 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Multi-Step Tool-Use Reinforcement Learning Collapses and How Supervisory Signals Fix It
Jun 24, 2026Tool use enables large language models (LLMs) to perform complex tasks, and recent agentic reinforcement learning (RL) methods show promise for enhancing model capabilities. However, RL alone often leads to instability or limited gains in tool-use tasks. In our experiments, some models exhibit catastrophic collapse, where performance abruptly drops and tool-invocation structures fail. The analysis reveals that these failures stem from unexpected probability spikes in specific control tokens, disrupting structured execution, yet the underlying tool-use capability remains intact, merely obscured by specific formats. To address this, we systematically investigate a diverse set of supervisory signals, including off-policy supervision, hint-based guidance, erroneous example supervision, and others, applied under both synchronous and interleaved training schemes. We find that interleaving supervised fine-tuning (SFT) with RL substantially improves stability, but exhibits degraded performance under format and content out-of-distribution (OOD) evaluation. We also analyze the impact of learning rates and generalization across settings. These results highlight the importance of understanding RL failures and demonstrate how diverse supervisory signals can guide exploratory learning, enabling robust training of LLMs for complex, multi-step tool-use tasks. Our Code is available at https://github.com/hypasd-art/Tool-RL-Box.
Look Light, Think Heavy: What Multimodal Chain-of-Thought Reasoning Can and Cannot Do
Jun 21, 2026Chain-of-Thought (CoT) has become a standard method for improving reasoning capabilities in large language models (LLMs) by eliciting step-by-step thinking, but its effectiveness in multimodal tasks remains unclear. In this paper, we aim to systematically investigate the key question: What can multimodal Chain-of-Thought reasoning do, and where and why does it fall short? To this end, we evaluate 12 multimodal tasks across perception and reasoning categories using both 14 non-reasoning models and 8 reasoning models. Our analysis reveals several important findings: (1) CoT is not a free lunch and should be used selectively depending on the specific requirements of each task. For perception tasks, CoT can lead to undesirable side effects, such as reduced performance in visual grounding and object counting. In contrast, it proves effective for reasoning tasks involving mathematical, scientific, and multi-image reasoning; (2) Compared to original models, existing open-source multimodal reasoning models often yield only marginal overall improvements, possibly due to an overemphasis on mathematical reasoning at the expense of broader capabilities; (3) Visual reasoning remains a key bottleneck for current multimodal CoT, as models exhibit a Look Light, Think Heavy pattern where verbal reflection rises and falls during reasoning, whereas visual reflection consistently diminishes. These findings suggest that while multimodal CoT handles verbal reflection relatively well, it lacks the ability to maintain deep visual introspection throughout the reasoning process.
Agentic Environment Engineering for Large Language Models: A Survey of Environment Modeling, Synthesis, Evaluation, and Application
Jun 10, 2026Environments serve as interactive systems for large language model (LLM) based agents across diverse scenarios and play a crucial role in driving the continual evolution of model capabilities. Despite this importance, existing work lacks a systematic categorization and deep analysis. This paper systematically studies current researches on agentic environments from the perspective of the environment engineering lifecycle, covering their modeling, synthesis, evaluation and application. Specifically, the paper first introduces representative environments from the perspectives of eight attributes and eight domains, providing detailed analyses of their development paths and highlighting their core capabilities. Second, for automated environment synthesis, two paradigms are introduced, such as symbolic synthesis and neural synthesis. This paper also shows different environment evaluation methods in each paradigm. Thirdly, the corresponding environment applications from the perspective of agent-environment co-evolution are discussed. In specific, the paper characterizes the primary pathways for agent evolution in dynamic environments from four complementary perspectives: memory-centric experience evolution, orchestration-centric workflow evolution, trajectory-centric offline evolution, and exploration-centric online evolution. And three paradigms of environment evolution are identified, namely neural-driven, difficulty-driven, and scaling-driven approaches. At last, several promising future directions are discussed, including Environment-as-a-Service, Multi-agent Environments, and Neural-Symbolic Environments.
