 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Level Serialized Output Training for Joint Streaming ASR and ST Leveraging Textual Alignments
Jul 07, 2023



In real-world applications, users often require both translations and transcriptions of speech to enhance their comprehension, particularly in streaming scenarios where incremental generation is necessary. This paper introduces a streaming Transformer-Transducer that jointly generates automatic speech recognition (ASR) and speech translation (ST) outputs using a single decoder. To produce ASR and ST content effectively with minimal latency, we propose a joint token-level serialized output training method that interleaves source and target words by leveraging an off-the-shelf textual aligner. Experiments in monolingual (it-en) and multilingual (\{de,es,it\}-en) settings demonstrate that our approach achieves the best quality-latency balance. With an average ASR latency of 1s and ST latency of 1.3s, our model shows no degradation or even improves output quality compared to separate ASR and ST models, yielding an average improvement of 1.1 WER and 0.4 BLEU in the multilingual case.
ERNIE-SAT: Speech and Text Joint Pretraining for Cross-Lingual Multi-Speaker Text-to-Speech
Nov 07, 2022



Speech representation learning has improved both speech understanding and speech synthesis tasks for single language. However, its ability in cross-lingual scenarios has not been explored. In this paper, we extend the pretraining method for cross-lingual multi-speaker speech synthesis tasks, including cross-lingual multi-speaker voice cloning and cross-lingual multi-speaker speech editing. We propose a speech-text joint pretraining framework, where we randomly mask the spectrogram and the phonemes given a speech example and its transcription. By learning to reconstruct the masked parts of the input in different languages, our model shows great improvements over speaker-embedding-based multi-speaker TTS methods. Moreover, our framework is end-to-end for both the training and the inference without any finetuning effort. In cross-lingual multi-speaker voice cloning and cross-lingual multi-speaker speech editing tasks, our experiments show that our model outperforms speaker-embedding-based multi-speaker TTS methods. The code and model are publicly available at PaddleSpeech.
Is Self-Supervised Learning More Robust Than Supervised Learning?
Jun 10, 2022
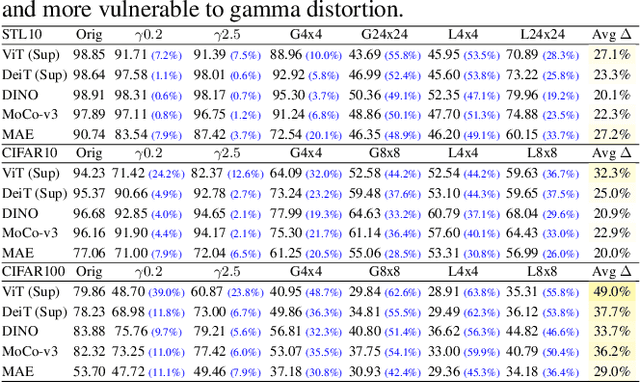
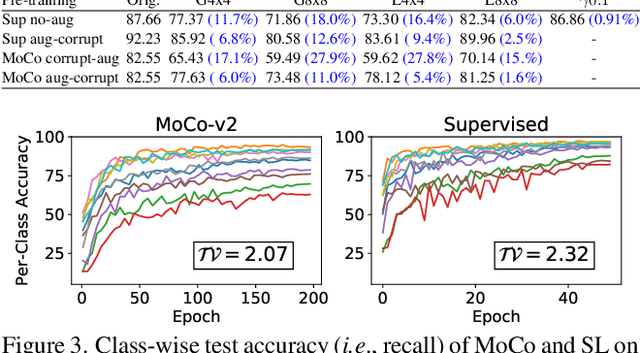

Self-supervised contrastive learning is a powerful tool to learn visual representation without labels. Prior work has primarily focused on evaluating the recognition accuracy of various pre-training algorithms, but has overlooked other behavioral aspects. In addition to accuracy, distributional robustness plays a critical role in the reliability of machine learning models. We design and conduct a series of robustness tests to quantify the behavioral differences between contrastive learning and supervised learning to downstream or pre-training data distribution changes. These tests leverage data corruptions at multiple levels, ranging from pixel-level gamma distortion to patch-level shuffling and to dataset-level distribution shift. Our tests unveil intriguing robustness behaviors of contrastive and supervised learning. On the one hand, under downstream corruptions, we generally observe that contrastive learning is surprisingly more robust than supervised learning. On the other hand, under pre-training corruptions, we find contrastive learning vulnerable to patch shuffling and pixel intensity change, yet less sensitive to dataset-level distribution change. We attempt to explain these results through the role of data augmentation and feature space properties. Our insight has implications in improving the downstream robustness of supervised learning.
