 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting the Transferability of Adversarial Attacks with Reverse Adversarial Perturbation
Oct 12, 2022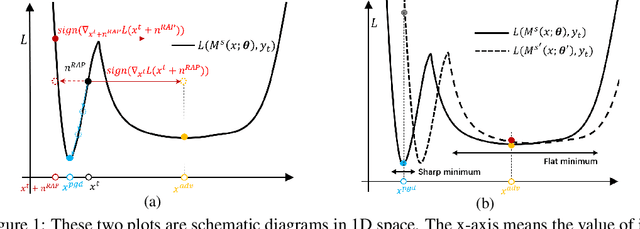
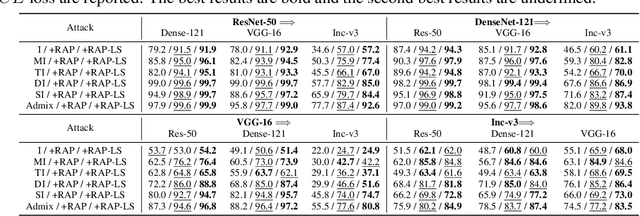
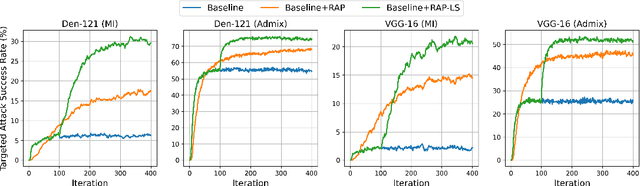
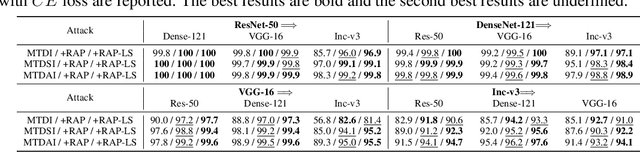
Deep neural networks (DNNs) have been shown to be vulnerable to adversarial examples, which can produce erroneous predictions by injecting imperceptible perturbations. In this work, we study the transferability of adversarial examples, which is significant due to its threat to real-world applications where model architecture or parameters are usually unknown. Many existing works reveal that the adversarial examples are likely to overfit the surrogate model that they are generated from, limiting its transfer attack performance against different target models. To mitigate the overfitting of the surrogate model, we propose a novel attack method, dubbed reverse adversarial perturbation (RAP). Specifically, instead of minimizing the loss of a single adversarial point, we advocate seeking adversarial example located at a region with unified low loss value, by injecting the worst-case perturbation (the reverse adversarial perturbation) for each step of the optimization procedure. The adversarial attack with RAP is formulated as a min-max bi-level optimization problem. By integrating RAP into the iterative process for attacks, our method can find more stable adversarial examples which are less sensitive to the changes of decision boundary, mitigating the overfitting of the surrogate model. Comprehensive experimental comparisons demonstrate that RAP can significantly boost adversarial transferability. Furthermore, RAP can be naturally combined with many existing black-box attack techniques, to further boost the transferability. When attacking a real-world image recognition system, Google Cloud Vision API, we obtain 22% performance improvement of targeted attacks over the compared method. Our codes are available at https://github.com/SCLBD/Transfer_attack_RAP.
