 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcedure-Aware Pretraining for Instructional Video Understanding
Mar 31, 2023



Our goal is to learn a video representation that is useful for downstream procedure understanding tasks in instructional videos. Due to the small amount of available annotations, a key challenge in procedure understanding is to be able to extract from unlabeled videos the procedural knowledge such as the identity of the task (e.g., 'make latte'), its steps (e.g., 'pour milk'), or the potential next steps given partial progress in its execution. Our main insight is that instructional videos depict sequences of steps that repeat between instances of the same or different tasks, and that this structure can be well represented by a Procedural Knowledge Graph (PKG), where nodes are discrete steps and edges connect steps that occur sequentially in the instructional activities. This graph can then be used to generate pseudo labels to train a video representation that encodes the procedural knowledge in a more accessible form to generalize to multiple procedure understanding tasks. We build a PKG by combining information from a text-based procedural knowledge database and an unlabeled instructional video corpus and then use it to generate training pseudo labels with four novel pre-training objectives. We call this PKG-based pre-training procedure and the resulting model Paprika, Procedure-Aware PRe-training for Instructional Knowledge Acquisition. We evaluate Paprika on COIN and CrossTask for procedure understanding tasks such as task recognition, step recognition, and step forecasting. Paprika yields a video representation that improves over the state of the art: up to 11.23% gains in accuracy in 12 evaluation settings. Implementation is available at https://github.com/salesforce/paprika.
Mask-free OVIS: Open-Vocabulary Instance Segmentation without Manual Mask Annotations
Mar 29, 2023



Existing instance segmentation models learn task-specific information using manual mask annotations from base (training) categories. These mask annotations require tremendous human effort, limiting the scalability to annotate novel (new) categories. To alleviate this problem, Open-Vocabulary (OV) methods leverage large-scale image-caption pairs and vision-language models to learn novel categories. In summary, an OV method learns task-specific information using strong supervision from base annotations and novel category information using weak supervision from image-captions pairs. This difference between strong and weak supervision leads to overfitting on base categories, resulting in poor generalization towards novel categories. In this work, we overcome this issue by learning both base and novel categories from pseudo-mask annotations generated by the vision-language model in a weakly supervised manner using our proposed Mask-free OVIS pipeline. Our method automatically generates pseudo-mask annotations by leveraging the localization ability of a pre-trained vision-language model for objects present in image-caption pairs. The generated pseudo-mask annotations are then used to supervise an instance segmentation model, freeing the entire pipeline from any labour-expensive instance-level annotations and overfitting. Our extensive experiments show that our method trained with just pseudo-masks significantly improves the mAP scores on the MS-COCO dataset and OpenImages dataset compared to the recent state-of-the-art methods trained with manual masks. Codes and models are provided in https://vibashan.github.io/ovis-web/.
On the Unlikelihood of D-Separation
Mar 10, 2023



Causal discovery aims to recover a causal graph from data generated by it; constraint based methods do so by searching for a d-separating conditioning set of nodes in the graph via an oracle. In this paper, we provide analytic evidence that on large graphs, d-separation is a rare phenomenon, even when guaranteed to exist, unless the graph is extremely sparse. We then provide an analytic average case analysis of the PC Algorithm for causal discovery, as well as a variant of the SGS Algorithm we call UniformSGS. We consider a set $V=\{v_1,\ldots,v_n\}$ of nodes, and generate a random DAG $G=(V,E)$ where $(v_a, v_b) \in E$ with i.i.d. probability $p_1$ if $a<b$ and $0$ if $a > b$. We provide upper bounds on the probability that a subset of $V-\{x,y\}$ d-separates $x$ and $y$, conditional on $x$ and $y$ being d-separable; our upper bounds decay exponentially fast to $0$ as $|V| \rightarrow \infty$. For the PC Algorithm, while it is known that its worst-case guarantees fail on non-sparse graphs, we show that the same is true for the average case, and that the sparsity requirement is quite demanding: for good performance, the density must go to $0$ as $|V| \rightarrow \infty$ even in the average case. For UniformSGS, while it is known that the running time is exponential for existing edges, we show that in the average case, that is the expected running time for most non-existing edges as well.
Deformer: Dynamic Fusion Transformer for Robust Hand Pose Estimation
Mar 09, 2023