PaddleSpeech: An Easy-to-Use All-in-One Speech Toolkit
May 20, 2022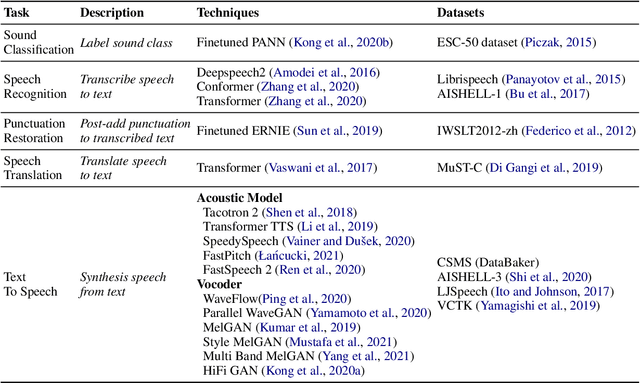
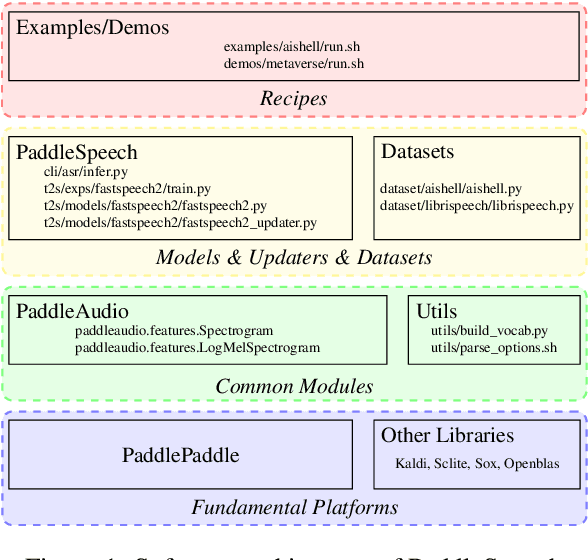
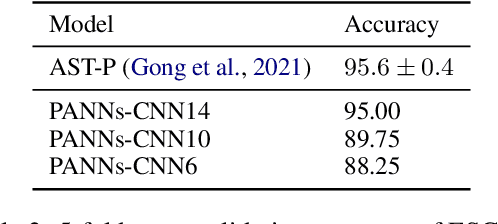
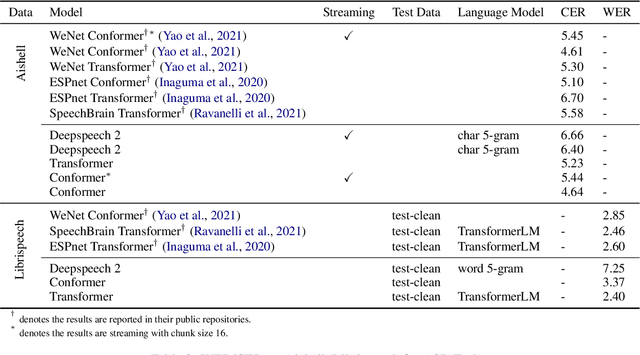
PaddleSpeech is an open-source all-in-one speech toolkit. It aims at facilitating the development and research of speech processing technologies by providing an easy-to-use command-line interface and a simple code structure. This paper describes the design philosophy and core architecture of PaddleSpeech to support several essential speech-to-text and text-to-speech tasks. PaddleSpeech achieves competitive or state-of-the-art performance on various speech datasets and implements the most popular methods. It also provides recipes and pretrained models to quickly reproduce the experimental results in this paper. PaddleSpeech is publicly avaiable at https://github.com/PaddlePaddle/PaddleSpeech.