Stability Analysis and Generalization Bounds of Adversarial Training
Oct 03, 2022
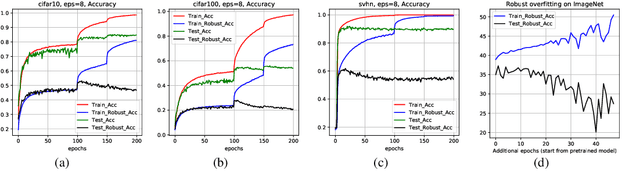
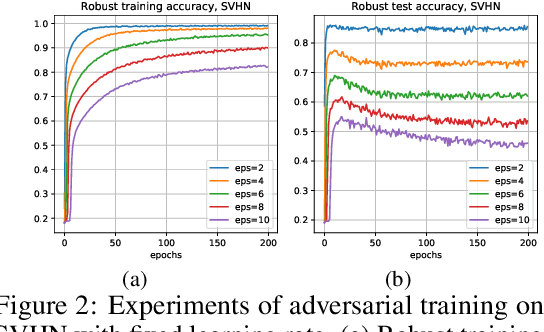
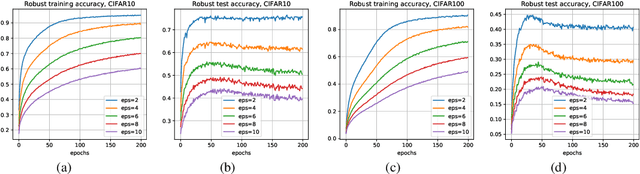
In adversarial machine learning, deep neural networks can fit the adversarial examples on the training dataset but have poor generalization ability on the test set. This phenomenon is called robust overfitting, and it can be observed when adversarially training neural nets on common datasets, including SVHN, CIFAR-10, CIFAR-100, and ImageNet. In this paper, we study the robust overfitting issue of adversarial training by using tools from uniform stability. One major challenge is that the outer function (as a maximization of the inner function) is nonsmooth, so the standard technique (e.g., hardt et al., 2016) cannot be applied. Our approach is to consider $\eta$-approximate smoothness: we show that the outer function satisfies this modified smoothness assumption with $\eta$ being a constant related to the adversarial perturbation. Based on this, we derive stability-based generalization bounds for stochastic gradient descent (SGD) on the general class of $\eta$-approximate smooth functions, which covers the adversarial loss. Our results provide a different understanding of robust overfitting from the perspective of uniform stability. Additionally, we show that a few popular techniques for adversarial training (\emph{e.g.,} early stopping, cyclic learning rate, and stochastic weight averaging) are stability-promoting in theory.
Adaptive Smoothness-weighted Adversarial Training for Multiple Perturbations with Its Stability Analysis
Oct 02, 2022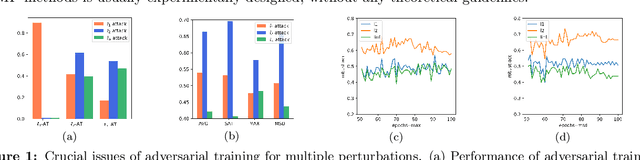
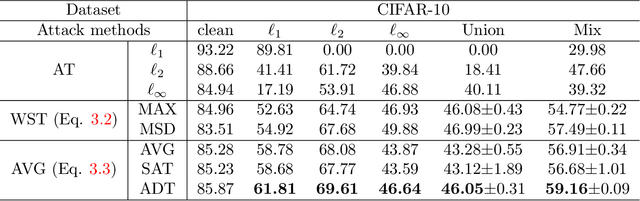
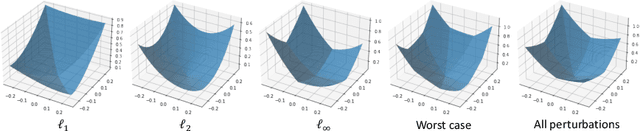
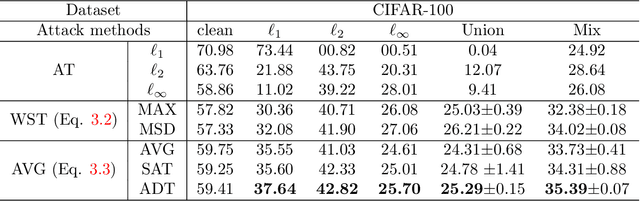
Adversarial Training (AT) has been demonstrated as one of the most effective methods against adversarial examples. While most existing works focus on AT with a single type of perturbation e.g., the $\ell_\infty$ attacks), DNNs are facing threats from different types of adversarial examples. Therefore, adversarial training for multiple perturbations (ATMP) is proposed to generalize the adversarial robustness over different perturbation types (in $\ell_1$, $\ell_2$, and $\ell_\infty$ norm-bounded perturbations). However, the resulting model exhibits trade-off between different attacks. Meanwhile, there is no theoretical analysis of ATMP, limiting its further development. In this paper, we first provide the smoothness analysis of ATMP and show that $\ell_1$, $\ell_2$, and $\ell_\infty$ adversaries give different contributions to the smoothness of the loss function of ATMP. Based on this, we develop the stability-based excess risk bounds and propose adaptive smoothness-weighted adversarial training for multiple perturbations. Theoretically, our algorithm yields better bounds. Empirically, our experiments on CIFAR10 and CIFAR100 achieve the state-of-the-art performance against the mixture of multiple perturbations attacks.
