 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter wit than wealth: Dynamic Parametric Retrieval Augmented Generation for Test-time Knowledge Enhancement
Mar 31, 2025Retrieval-augmented generation (RAG) enhances large language models (LLMs) by retrieving relevant documents from external sources and incorporating them into the context. While it improves reliability by providing factual texts, it significantly increases inference costs as context length grows and introduces challenging issue of RAG hallucination, primarily caused by the lack of corresponding parametric knowledge in LLMs. An efficient solution is to enhance the knowledge of LLMs at test-time. Parametric RAG (PRAG) addresses this by embedding document into LLMs parameters to perform test-time knowledge enhancement, effectively reducing inference costs through offline training. However, its high training and storage costs, along with limited generalization ability, significantly restrict its practical adoption. To address these challenges, we propose Dynamic Parametric RAG (DyPRAG), a novel framework that leverages a lightweight parameter translator model to efficiently convert documents into parametric knowledge. DyPRAG not only reduces inference, training, and storage costs but also dynamically generates parametric knowledge, seamlessly enhancing the knowledge of LLMs and resolving knowledge conflicts in a plug-and-play manner at test-time. Extensive experiments on multiple datasets demonstrate the effectiveness and generalization capabilities of DyPRAG, offering a powerful and practical RAG paradigm which enables superior knowledge fusion and mitigates RAG hallucination in real-world applications. Our code is available at https://github.com/Trae1ounG/DyPRAG.
Probabilistic Uncertain Reward Model: A Natural Generalization of Bradley-Terry Reward Model
Mar 28, 2025



Reinforcement Learning from Human Feedback (RLHF) has emerged as a critical technique for training large language models. However, reward hacking-a phenomenon where models exploit flaws in the reward model-remains a significant barrier to achieving robust and scalable intelligence through long-term training. Existing studies have proposed uncertain reward model to address reward hacking, however, they often lack systematic or theoretical foundations, failing to model the uncertainty intrinsically emerging from preference data. In this paper, we propose the Probabilistic Uncertain Reward Model (PURM), a natural generalization of the classical Bradley-Terry reward model. PURM learns reward distributions directly from preference data and quantifies per-sample uncertainty via the average overlap area between reward distributions. To mitigate reward hacking, we further introduce an uncertainty-aware penalty into Proximal Policy Optimization (PPO), which leverages the learned uncertainty to dynamically balance reward optimization and exploration. We propose a lightweight and easy-to-use implementation of PURM. Experiments demonstrate that PURM significantly delays the onset of reward hacking while improving final reward performance, outperforming baseline methods in both stability and effectiveness.
Rewarding Curse: Analyze and Mitigate Reward Modeling Issues for LLM Reasoning
Mar 07, 2025Chain-of-thought (CoT) prompting demonstrates varying performance under different reasoning tasks. Previous work attempts to evaluate it but falls short in providing an in-depth analysis of patterns that influence the CoT. In this paper, we study the CoT performance from the perspective of effectiveness and faithfulness. For the former, we identify key factors that influence CoT effectiveness on performance improvement, including problem difficulty, information gain, and information flow. For the latter, we interpret the unfaithful CoT issue by conducting a joint analysis of the information interaction among the question, CoT, and answer. The result demonstrates that, when the LLM predicts answers, it can recall correct information missing in the CoT from the question, leading to the problem. Finally, we propose a novel algorithm to mitigate this issue, in which we recall extra information from the question to enhance the CoT generation and evaluate CoTs based on their information gain. Extensive experiments demonstrate that our approach enhances both the faithfulness and effectiveness of CoT.
Capability Localization: Capabilities Can be Localized rather than Individual Knowledge
Feb 28, 2025



Large scale language models have achieved superior performance in tasks related to natural language processing, however, it is still unclear how model parameters affect performance improvement. Previous studies assumed that individual knowledge is stored in local parameters, and the storage form of individual knowledge is dispersed parameters, parameter layers, or parameter chains, which are not unified. We found through fidelity and reliability evaluation experiments that individual knowledge cannot be localized. Afterwards, we constructed a dataset for decoupling experiments and discovered the potential for localizing data commonalities. To further reveal this phenomenon, this paper proposes a Commonality Neuron Localization (CNL) method, which successfully locates commonality neurons and achieves a neuron overlap rate of 96.42% on the GSM8K dataset. Finally, we have demonstrated through cross data experiments that commonality neurons are a collection of capability neurons that possess the capability to enhance performance. Our code is available at https://github.com/nlpkeg/Capability-Neuron-Localization.
GATE: Graph-based Adaptive Tool Evolution Across Diverse Tasks
Feb 20, 2025