Pushing the Limits of LLM Tool Calling via Experiential Knowledge Integration and Activation
Jun 09, 2026Large language models (LLMs) rely on tool use to act as autonomous agents, yet often fail in multi-step execution due to insufficient tool-related knowledge and ineffective knowledge activation. Therefore, we present a systematic study on how knowledge influences tool-use performance, covering the stages of knowledge acquisition, activation, and internalization. In the knowledge acquisition stage, we acquire and evaluate various forms of experiential knowledge, and our analysis shows that simple instance-level knowledge can already provide strong and reliable gains, while abstract intent-level knowledge offers limited benefits. At inference time, to activate knowledge, we find that prompting LLM to expand the depth of reasoning yields diminishing returns, whereas expanding the width of reasoning by parallel sampling with aggregation more effectively activates latent experiential knowledge. At training time, for knowledge internalization, post-training with knowledge-augmented data further improves performance, with reinforcement learning outperforming supervised fine-tuning. Based on these insights, we propose the Knowledge-Augmented Tool Execution (KATE), a knowledge-augmented tool execution framework that integrates experiential knowledge with reasoning-width-expanded inference and knowledge-aware training. Experiments on BFCL-V3 and AppWorld demonstrate consistent and substantial improvements over strong baselines across model scales. Our Code is available at https://github.com/hypasd-art/KATE.
ResAdapt: Adaptive Resolution for Efficient Multimodal Reasoning
Mar 31, 2026Multimodal Large Language Models (MLLMs) achieve stronger visual understanding by scaling input fidelity, yet the resulting visual token growth makes jointly sustaining high spatial resolution and long temporal context prohibitive. We argue that the bottleneck lies not in how post-encoding representations are compressed but in the volume of pixels the encoder receives, and address it with ResAdapt, an Input-side adaptation framework that learns how much visual budget each frame should receive before encoding. ResAdapt couples a lightweight Allocator with an unchanged MLLM backbone, so the backbone retains its native visual-token interface while receiving an operator-transformed input. We formulate allocation as a contextual bandit and train the Allocator with Cost-Aware Policy Optimization (CAPO), which converts sparse rollout feedback into a stable accuracy-cost learning signal. Across budget-controlled video QA, temporal grounding, and image reasoning tasks, ResAdapt improves low-budget operating points and often lies on or near the efficiency-accuracy frontier, with the clearest gains on reasoning-intensive benchmarks under aggressive compression. Notably, ResAdapt supports up to 16x more frames at the same visual budget while delivering over 15% performance gain. Code is available at https://github.com/Xnhyacinth/ResAdapt.
Think While Watching: Online Streaming Segment-Level Memory for Multi-Turn Video Reasoning in Multimodal Large Language Models
