 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Mechanisms in Dynamical Systems: A Case Study with Predator-Prey Models
May 10, 2025Attention mechanisms are widely used in artificial intelligence to enhance performance and interpretability. In this paper, we investigate their utility in modeling classical dynamical systems -- specifically, a noisy predator-prey (Lotka-Volterra) system. We train a simple linear attention model on perturbed time-series data to reconstruct system trajectories. Remarkably, the learned attention weights align with the geometric structure of the Lyapunov function: high attention corresponds to flat regions (where perturbations have small effect), and low attention aligns with steep regions (where perturbations have large effect). We further demonstrate that attention-based weighting can serve as a proxy for sensitivity analysis, capturing key phase-space properties without explicit knowledge of the system equations. These results suggest a novel use of AI-derived attention for interpretable, data-driven analysis and control of nonlinear systems. For example our framework could support future work in biological modeling of circadian rhythms, and interpretable machine learning for dynamical environments.
Propagating Semantic Labels in Video Data
Oct 01, 2023



Semantic Segmentation combines two sub-tasks: the identification of pixel-level image masks and the application of semantic labels to those masks. Recently, so-called Foundation Models have been introduced; general models trained on very large datasets which can be specialized and applied to more specific tasks. One such model, the Segment Anything Model (SAM), performs image segmentation. Semantic segmentation systems such as CLIPSeg and MaskRCNN are trained on datasets of paired segments and semantic labels. Manual labeling of custom data, however, is time-consuming. This work presents a method for performing segmentation for objects in video. Once an object has been found in a frame of video, the segment can then be propagated to future frames; thus reducing manual annotation effort. The method works by combining SAM with Structure from Motion (SfM). The video input to the system is first reconstructed into 3D geometry using SfM. A frame of video is then segmented using SAM. Segments identified by SAM are then projected onto the the reconstructed 3D geometry. In subsequent video frames, the labeled 3D geometry is reprojected into the new perspective, allowing SAM to be invoked fewer times. System performance is evaluated, including the contributions of the SAM and SfM components. Performance is evaluated over three main metrics: computation time, mask IOU with manual labels, and the number of tracking losses. Results demonstrate that the system has substantial computation time improvements over human performance for tracking objects over video frames, but suffers in performance.
Automatic Sign Reading and Localization for Semantic Mapping with an Office Robot
Sep 23, 2022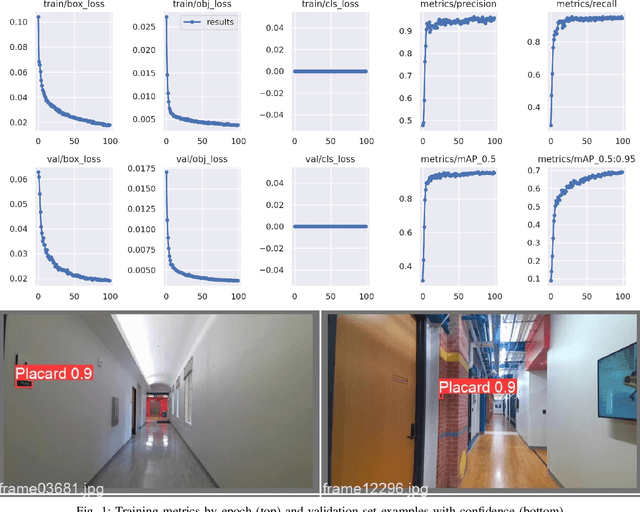

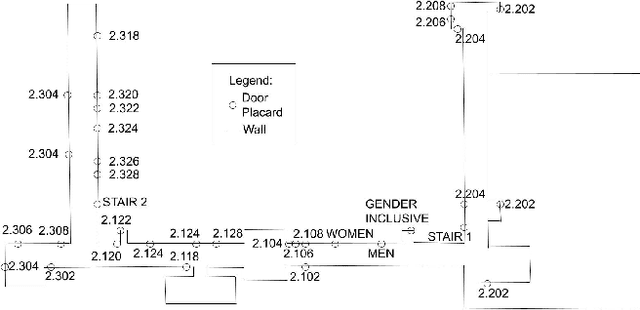
Semantic mapping is the task of providing a robot with a map of its environment beyond the open, navigable space of traditional Simultaneous Localization and Mapping (SLAM) algorithms by attaching semantics to locations. The system presented in this work reads door placards to annotate the locations of offices. Whereas prior work on this system developed hand-crafted detectors, this system leverages YOLOv5 for sign detection and EAST for text recognition. Placards are localized by computing their pose from a point cloud in a RGB-D camera frame localized by a modified ORB-SLAM. Semantic mapping is accomplished in a post-processing step after robot exploration from video recording. System performance is reported in terms of the number of placards identified, the accuracy of their placement onto a SLAM map, the accuracy of the map built, and the correctness transcribed placard text.