Understanding Adversarial Robustness Against On-manifold Adversarial Examples
Oct 02, 2022
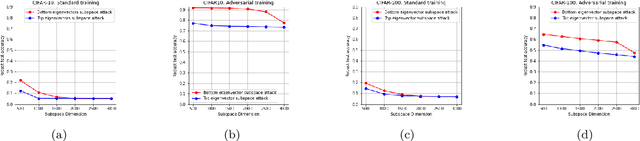
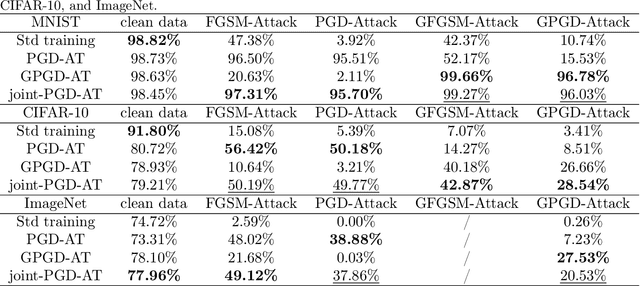
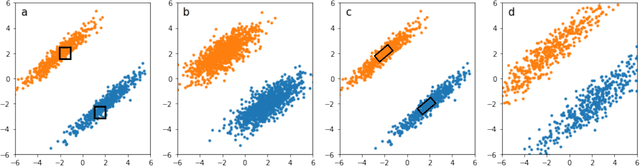
Deep neural networks (DNNs) are shown to be vulnerable to adversarial examples. A well-trained model can be easily attacked by adding small perturbations to the original data. One of the hypotheses of the existence of the adversarial examples is the off-manifold assumption: adversarial examples lie off the data manifold. However, recent research showed that on-manifold adversarial examples also exist. In this paper, we revisit the off-manifold assumption and want to study a question: at what level is the poor performance of neural networks against adversarial attacks due to on-manifold adversarial examples? Since the true data manifold is unknown in practice, we consider two approximated on-manifold adversarial examples on both real and synthesis datasets. On real datasets, we show that on-manifold adversarial examples have greater attack rates than off-manifold adversarial examples on both standard-trained and adversarially-trained models. On synthetic datasets, theoretically, We prove that on-manifold adversarial examples are powerful, yet adversarial training focuses on off-manifold directions and ignores the on-manifold adversarial examples. Furthermore, we provide analysis to show that the properties derived theoretically can also be observed in practice. Our analysis suggests that on-manifold adversarial examples are important, and we should pay more attention to on-manifold adversarial examples for training robust models.