Accurately estimating 3D hand pose is crucial for understanding how humans interact with the world. Despite remarkable progress, existing methods often struggle to generate plausible hand poses when the hand is heavily occluded or blurred. In videos, the movements of the hand allow us to observe various parts of the hand that may be occluded or blurred in a single frame. To adaptively leverage the visual clue before and after the occlusion or blurring for robust hand pose estimation, we propose the Deformer: a framework that implicitly reasons about the relationship between hand parts within the same image (spatial dimension) and different timesteps (temporal dimension). We show that a naive application of the transformer self-attention mechanism is not sufficient because motion blur or occlusions in certain frames can lead to heavily distorted hand features and generate imprecise keys and queries. To address this challenge, we incorporate a Dynamic Fusion Module into Deformer, which predicts the deformation of the hand and warps the hand mesh predictions from nearby frames to explicitly support the current frame estimation. Furthermore, we have observed that errors are unevenly distributed across different hand parts, with vertices around fingertips having disproportionately higher errors than those around the palm. We mitigate this issue by introducing a new loss function called maxMSE that automatically adjusts the weight of every vertex to focus the model on critical hand parts. Extensive experiments show that our method significantly outperforms state-of-the-art methods by 10%, and is more robust to occlusions (over 14%).
Salesforce CausalAI Library: A Fast and Scalable Framework for Causal Analysis of Time Series and Tabular Data
Jan 25, 2023



We introduce the Salesforce CausalAI Library, an open-source library for causal analysis using observational data. It supports causal discovery and causal inference for tabular and time series data, of both discrete and continuous types. This library includes algorithms that handle linear and non-linear causal relationships between variables, and uses multi-processing for speed-up. We also include a data generator capable of generating synthetic data with specified structural equation model for both the aforementioned data formats and types, that helps users control the ground-truth causal process while investigating various algorithms. Finally, we provide a user interface (UI) that allows users to perform causal analysis on data without coding. The goal of this library is to provide a fast and flexible solution for a variety of problems in the domain of causality. This technical report describes the Salesforce CausalAI API along with its capabilities, the implementations of the supported algorithms, and experiments demonstrating their performance and speed. Our library is available at \url{https://github.com/salesforce/causalai}.
Model-Agnostic Hierarchical Attention for 3D Object Detection
Jan 06, 2023



Transformers as versatile network architectures have recently seen great success in 3D point cloud object detection. However, the lack of hierarchy in a plain transformer makes it difficult to learn features at different scales and restrains its ability to extract localized features. Such limitation makes them have imbalanced performance on objects of different sizes, with inferior performance on smaller ones. In this work, we propose two novel attention mechanisms as modularized hierarchical designs for transformer-based 3D detectors. To enable feature learning at different scales, we propose Simple Multi-Scale Attention that builds multi-scale tokens from a single-scale input feature. For localized feature aggregation, we propose Size-Adaptive Local Attention with adaptive attention ranges for every bounding box proposal. Both of our attention modules are model-agnostic network layers that can be plugged into existing point cloud transformers for end-to-end training. We evaluate our method on two widely used indoor 3D point cloud object detection benchmarks. By plugging our proposed modules into the state-of-the-art transformer-based 3D detector, we improve the previous best results on both benchmarks, with the largest improvement margin on small objects.
LayoutDETR: Detection Transformer Is a Good Multimodal Layout Designer
Dec 19, 2022



Graphic layout designs play an essential role in visual communication. Yet handcrafting layout designs are skill-demanding, time-consuming, and non-scalable to batch production. Although generative models emerge to make design automation no longer utopian, it remains non-trivial to customize designs that comply with designers' multimodal desires, i.e., constrained by background images and driven by foreground contents. In this study, we propose \textit{LayoutDETR} that inherits the high quality and realism from generative modeling, in the meanwhile reformulating content-aware requirements as a detection problem: we learn to detect in a background image the reasonable locations, scales, and spatial relations for multimodal elements in a layout. Experiments validate that our solution yields new state-of-the-art performance for layout generation on public benchmarks and on our newly-curated ads banner dataset. For practical usage, we build our solution into a graphical system that facilitates user studies. We demonstrate that our designs attract more subjective preference than baselines by significant margins. Our code, models, dataset, graphical system, and demos are available at https://github.com/salesforce/LayoutDETR.
ULIP: Learning Unified Representation of Language, Image and Point Cloud for 3D Understanding
Dec 10, 2022



