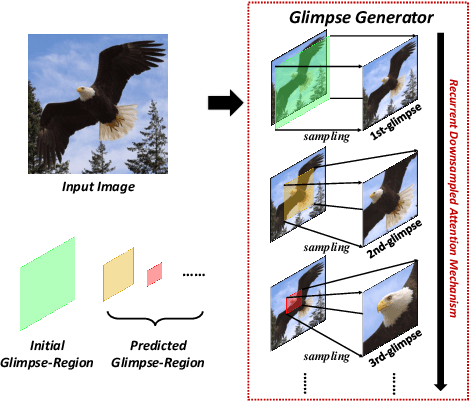
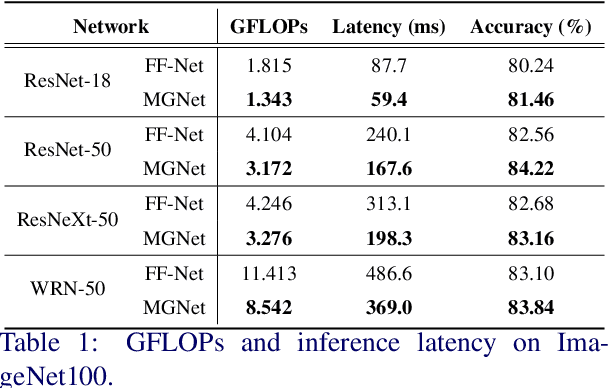
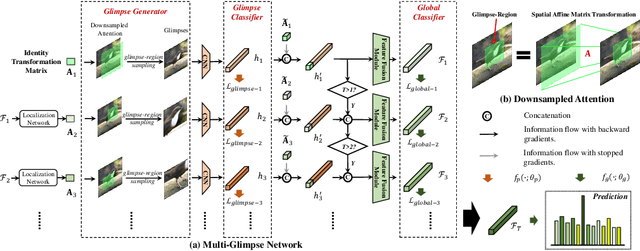
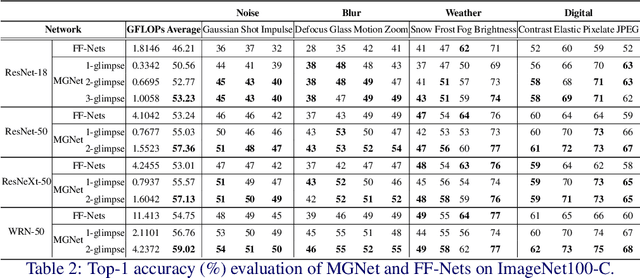
Most feedforward convolutional neural networks spend roughly the same efforts for each pixel. Yet human visual recognition is an interaction between eye movements and spatial attention, which we will have several glimpses of an object in different regions. Inspired by this observation, we propose an end-to-end trainable Multi-Glimpse Network (MGNet) which aims to tackle the challenges of high computation and the lack of robustness based on recurrent downsampled attention mechanism. Specifically, MGNet sequentially selects task-relevant regions of an image to focus on and then adaptively combines all collected information for the final prediction. MGNet expresses strong resistance against adversarial attacks and common corruptions with less computation. Also, MGNet is inherently more interpretable as it explicitly informs us where it focuses during each iteration. Our experiments on ImageNet100 demonstrate the potential of recurrent downsampled attention mechanisms to improve a single feedforward manner. For example, MGNet improves 4.76% accuracy on average in common corruptions with only 36.9% computational cost. Moreover, while the baseline incurs an accuracy drop to 7.6%, MGNet manages to maintain 44.2% accuracy in the same PGD attack strength with ResNet-50 backbone. Our code is available at https://github.com/siahuat0727/MGNet.
An Image Enhancing Pattern-based Sparsity for Real-time Inference on Mobile Devices
Feb 22, 2020
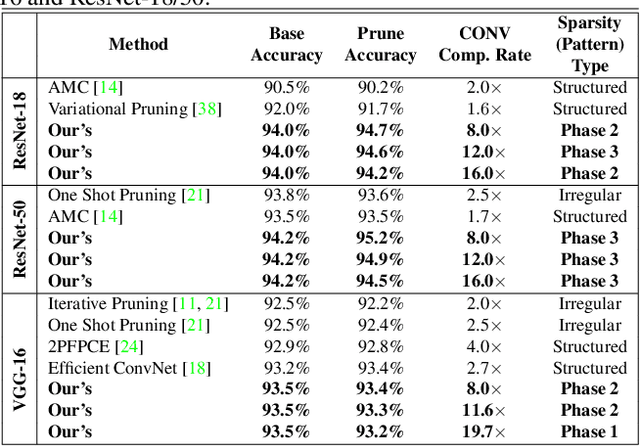
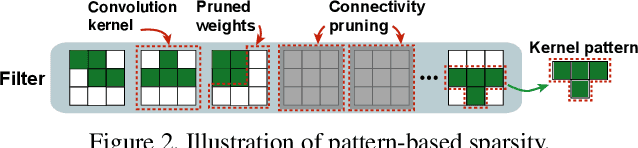
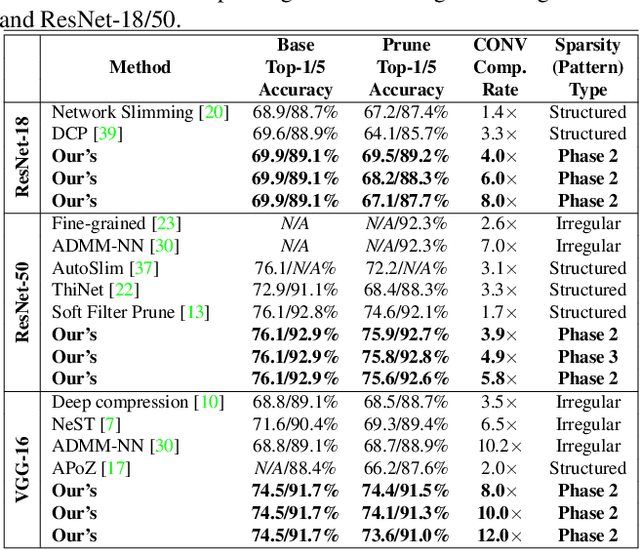
Weight pruning has been widely acknowledged as a straightforward and effective method to eliminate redundancy in Deep Neural Networks (DNN), thereby achieving acceleration on various platforms. However, most of the pruning techniques are essentially trade-offs between model accuracy and regularity which lead to impaired inference accuracy and limited on-device acceleration performance. To solve the problem, we introduce a new sparsity dimension, namely pattern-based sparsity that comprises pattern and connectivity sparsity, and becoming both highly accurate and hardware friendly. With carefully designed patterns, the proposed pruning unprecedentedly and consistently achieves accuracy enhancement and better feature extraction ability on different DNN structures and datasets, and our pattern-aware pruning framework also achieves pattern library extraction, pattern selection, pattern and connectivity pruning and weight training simultaneously. Our approach on the new pattern-based sparsity naturally fits into compiler optimization for highly efficient DNN execution on mobile platforms. To the best of our knowledge, it is the first time that mobile devices achieve real-time inference for the large-scale DNN models thanks to the unique spatial property of pattern-based sparsity and the help of the code generation capability of compilers.