Control-Oriented Power Allocation for Integrated Satellite-UAV Networks
Aug 31, 2022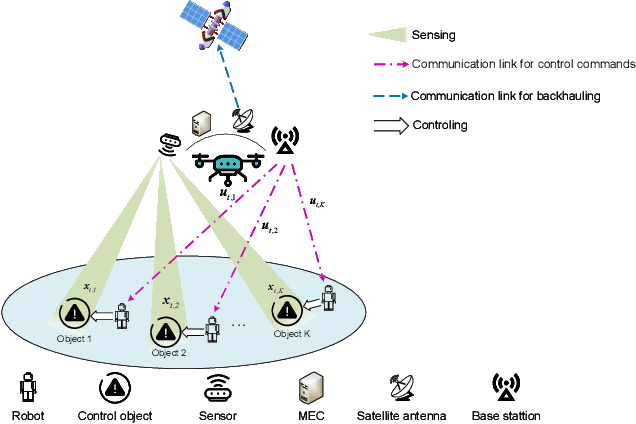
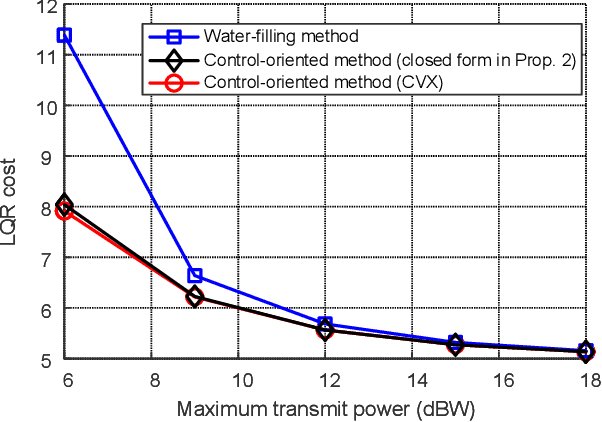
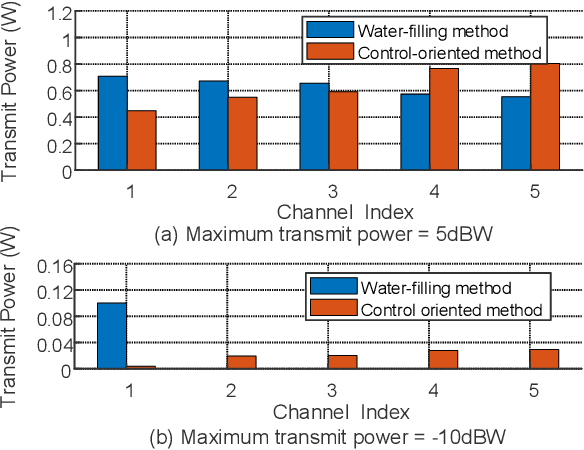
This letter presents a sensing-communication-computing-control (SC3) integrated satellite unmanned aerial vehicle (UAV) network, where the UAV is equipped with on-board sensors, mobile edge computing (MEC) servers, base stations and satellite communication module. Like the nervous system, this integrated network is capable of organizing multiple field robots in remote areas, so as to perform mission-critical tasks which are dangerous for human. Aiming at activating this nervous system with multiple SC3 loops, we present a control-oriented optimization problem. Different from traditional studies which mainly focused on communication metrics, we address the power allocation issue to minimize the sum linear quadratic regulator (LQR) control cost of all SC3 loops. Specifically, we show the convexity of the formulated problem and reveal the relationship between optimal transmit power and intrinsic entropy rate of different SC3 loops. For the assure-to-be-stable case, we derive a closed-form solution for ease of practical applications. After demonstrating the superiority of the control-oriented power allocation, we further highlight its difference with classic capacity-oriented water-filling method.