Data-Driven Adaptive Simultaneous Machine Translation
Apr 27, 2022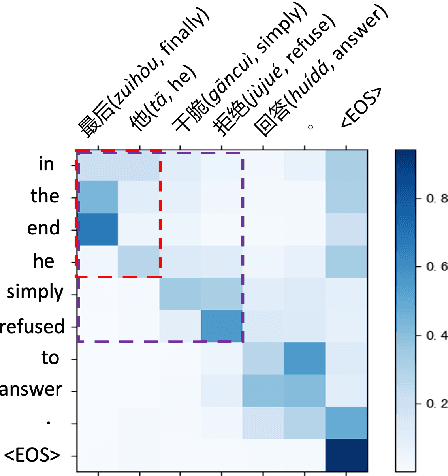
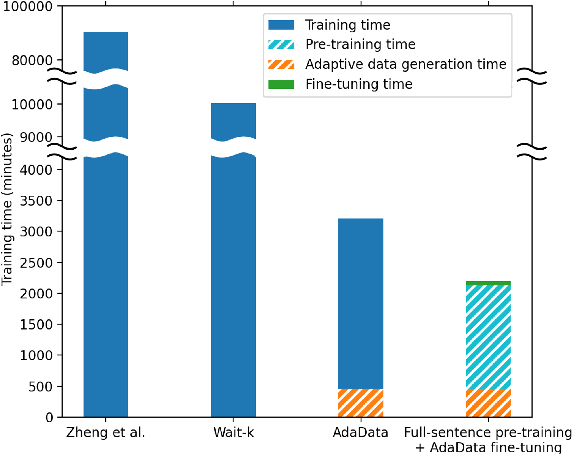
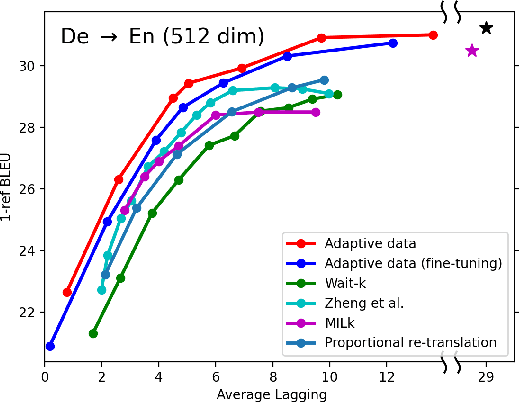
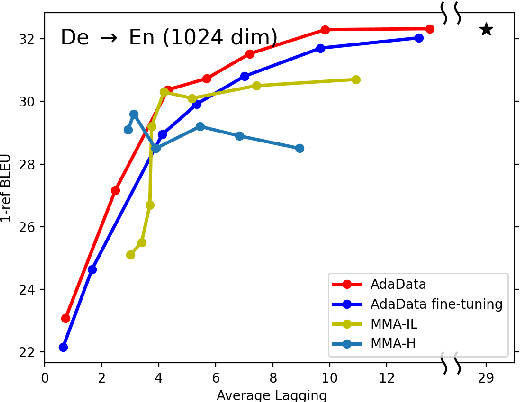
In simultaneous translation (SimulMT), the most widely used strategy is the wait-k policy thanks to its simplicity and effectiveness in balancing translation quality and latency. However, wait-k suffers from two major limitations: (a) it is a fixed policy that can not adaptively adjust latency given context, and (b) its training is much slower than full-sentence translation. To alleviate these issues, we propose a novel and efficient training scheme for adaptive SimulMT by augmenting the training corpus with adaptive prefix-to-prefix pairs, while the training complexity remains the same as that of training full-sentence translation models. Experiments on two language pairs show that our method outperforms all strong baselines in terms of translation quality and latency.
