 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient and Student-Friendly Knowledge Distillation
May 28, 2022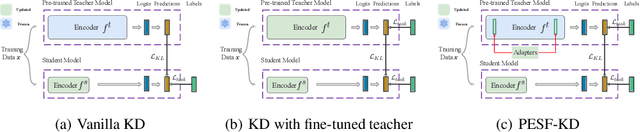
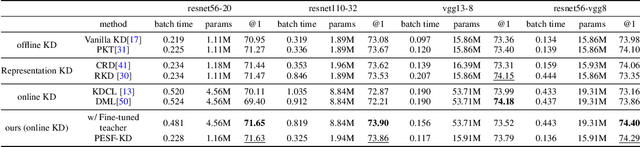
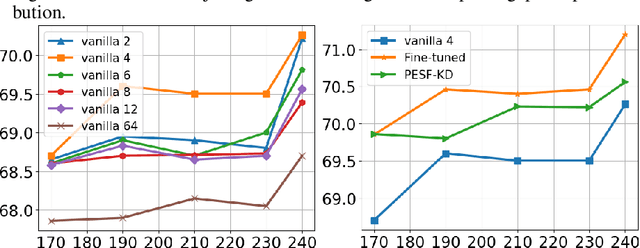
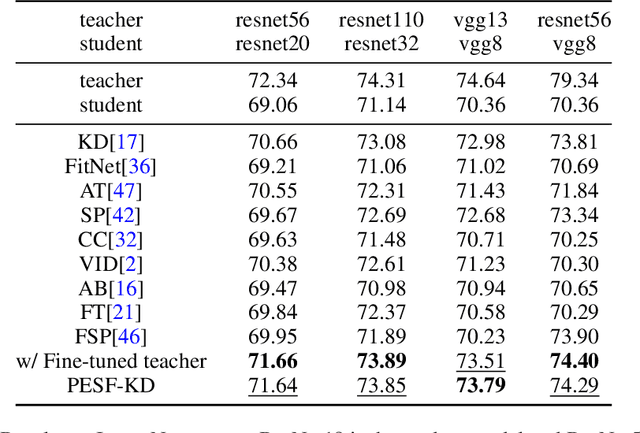
Knowledge distillation (KD) has been extensively employed to transfer the knowledge from a large teacher model to the smaller students, where the parameters of the teacher are fixed (or partially) during training. Recent studies show that this mode may cause difficulties in knowledge transfer due to the mismatched model capacities. To alleviate the mismatch problem, teacher-student joint training methods, e.g., online distillation, have been proposed, but it always requires expensive computational cost. In this paper, we present a parameter-efficient and student-friendly knowledge distillation method, namely PESF-KD, to achieve efficient and sufficient knowledge transfer by updating relatively few partial parameters. Technically, we first mathematically formulate the mismatch as the sharpness gap between their predictive distributions, where we show such a gap can be narrowed with the appropriate smoothness of the soft label. Then, we introduce an adapter module for the teacher and only update the adapter to obtain soft labels with appropriate smoothness. Experiments on a variety of benchmarks show that PESF-KD can significantly reduce the training cost while obtaining competitive results compared to advanced online distillation methods. Code will be released upon acceptance.