Towards Real-World Video Deblurring by Exploring Blur Formation Process
Aug 28, 2022

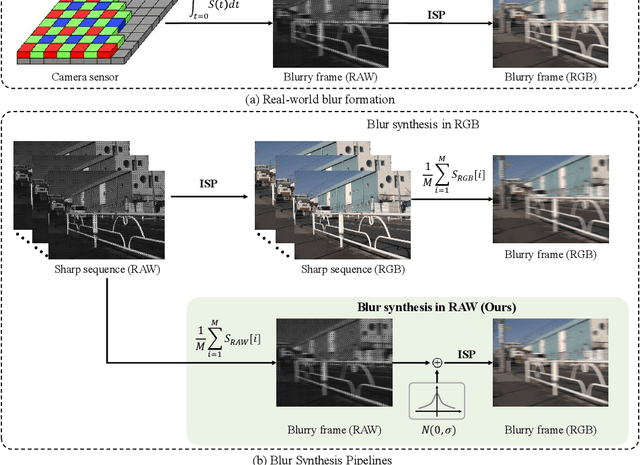
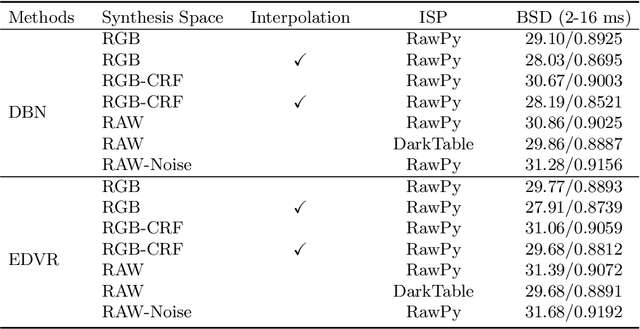
This paper aims at exploring how to synthesize close-to-real blurs that existing video deblurring models trained on them can generalize well to real-world blurry videos. In recent years, deep learning-based approaches have achieved promising success on video deblurring task. However, the models trained on existing synthetic datasets still suffer from generalization problems over real-world blurry scenarios with undesired artifacts. The factors accounting for the failure remain unknown. Therefore, we revisit the classical blur synthesis pipeline and figure out the possible reasons, including shooting parameters, blur formation space, and image signal processor~(ISP). To analyze the effects of these potential factors, we first collect an ultra-high frame-rate (940 FPS) RAW video dataset as the data basis to synthesize various kinds of blurs. Then we propose a novel realistic blur synthesis pipeline termed as RAW-Blur by leveraging blur formation cues. Through numerous experiments, we demonstrate that synthesizing blurs in the RAW space and adopting the same ISP as the real-world testing data can effectively eliminate the negative effects of synthetic data. Furthermore, the shooting parameters of the synthesized blurry video, e.g., exposure time and frame-rate play significant roles in improving the performance of deblurring models. Impressively, the models trained on the blurry data synthesized by the proposed RAW-Blur pipeline can obtain more than 5dB PSNR gain against those trained on the existing synthetic blur datasets. We believe the novel realistic synthesis pipeline and the corresponding RAW video dataset can help the community to easily construct customized blur datasets to improve real-world video deblurring performance largely, instead of laboriously collecting real data pairs.
HyP$^2$ Loss: Beyond Hypersphere Metric Space for Multi-label Image Retrieval
Aug 14, 2022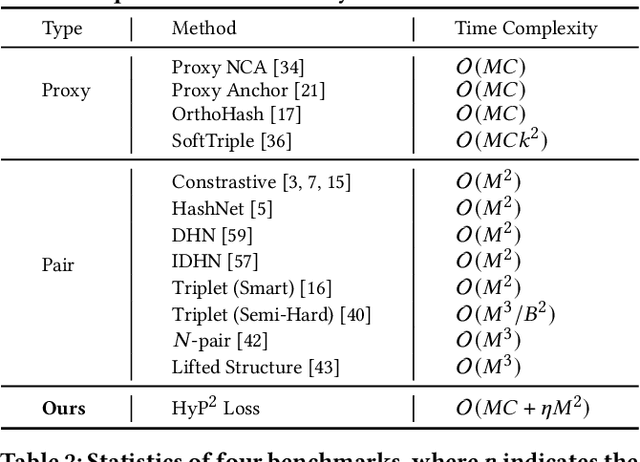
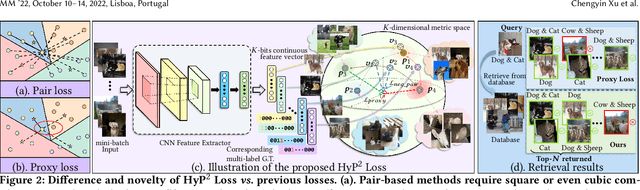
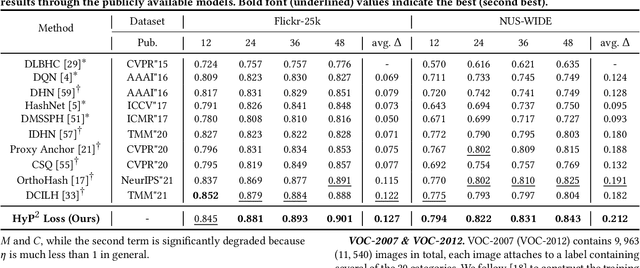