A$^3$T: Alignment-Aware Acoustic and Text Pretraining for Speech Synthesis and Editing
Mar 18, 2022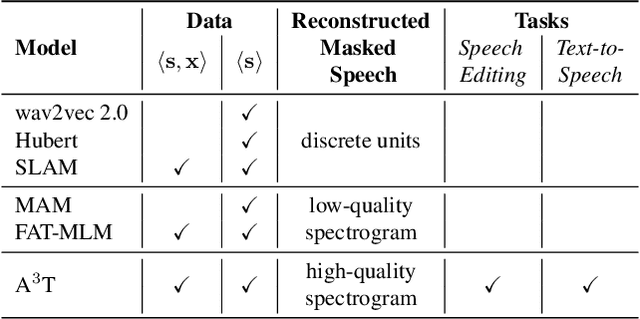
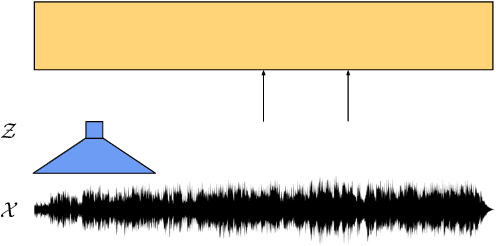

Recently, speech representation learning has improved many speech-related tasks such as speech recognition, speech classification, and speech-to-text translation. However, all the above tasks are in the direction of speech understanding, but for the inverse direction, speech synthesis, the potential of representation learning is yet to be realized, due to the challenging nature of generating high-quality speech. To address this problem, we propose our framework, Alignment-Aware Acoustic-Text Pretraining (A$^3$T), which reconstructs masked acoustic signals with text input and acoustic-text alignment during training. In this way, the pretrained model can generate high quality of reconstructed spectrogram, which can be applied to the speech editing and unseen speaker TTS directly. Experiments show A$^3$T outperforms SOTA models on speech editing, and improves multi-speaker speech synthesis without the external speaker verification model.
TorchDrug: A Powerful and Flexible Machine Learning Platform for Drug Discovery
Feb 16, 2022

Machine learning has huge potential to revolutionize the field of drug discovery and is attracting increasing attention in recent years. However, lacking domain knowledge (e.g., which tasks to work on), standard benchmarks and data preprocessing pipelines are the main obstacles for machine learning researchers to work in this domain. To facilitate the progress of machine learning for drug discovery, we develop TorchDrug, a powerful and flexible machine learning platform for drug discovery built on top of PyTorch. TorchDrug benchmarks a variety of important tasks in drug discovery, including molecular property prediction, pretrained molecular representations, de novo molecular design and optimization, retrosynthsis prediction, and biomedical knowledge graph reasoning. State-of-the-art techniques based on geometric deep learning (or graph machine learning), deep generative models, reinforcement learning and knowledge graph reasoning are implemented for these tasks. TorchDrug features a hierarchical interface that facilitates customization from both novices and experts in this domain. Tutorials, benchmark results and documentation are available at https://torchdrug.ai. Code is released under Apache License 2.0.
