 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Bias Mitigation in Multiple-Choice Visual Question Answering and Beyond
Oct 31, 2023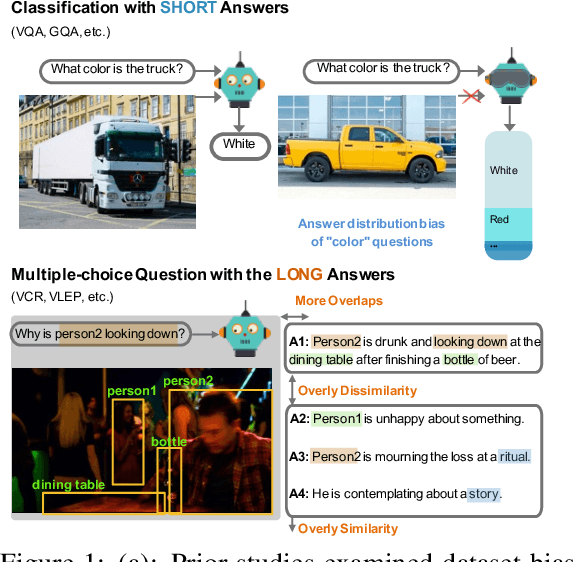


Vision-language (VL) understanding tasks evaluate models' comprehension of complex visual scenes through multiple-choice questions. However, we have identified two dataset biases that models can exploit as shortcuts to resolve various VL tasks correctly without proper understanding. The first type of dataset bias is \emph{Unbalanced Matching} bias, where the correct answer overlaps the question and image more than the incorrect answers. The second type of dataset bias is \emph{Distractor Similarity} bias, where incorrect answers are overly dissimilar to the correct answer but significantly similar to other incorrect answers within the same sample. To address these dataset biases, we first propose Adversarial Data Synthesis (ADS) to generate synthetic training and debiased evaluation data. We then introduce Intra-sample Counterfactual Training (ICT) to assist models in utilizing the synthesized training data, particularly the counterfactual data, via focusing on intra-sample differentiation. Extensive experiments demonstrate the effectiveness of ADS and ICT in consistently improving model performance across different benchmarks, even in domain-shifted scenarios.
* EMNLP 2023
What's "up" with vision-language models? Investigating their struggle with spatial reasoning
Oct 30, 2023Recent vision-language (VL) models are powerful, but can they reliably distinguish "right" from "left"? We curate three new corpora to quantify model comprehension of such basic spatial relations. These tests isolate spatial reasoning more precisely than existing datasets like VQAv2, e.g., our What'sUp benchmark contains sets of photographs varying only the spatial relations of objects, keeping their identity fixed (see Figure 1: models must comprehend not only the usual case of a dog under a table, but also, the same dog on top of the same table). We evaluate 18 VL models, finding that all perform poorly, e.g., BLIP finetuned on VQAv2, which nears human parity on VQAv2, achieves 56% accuracy on our benchmarks vs. humans at 99%. We conclude by studying causes of this surprising behavior, finding: 1) that popular vision-language pretraining corpora like LAION-2B contain little reliable data for learning spatial relationships; and 2) that basic modeling interventions like up-weighting preposition-containing instances or fine-tuning on our corpora are not sufficient to address the challenges our benchmarks pose. We are hopeful that these corpora will facilitate further research, and we release our data and code at https://github.com/amitakamath/whatsup_vlms.
"Kelly is a Warm Person, Joseph is a Role Model": Gender Biases in LLM-Generated Reference Letters
Oct 28, 2023