Image retrieval has become an increasingly appealing technique with broad multimedia application prospects, where deep hashing serves as the dominant branch towards low storage and efficient retrieval. In this paper, we carried out in-depth investigations on metric learning in deep hashing for establishing a powerful metric space in multi-label scenarios, where the pair loss suffers high computational overhead and converge difficulty, while the proxy loss is theoretically incapable of expressing the profound label dependencies and exhibits conflicts in the constructed hypersphere space. To address the problems, we propose a novel metric learning framework with Hybrid Proxy-Pair Loss (HyP$^2$ Loss) that constructs an expressive metric space with efficient training complexity w.r.t. the whole dataset. The proposed HyP$^2$ Loss focuses on optimizing the hypersphere space by learnable proxies and excavating data-to-data correlations of irrelevant pairs, which integrates sufficient data correspondence of pair-based methods and high-efficiency of proxy-based methods. Extensive experiments on four standard multi-label benchmarks justify the proposed method outperforms the state-of-the-art, is robust among different hash bits and achieves significant performance gains with a faster, more stable convergence speed. Our code is available at https://github.com/JerryXu0129/HyP2-Loss.
LocVTP: Video-Text Pre-training for Temporal Localization
Jul 21, 2022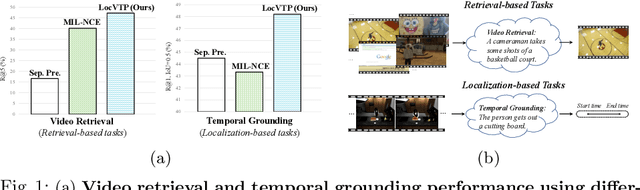
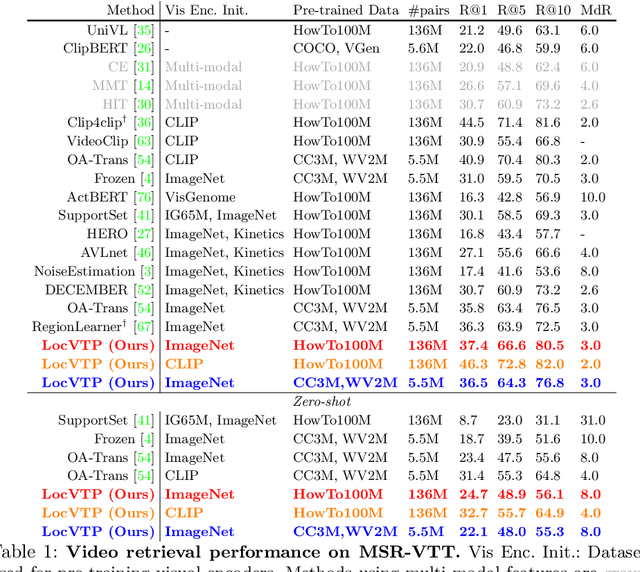
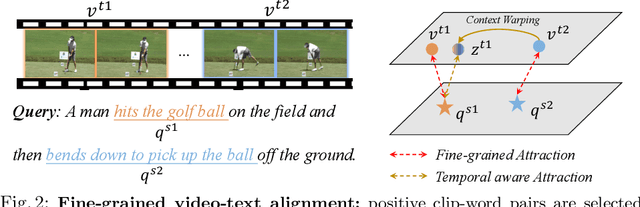
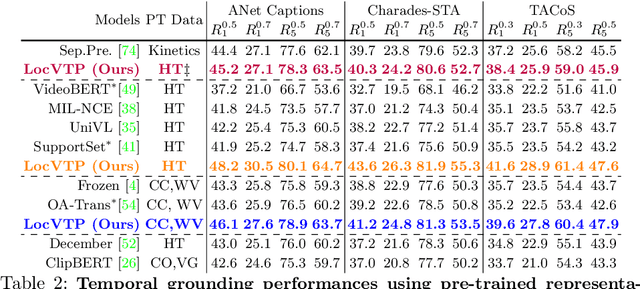
Video-Text Pre-training (VTP) aims to learn transferable representations for various downstream tasks from large-scale web videos. To date, almost all existing VTP methods are limited to retrieval-based downstream tasks, e.g., video retrieval, whereas their transfer potentials on localization-based tasks, e.g., temporal grounding, are under-explored. In this paper, we experimentally analyze and demonstrate the incompatibility of current VTP methods with localization tasks, and propose a novel Localization-oriented Video-Text Pre-training framework, dubbed as LocVTP. Specifically, we perform the fine-grained contrastive alignment as a complement to the coarse-grained one by a clip-word correspondence discovery scheme. To further enhance the temporal reasoning ability of the learned feature, we propose a context projection head and a temporal aware contrastive loss to perceive the contextual relationships. Extensive experiments on four downstream tasks across six datasets demonstrate that our LocVTP achieves state-of-the-art performance on both retrieval-based and localization-based tasks. Furthermore, we conduct comprehensive ablation studies and thorough analyses to explore the optimum model designs and training strategies.