Large Language Models (LLMs) have shown great promise in tool-making, yet existing frameworks often struggle to efficiently construct reliable toolsets and are limited to single-task settings. To address these challenges, we propose GATE (Graph-based Adaptive Tool Evolution), an adaptive framework that dynamically constructs and evolves a hierarchical graph of reusable tools across multiple scenarios. We evaluate GATE on open-ended tasks (Minecraft), agent-based tasks (TextCraft, DABench), and code generation tasks (MATH, Date, TabMWP). Our results show that GATE achieves up to 4.3x faster milestone completion in Minecraft compared to the previous SOTA, and provides an average improvement of 9.23% over existing tool-making methods in code generation tasks and 10.03% in agent tasks. GATE demonstrates the power of adaptive evolution, balancing tool quantity, complexity, and functionality while maintaining high efficiency. Code and data are available at \url{https://github.com/ayanami2003/GATE}.
The Knowledge Microscope: Features as Better Analytical Lenses than Neurons
Feb 18, 2025Previous studies primarily utilize MLP neurons as units of analysis for understanding the mechanisms of factual knowledge in Language Models (LMs); however, neurons suffer from polysemanticity, leading to limited knowledge expression and poor interpretability. In this paper, we first conduct preliminary experiments to validate that Sparse Autoencoders (SAE) can effectively decompose neurons into features, which serve as alternative analytical units. With this established, our core findings reveal three key advantages of features over neurons: (1) Features exhibit stronger influence on knowledge expression and superior interpretability. (2) Features demonstrate enhanced monosemanticity, showing distinct activation patterns between related and unrelated facts. (3) Features achieve better privacy protection than neurons, demonstrated through our proposed FeatureEdit method, which significantly outperforms existing neuron-based approaches in erasing privacy-sensitive information from LMs.Code and dataset will be available.
DATA: Decomposed Attention-based Task Adaptation for Rehearsal-Free Continual Learning
Feb 17, 2025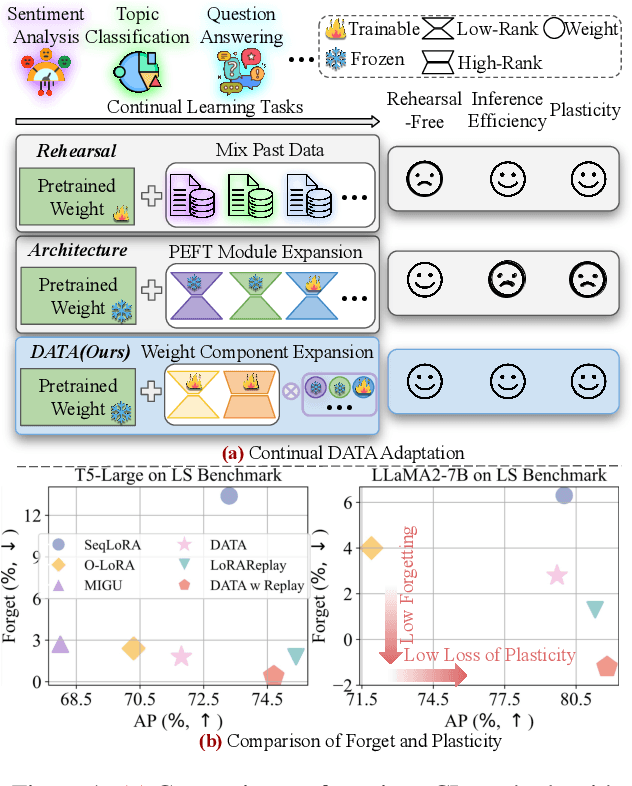
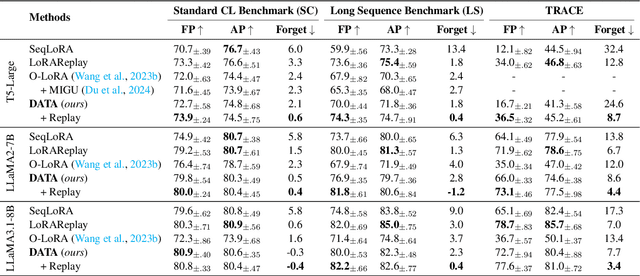
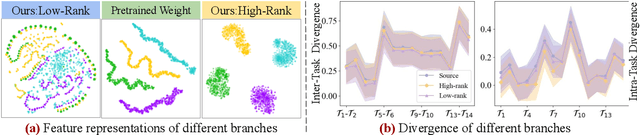
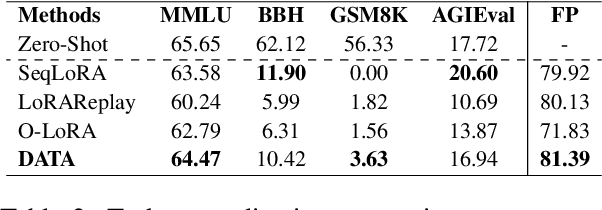
Continual learning (CL) is essential for Large Language Models (LLMs) to adapt to evolving real-world demands, yet they are susceptible to catastrophic forgetting (CF). While traditional CF solutions rely on expensive data rehearsal, recent rehearsal-free methods employ model-based and regularization-based strategies to address this issue. However, these approaches often neglect the model's plasticity, which is crucial to achieving optimal performance on newly learned tasks. Consequently, a key challenge in CL is striking a balance between preserving plasticity and mitigating CF. To tackle this challenge, we propose the $\textbf{D}$ecomposed $\textbf{A}$ttention-based $\textbf{T}$ask $\textbf{A}$daptation (DATA), which explicitly decouples and learns both task-specific and task-shared knowledge using high-rank and low-rank task adapters (e.g., LoRAs). For new tasks, DATA dynamically adjusts the weights of adapters of different ranks based on their relevance and distinction from previous tasks, allowing the model to acquire new task-specific skills while effectively retaining previously learned knowledge. Specifically, we implement a decomposed component weighting strategy comprising learnable components that collectively generate attention-based weights, allowing the model to integrate and utilize diverse knowledge from each DATA. Extensive experiments on three widely used benchmarks demonstrate that our proposed method achieves state-of-the-art performance. Notably, our approach significantly enhances model plasticity and mitigates CF by extending learnable components and employing stochastic restoration during training iterations.
Does RAG Really Perform Bad For Long-Context Processing?
Feb 17, 2025