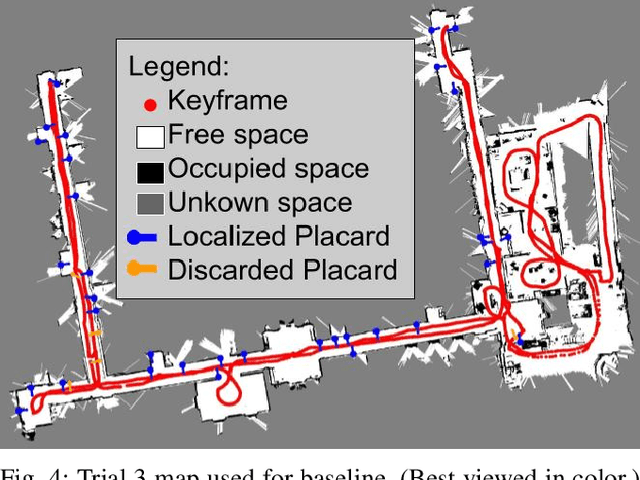
Efficient Placard Discovery for Semantic Mapping During Frontier Exploration
Oct 27, 2021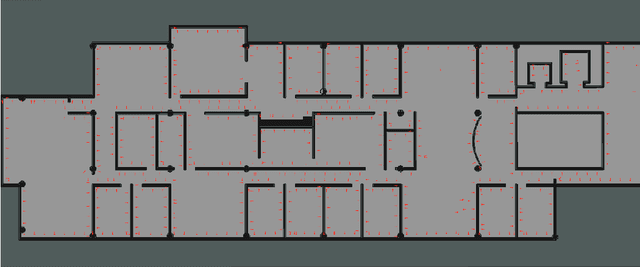
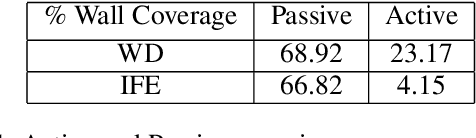

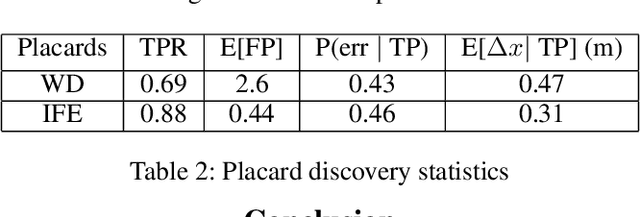
Semantic mapping is the task of providing a robot with a map of its environment beyond the open, navigable space of traditional Simultaneous Localization and Mapping (SLAM) algorithms by attaching semantics to locations. The system presented in this work reads door placards to annotate the locations of offices. Whereas prior work on this system developed hand-crafted detectors, this system leverages YOLOv2 for detection and a segmentation network for segmentation. Placards are localized by computing their pose from a homography computed from a segmented quadrilateral outline. This work also introduces an Interruptable Frontier Exploration algorithm, enabling the robot to explore its environment to construct its SLAM map while pausing to inspect placards observed during this process. This allows the robot to autonomously discover room placards without human intervention while speeding up significantly over previous autonomous exploration methods.