Prior-Guided Adversarial Initialization for Fast Adversarial Training
Jul 18, 2022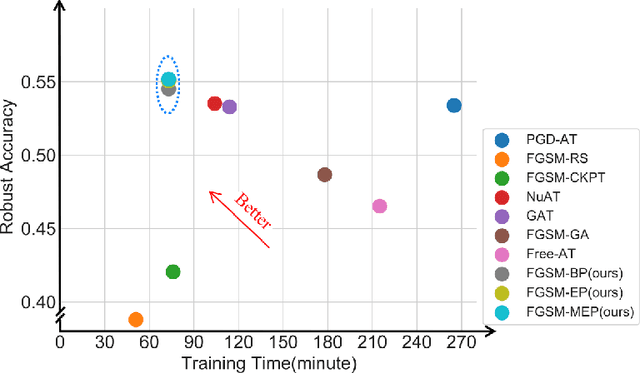
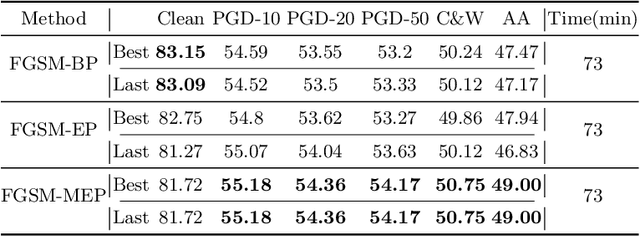
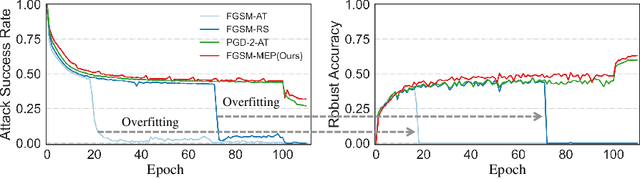
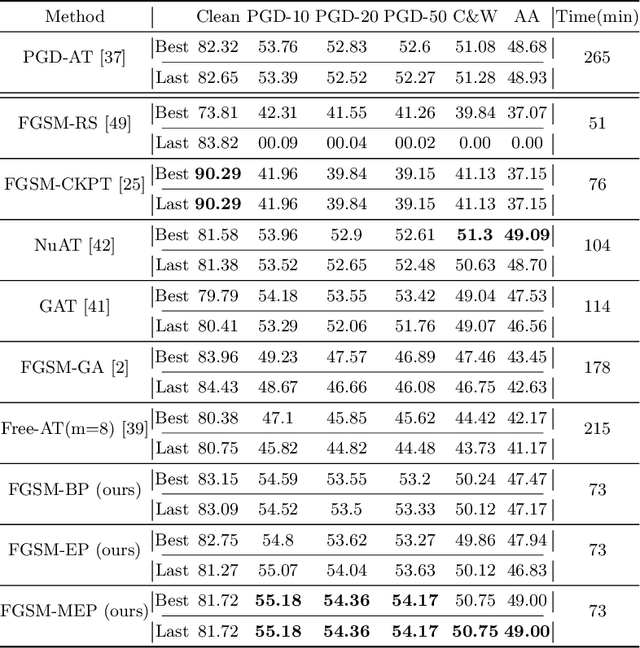
Fast adversarial training (FAT) effectively improves the efficiency of standard adversarial training (SAT). However, initial FAT encounters catastrophic overfitting, i.e.,the robust accuracy against adversarial attacks suddenly and dramatically decreases. Though several FAT variants spare no effort to prevent overfitting, they sacrifice much calculation cost. In this paper, we explore the difference between the training processes of SAT and FAT and observe that the attack success rate of adversarial examples (AEs) of FAT gets worse gradually in the late training stage, resulting in overfitting. The AEs are generated by the fast gradient sign method (FGSM) with a zero or random initialization. Based on the observation, we propose a prior-guided FGSM initialization method to avoid overfitting after investigating several initialization strategies, improving the quality of the AEs during the whole training process. The initialization is formed by leveraging historically generated AEs without additional calculation cost. We further provide a theoretical analysis for the proposed initialization method. We also propose a simple yet effective regularizer based on the prior-guided initialization,i.e., the currently generated perturbation should not deviate too much from the prior-guided initialization. The regularizer adopts both historical and current adversarial perturbations to guide the model learning. Evaluations on four datasets demonstrate that the proposed method can prevent catastrophic overfitting and outperform state-of-the-art FAT methods. The code is released at https://github.com/jiaxiaojunQAQ/FGSM-PGI.