Direct Simultaneous Speech-to-Text Translation Assisted by Synchronized Streaming ASR
Jun 11, 2021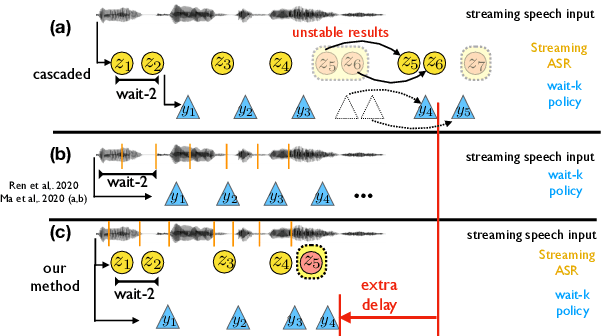
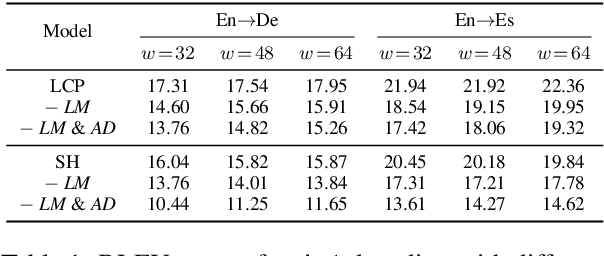
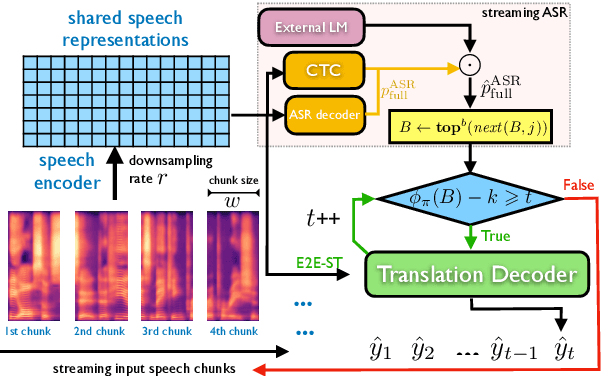
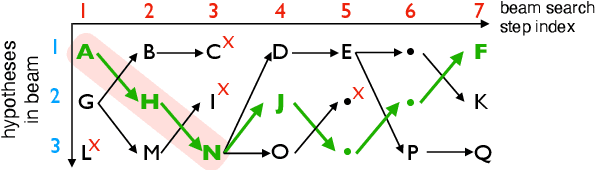
Simultaneous speech-to-text translation is widely useful in many scenarios. The conventional cascaded approach uses a pipeline of streaming ASR followed by simultaneous MT, but suffers from error propagation and extra latency. To alleviate these issues, recent efforts attempt to directly translate the source speech into target text simultaneously, but this is much harder due to the combination of two separate tasks. We instead propose a new paradigm with the advantages of both cascaded and end-to-end approaches. The key idea is to use two separate, but synchronized, decoders on streaming ASR and direct speech-to-text translation (ST), respectively, and the intermediate results of ASR guide the decoding policy of (but is not fed as input to) ST. During training time, we use multitask learning to jointly learn these two tasks with a shared encoder. En-to-De and En-to-Es experiments on the MuSTC dataset demonstrate that our proposed technique achieves substantially better translation quality at similar levels of latency.
Fused Acoustic and Text Encoding for Multimodal Bilingual Pretraining and Speech Translation
Feb 10, 2021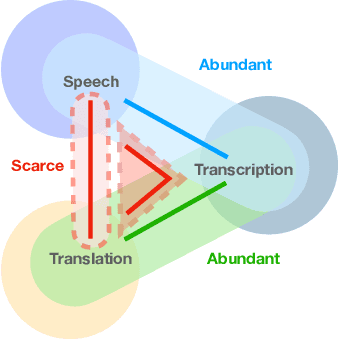
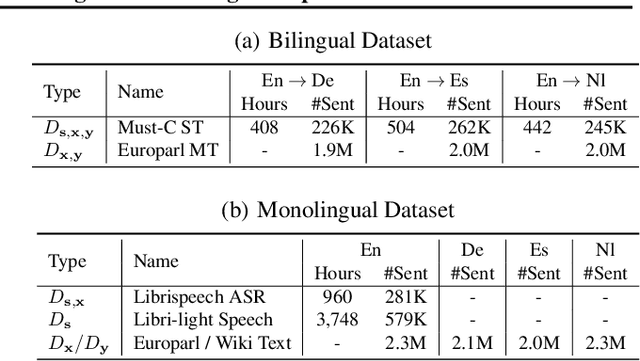
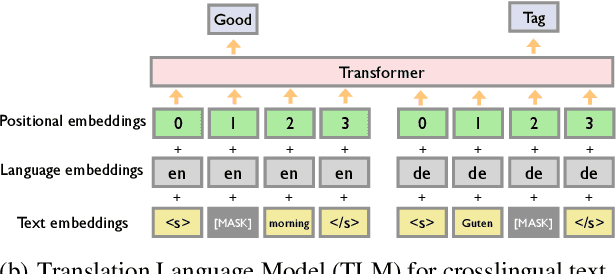
Recently text and speech representation learning has successfully improved many language related tasks. However, all existing methods only learn from one input modality, while a unified acoustic and text representation is desired by many speech-related tasks such as speech translation. We propose a Fused Acoustic and Text Masked Language Model (FAT-MLM) which jointly learns a unified representation for both acoustic and text in-put. Within this cross modal representation learning framework, we further present an end-to-end model for Fused Acoustic and Text Speech Translation (FAT-ST). Experiments on three translation directions show that our proposed speech translation models fine-tuned from FAT-MLM substantially improve translation quality (+5.90 BLEU).