Inverse Kinematics and Sensitivity Minimization of an n-Stack Stewart Platform
Nov 13, 2018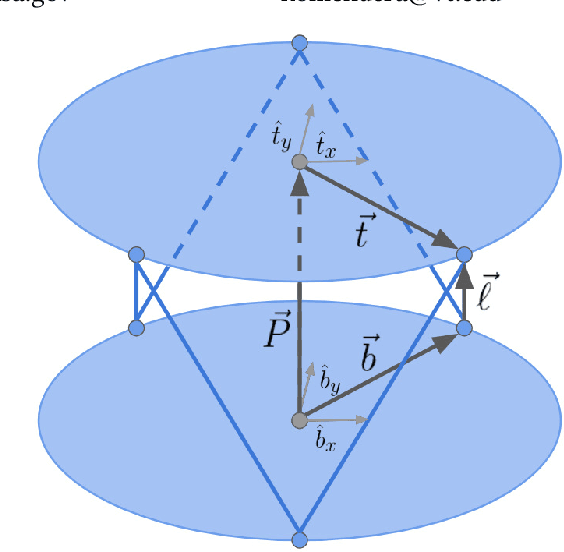
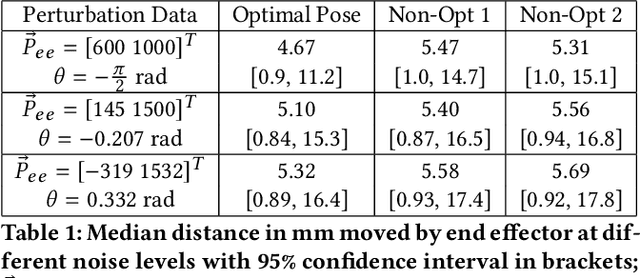
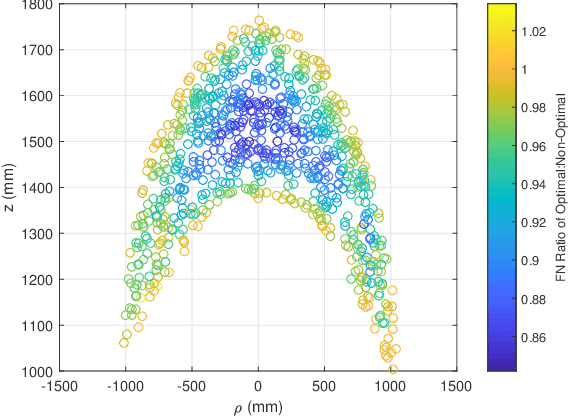
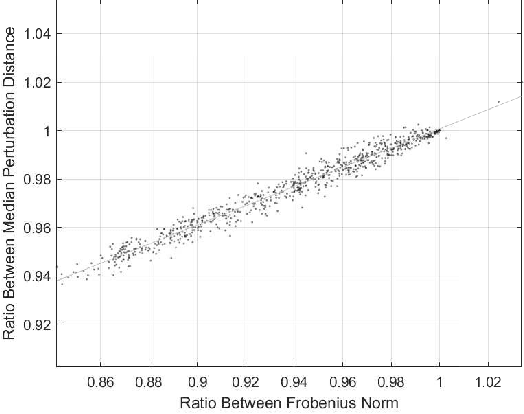
An autonomous system is presented to solve the problem of in space assembly, which can be used to further the NASA goal of deep space exploration. Of particular interest is the assembly of large truss structures, which requires precise and dexterous movement in a changing environment. A prototype of an autonomous manipulator called "Assemblers" was fabricated from an aggregation of Stewart Platform robots for the purpose of researching autonomous in space assembly capabilities. The forward kinematics for an Assembler is described by the set of translations and rotation angles for each component Stewart Platform, from which the position and orientation of the end effector are simple to calculate. However, selecting inverse kinematic poses, defined by the translations and rotation angles, for the Assembler requires coordination between each Stewart Platform and is an underconstrained non-linear optimization problem. For assembly tasks, it is ideal that the pose selected has the least sensitivity to disturbances possible. A method of sensitivity reduction is proposed by minimizing the Frobenius Norm (FN) of the Jacobian for the forward kinematics. The effectiveness of the FN method will be demonstrated through a Monte Carlo simulation method to model random motion internal to the structure.