Large Language Models (LLMs) have recently emerged as an effective tool to assist individuals in writing various types of content, including professional documents such as recommendation letters. Though bringing convenience, this application also introduces unprecedented fairness concerns. Model-generated reference letters might be directly used by users in professional scenarios. If underlying biases exist in these model-constructed letters, using them without scrutinization could lead to direct societal harms, such as sabotaging application success rates for female applicants. In light of this pressing issue, it is imminent and necessary to comprehensively study fairness issues and associated harms in this real-world use case. In this paper, we critically examine gender biases in LLM-generated reference letters. Drawing inspiration from social science findings, we design evaluation methods to manifest biases through 2 dimensions: (1) biases in language style and (2) biases in lexical content. We further investigate the extent of bias propagation by analyzing the hallucination bias of models, a term that we define to be bias exacerbation in model-hallucinated contents. Through benchmarking evaluation on 2 popular LLMs- ChatGPT and Alpaca, we reveal significant gender biases in LLM-generated recommendation letters. Our findings not only warn against using LLMs for this application without scrutinization, but also illuminate the importance of thoroughly studying hidden biases and harms in LLM-generated professional documents.
Are Personalized Stochastic Parrots More Dangerous? Evaluating Persona Biases in Dialogue Systems
Oct 23, 2023



Recent advancements in Large Language Models empower them to follow freeform instructions, including imitating generic or specific demographic personas in conversations. We define generic personas to represent demographic groups, such as "an Asian person", whereas specific personas may take the form of specific popular Asian names like "Yumi". While the adoption of personas enriches user experiences by making dialogue systems more engaging and approachable, it also casts a shadow of potential risk by exacerbating social biases within model responses, thereby causing societal harm through interactions with users. In this paper, we systematically study "persona biases", which we define to be the sensitivity of dialogue models' harmful behaviors contingent upon the personas they adopt. We categorize persona biases into biases in harmful expression and harmful agreement, and establish a comprehensive evaluation framework to measure persona biases in five aspects: Offensiveness, Toxic Continuation, Regard, Stereotype Agreement, and Toxic Agreement. Additionally, we propose to investigate persona biases by experimenting with UNIVERSALPERSONA, a systematically constructed persona dataset encompassing various types of both generic and specific model personas. Through benchmarking on four different models -- including Blender, ChatGPT, Alpaca, and Vicuna -- our study uncovers significant persona biases in dialogue systems. Our findings also underscore the pressing need to revisit the use of personas in dialogue agents to ensure safe application.
Rethinking Model Selection and Decoding for Keyphrase Generation with Pre-trained Sequence-to-Sequence Models
Oct 22, 2023



Keyphrase Generation (KPG) is a longstanding task in NLP with widespread applications. The advent of sequence-to-sequence (seq2seq) pre-trained language models (PLMs) has ushered in a transformative era for KPG, yielding promising performance improvements. However, many design decisions remain unexplored and are often made arbitrarily. This paper undertakes a systematic analysis of the influence of model selection and decoding strategies on PLM-based KPG. We begin by elucidating why seq2seq PLMs are apt for KPG, anchored by an attention-driven hypothesis. We then establish that conventional wisdom for selecting seq2seq PLMs lacks depth: (1) merely increasing model size or performing task-specific adaptation is not parameter-efficient; (2) although combining in-domain pre-training with task adaptation benefits KPG, it does partially hinder generalization. Regarding decoding, we demonstrate that while greedy search achieves strong F1 scores, it lags in recall compared with sampling-based methods. Based on these insights, we propose DeSel, a likelihood-based decode-select algorithm for seq2seq PLMs. DeSel improves greedy search by an average of 4.7% semantic F1 across five datasets. Our collective findings pave the way for deeper future investigations into PLM-based KPG.
An Exploration of In-Context Learning for Speech Language Model
Oct 19, 2023



Ever since the development of GPT-3 in the natural language processing (NLP) field, in-context learning (ICL) has played an important role in utilizing large language models (LLMs). By presenting the LM utterance-label demonstrations at the input, the LM can accomplish few-shot learning without relying on gradient descent or requiring explicit modification of its parameters. This enables the LM to learn and adapt in a black-box manner. Despite the success of ICL in NLP, little work is exploring the possibility of ICL in speech processing. This study proposes the first exploration of ICL with a speech LM without text supervision. We first show that the current speech LM does not have the ICL capability. With the proposed warmup training, the speech LM can, therefore, perform ICL on unseen tasks. In this work, we verify the feasibility of ICL for speech LM on speech classification tasks.
LACMA: Language-Aligning Contrastive Learning with Meta-Actions for Embodied Instruction Following
Oct 18, 2023