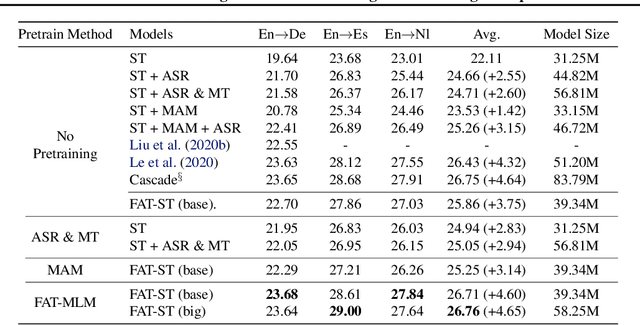
MAM: Masked Acoustic Modeling for End-to-End Speech-to-Text Translation
Oct 22, 2020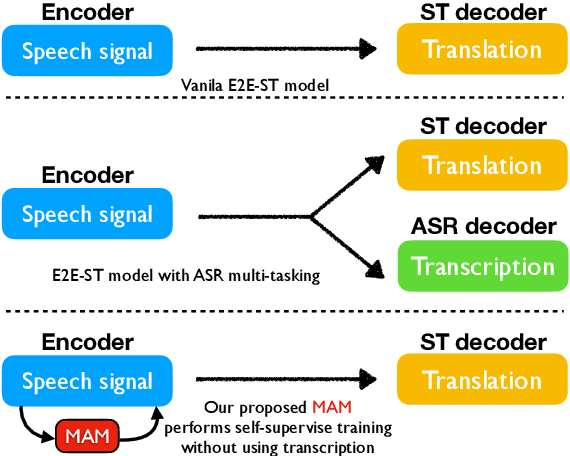
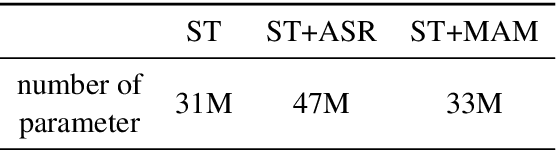

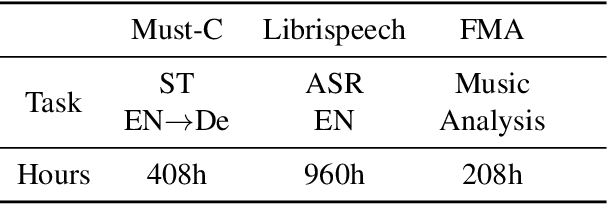
End-to-end Speech-to-text Translation (E2E- ST), which directly translates source language speech to target language text, is widely useful in practice, but traditional cascaded approaches (ASR+MT) often suffer from error propagation in the pipeline. On the other hand, existing end-to-end solutions heavily depend on the source language transcriptions for pre-training or multi-task training with Automatic Speech Recognition (ASR). We instead propose a simple technique to learn a robust speech encoder in a self-supervised fashion only on the speech side, which can utilize speech data without transcription. This technique, termed Masked Acoustic Modeling (MAM), can also perform pre-training, for the first time, on any acoustic signals (including non-speech ones) without annotation. Compared with current state-of-the-art models on ST, our technique achieves +1.4 BLEU improvement without using transcriptions, and +1.2 BLEU using transcriptions. The pre-training of MAM with arbitrary acoustic signals also boosts the downstream speech-related tasks.