A Real-Time Solver For Time-Optimal Control Of Omnidirectional Robots with Bounded Acceleration
Oct 07, 2018
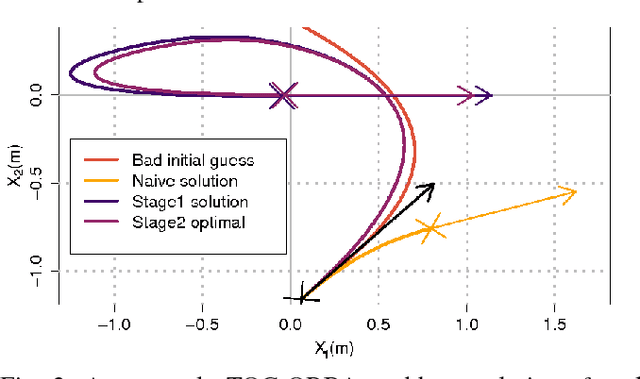
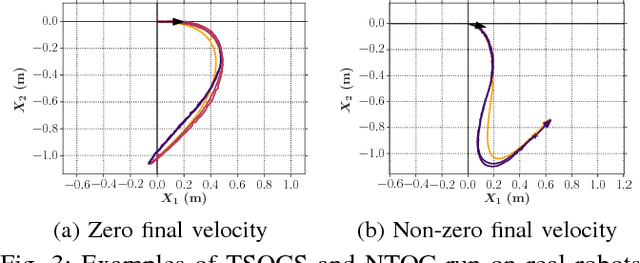
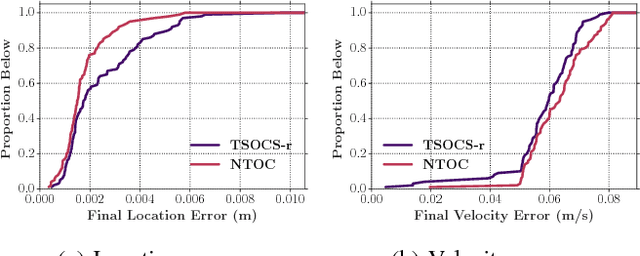
We are interested in the problem of time-optimal control of omnidirectional robots with bounded acceleration (TOC-ORBA). While there exist approximate solutions for such robots, and exact solutions with unbounded acceleration, exact solvers to the TOC-ORBA problem have remained elusive until now. In this paper, we present a real-time solver for true time-optimal control of omnidirectional robots with bounded acceleration. We first derive the general parameterized form of the solution to the TOC-ORBA problem by application of Pontryagin's maximum principle. We then frame the boundary value problem of TOC-ORBA as an optimization problem over the parametrized control space. To overcome local minima and poor initial guesses to the optimization problem, we introduce a two-stage optimal control solver (TSOCS): The first stage computes an upper bound to the total time for the TOC-ORBA problem and holds the time constant while optimizing the parameters of the trajectory to approach the boundary value conditions. The second stage uses the parameters found by the first stage, and relaxes the constraint on the total time to solve for the parameters of the complete TOC-ORBA problem. We further implement TSOCS as a closed loop controller to overcome actuation errors on real robots in real-time. We empirically demonstrate the effectiveness of TSOCS in simulation and on real robots, showing that 1) it runs in real time, generating solutions in less than 0.5ms on average; 2) it generates faster trajectories compared to an approximate solver; and 3) it is able to solve TOC-ORBA problems with non-zero final velocities that were previously unsolvable in real-time.