* ECCV 2022
Neural Parameterization for Dynamic Human Head Editing
Jul 01, 2022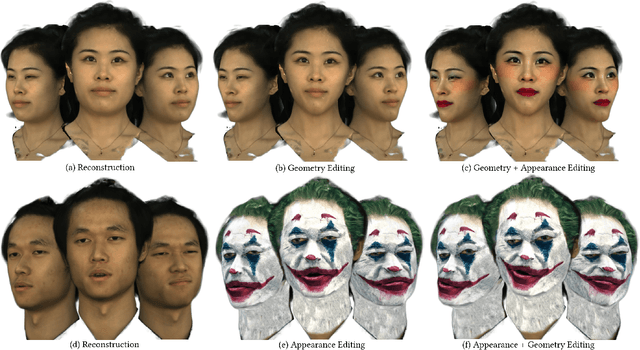

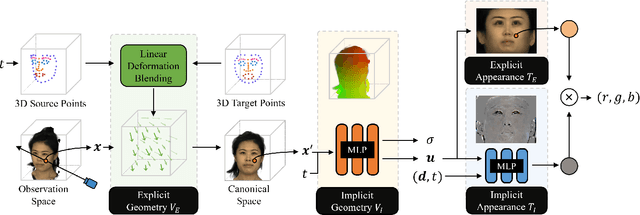

Implicit radiance functions emerged as a powerful scene representation for reconstructing and rendering photo-realistic views of a 3D scene. These representations, however, suffer from poor editability. On the other hand, explicit representations such as polygonal meshes allow easy editing but are not as suitable for reconstructing accurate details in dynamic human heads, such as fine facial features, hair, teeth, and eyes. In this work, we present Neural Parameterization (NeP), a hybrid representation that provides the advantages of both implicit and explicit methods. NeP is capable of photo-realistic rendering while allowing fine-grained editing of the scene geometry and appearance. We first disentangle the geometry and appearance by parameterizing the 3D geometry into 2D texture space. We enable geometric editability by introducing an explicit linear deformation blending layer. The deformation is controlled by a set of sparse key points, which can be explicitly and intuitively displaced to edit the geometry. For appearance, we develop a hybrid 2D texture consisting of an explicit texture map for easy editing and implicit view and time-dependent residuals to model temporal and view variations. We compare our method to several reconstruction and editing baselines. The results show that the NeP achieves almost the same level of rendering accuracy while maintaining high editability.