End-to-end Transformers have demonstrated an impressive success rate for Embodied Instruction Following when the environment has been seen in training. However, they tend to struggle when deployed in an unseen environment. This lack of generalizability is due to the agent's insensitivity to subtle changes in natural language instructions. To mitigate this issue, we propose explicitly aligning the agent's hidden states with the instructions via contrastive learning. Nevertheless, the semantic gap between high-level language instructions and the agent's low-level action space remains an obstacle. Therefore, we further introduce a novel concept of meta-actions to bridge the gap. Meta-actions are ubiquitous action patterns that can be parsed from the original action sequence. These patterns represent higher-level semantics that are intuitively aligned closer to the instructions. When meta-actions are applied as additional training signals, the agent generalizes better to unseen environments. Compared to a strong multi-modal Transformer baseline, we achieve a significant 4.5% absolute gain in success rate in unseen environments of ALFRED Embodied Instruction Following. Additional analysis shows that the contrastive objective and meta-actions are complementary in achieving the best results, and the resulting agent better aligns its states with corresponding instructions, making it more suitable for real-world embodied agents. The code is available at: https://github.com/joeyy5588/LACMA.
Will the Prince Get True Love's Kiss? On the Model Sensitivity to Gender Perturbation over Fairytale Texts
Oct 16, 2023



Recent studies show that traditional fairytales are rife with harmful gender biases. To help mitigate these gender biases in fairytales, this work aims to assess learned biases of language models by evaluating their robustness against gender perturbations. Specifically, we focus on Question Answering (QA) tasks in fairytales. Using counterfactual data augmentation to the FairytaleQA dataset, we evaluate model robustness against swapped gender character information, and then mitigate learned biases by introducing counterfactual gender stereotypes during training time. We additionally introduce a novel approach that utilizes the massive vocabulary of language models to support text genres beyond fairytales. Our experimental results suggest that models are sensitive to gender perturbations, with significant performance drops compared to the original testing set. However, when first fine-tuned on a counterfactual training dataset, models are less sensitive to the later introduced anti-gender stereotyped text.
Mitigating Bias for Question Answering Models by Tracking Bias Influence
Oct 13, 2023



Models of various NLP tasks have been shown to exhibit stereotypes, and the bias in the question answering (QA) models is especially harmful as the output answers might be directly consumed by the end users. There have been datasets to evaluate bias in QA models, while bias mitigation technique for the QA models is still under-explored. In this work, we propose BMBI, an approach to mitigate the bias of multiple-choice QA models. Based on the intuition that a model would lean to be more biased if it learns from a biased example, we measure the bias level of a query instance by observing its influence on another instance. If the influenced instance is more biased, we derive that the query instance is biased. We then use the bias level detected as an optimization objective to form a multi-task learning setting in addition to the original QA task. We further introduce a new bias evaluation metric to quantify bias in a comprehensive and sensitive way. We show that our method could be applied to multiple QA formulations across multiple bias categories. It can significantly reduce the bias level in all 9 bias categories in the BBQ dataset while maintaining comparable QA accuracy.
Prompting and Adapter Tuning for Self-supervised Encoder-Decoder Speech Model
Oct 04, 2023



Prompting and adapter tuning have emerged as efficient alternatives to fine-tuning (FT) methods. However, existing studies on speech prompting focused on classification tasks and failed on more complex sequence generation tasks. Besides, adapter tuning is primarily applied with a focus on encoder-only self-supervised models. Our experiments show that prompting on Wav2Seq, a self-supervised encoder-decoder model, surpasses previous works in sequence generation tasks. It achieves a remarkable 53% relative improvement in word error rate for ASR and a 27% in F1 score for slot filling. Additionally, prompting competes with the FT method in the low-resource scenario. Moreover, we show the transferability of prompting and adapter tuning on Wav2Seq in cross-lingual ASR. When limited trainable parameters are involved, prompting and adapter tuning consistently outperform conventional FT across 7 languages. Notably, in the low-resource scenario, prompting consistently outperforms adapter tuning.