Mar 12, 2026Multimodal large language models (MLLMs) have shown strong performance on offline video understanding, but most are limited to offline inference or have weak online reasoning, making multi-turn interaction over continuously arriving video streams difficult. Existing streaming methods typically use an interleaved perception-generation paradigm, which prevents concurrent perception and generation and leads to early memory decay as streams grow, hurting long-range dependency modeling. We propose Think While Watching, a memory-anchored streaming video reasoning framework that preserves continuous segment-level memory during multi-turn interaction. We build a three-stage, multi-round chain-of-thought dataset and adopt a stage-matched training strategy, while enforcing strict causality through a segment-level streaming causal mask and streaming positional encoding. During inference, we introduce an efficient pipeline that overlaps watching and thinking and adaptively selects the best attention backend. Under both single-round and multi-round streaming input protocols, our method achieves strong results. Built on Qwen3-VL, it improves single-round accuracy by 2.6% on StreamingBench and by 3.79% on OVO-Bench. In the multi-round setting, it maintains performance while reducing output tokens by 56%. Code is available at: https://github.com/wl666hhh/Think_While_Watching/
DATA: Decomposed Attention-based Task Adaptation for Rehearsal-Free Continual Learning
Feb 17, 2025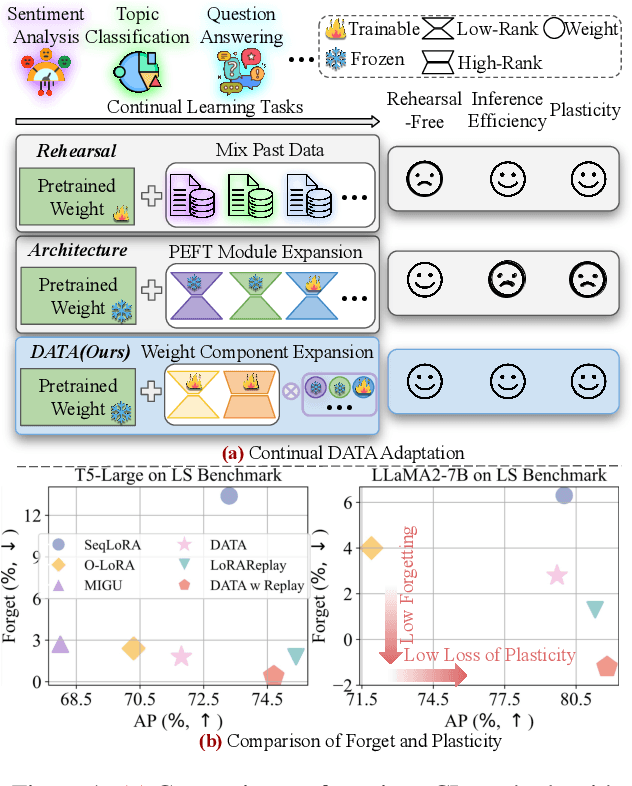
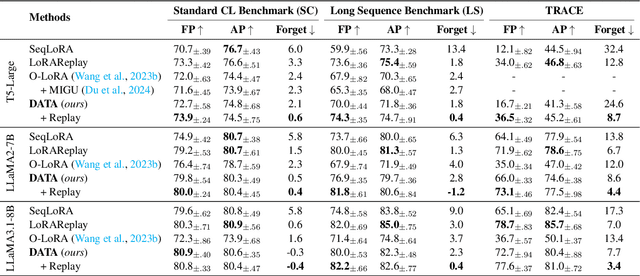
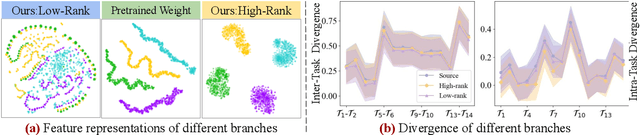
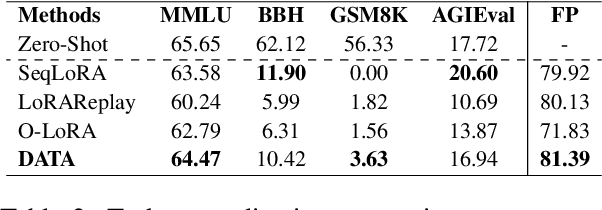
Continual learning (CL) is essential for Large Language Models (LLMs) to adapt to evolving real-world demands, yet they are susceptible to catastrophic forgetting (CF). While traditional CF solutions rely on expensive data rehearsal, recent rehearsal-free methods employ model-based and regularization-based strategies to address this issue. However, these approaches often neglect the model's plasticity, which is crucial to achieving optimal performance on newly learned tasks. Consequently, a key challenge in CL is striking a balance between preserving plasticity and mitigating CF. To tackle this challenge, we propose the $\textbf{D}$ecomposed $\textbf{A}$ttention-based $\textbf{T}$ask $\textbf{A}$daptation (DATA), which explicitly decouples and learns both task-specific and task-shared knowledge using high-rank and low-rank task adapters (e.g., LoRAs). For new tasks, DATA dynamically adjusts the weights of adapters of different ranks based on their relevance and distinction from previous tasks, allowing the model to acquire new task-specific skills while effectively retaining previously learned knowledge. Specifically, we implement a decomposed component weighting strategy comprising learnable components that collectively generate attention-based weights, allowing the model to integrate and utilize diverse knowledge from each DATA. Extensive experiments on three widely used benchmarks demonstrate that our proposed method achieves state-of-the-art performance. Notably, our approach significantly enhances model plasticity and mitigates CF by extending learnable components and employing stochastic restoration during training iterations.