The efficient processing of long context poses a serious challenge for large language models (LLMs). Recently, retrieval-augmented generation (RAG) has emerged as a promising strategy for this problem, as it enables LLMs to make selective use of the long context for efficient computation. However, existing RAG approaches lag behind other long-context processing methods due to inherent limitations on inaccurate retrieval and fragmented contexts. To address these challenges, we introduce RetroLM, a novel RAG framework for long-context processing. Unlike traditional methods, RetroLM employs KV-level retrieval augmentation, where it partitions the LLM's KV cache into contiguous pages and retrieves the most crucial ones for efficient computation. This approach enhances robustness to retrieval inaccuracy, facilitates effective utilization of fragmented contexts, and saves the cost from repeated computation. Building on this framework, we further develop a specialized retriever for precise retrieval of critical pages and conduct unsupervised post-training to optimize the model's ability to leverage retrieved information. We conduct comprehensive evaluations with a variety of benchmarks, including LongBench, InfiniteBench, and RULER, where RetroLM significantly outperforms existing long-context LLMs and efficient long-context processing methods, particularly in tasks requiring intensive reasoning or extremely long-context comprehension.
SAMRefiner: Taming Segment Anything Model for Universal Mask Refinement
Feb 10, 2025



In this paper, we explore a principal way to enhance the quality of widely pre-existing coarse masks, enabling them to serve as reliable training data for segmentation models to reduce the annotation cost. In contrast to prior refinement techniques that are tailored to specific models or tasks in a close-world manner, we propose SAMRefiner, a universal and efficient approach by adapting SAM to the mask refinement task. The core technique of our model is the noise-tolerant prompting scheme. Specifically, we introduce a multi-prompt excavation strategy to mine diverse input prompts for SAM (i.e., distance-guided points, context-aware elastic bounding boxes, and Gaussian-style masks) from initial coarse masks. These prompts can collaborate with each other to mitigate the effect of defects in coarse masks. In particular, considering the difficulty of SAM to handle the multi-object case in semantic segmentation, we introduce a split-then-merge (STM) pipeline. Additionally, we extend our method to SAMRefiner++ by introducing an additional IoU adaption step to further boost the performance of the generic SAMRefiner on the target dataset. This step is self-boosted and requires no additional annotation. The proposed framework is versatile and can flexibly cooperate with existing segmentation methods. We evaluate our mask framework on a wide range of benchmarks under different settings, demonstrating better accuracy and efficiency. SAMRefiner holds significant potential to expedite the evolution of refinement tools. Our code is available at https://github.com/linyq2117/SAMRefiner.
VaiBot: Shuttle Between the Instructions and Parameters
Feb 04, 2025How to interact with LLMs through \emph{instructions} has been widely studied by researchers. However, previous studies have treated the emergence of instructions and the training of LLMs on task data as separate processes, overlooking the inherent unity between the two. This paper proposes a neural network framework, VaiBot, that integrates VAE and VIB, designed to uniformly model, learn, and infer both deduction and induction tasks under LLMs. Through experiments, we demonstrate that VaiBot performs on par with existing baseline methods in terms of deductive capabilities while significantly surpassing them in inductive capabilities. We also find that VaiBot can scale up using general instruction-following data and exhibits excellent one-shot induction abilities. We finally synergistically integrate the deductive and inductive processes of VaiBot. Through T-SNE dimensionality reduction, we observe that its inductive-deductive process significantly improves the distribution of training parameters, enabling it to outperform baseline methods in inductive reasoning tasks. The code and data for this paper can be found at https://anonymous.4open.science/r/VaiBot-021F.