The understanding capabilities of current state-of-the-art 3D models are limited by datasets with a small number of annotated data and a pre-defined set of categories. In its 2D counterpart, recent advances have shown that similar problems can be significantly alleviated by employing knowledge from other modalities, such as language. Inspired by this, leveraging multimodal information for 3D modality could be promising to improve 3D understanding under the restricted data regime, but this line of research is not well studied. Therefore, we introduce ULIP to learn a unified representation of image, text, and 3D point cloud by pre-training with object triplets from the three modalities. To overcome the shortage of training triplets, ULIP leverages a pre-trained vision-language model that has already learned a common visual and textual space by training with massive image-text pairs. Then, ULIP learns a 3D representation space aligned with the common image-text space, using a small number of automatically synthesized triplets. ULIP is agnostic to 3D backbone networks and can easily be integrated into any 3D architecture. Experiments show that ULIP effectively improves the performance of multiple recent 3D backbones by simply pre-training them on ShapeNet55 using our framework, achieving state-of-the-art performance in both standard 3D classification and zero-shot 3D classification on ModelNet40 and ScanObjectNN. ULIP also improves the performance of PointMLP by around 3% in 3D classification on ScanObjectNN, and outperforms PointCLIP by 28.8% on top-1 accuracy for zero-shot 3D classification on ModelNet40. Our code and pre-trained models will be released.
Identifying Auxiliary or Adversarial Tasks Using Necessary Condition Analysis for Adversarial Multi-task Video Understanding
Aug 22, 2022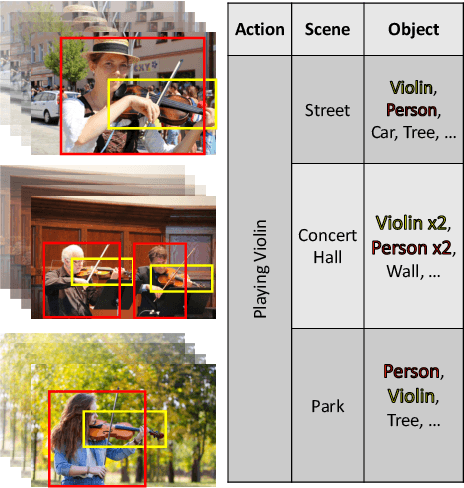
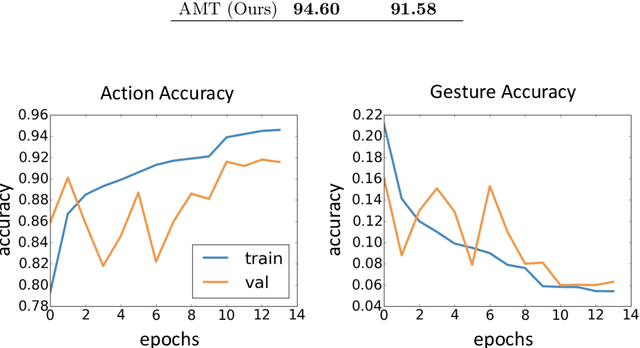
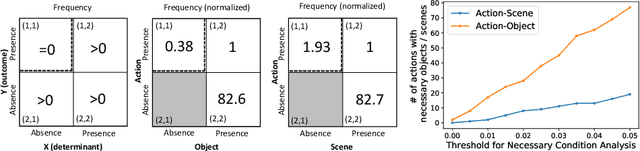
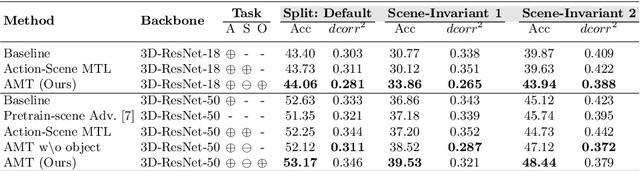
There has been an increasing interest in multi-task learning for video understanding in recent years. In this work, we propose a generalized notion of multi-task learning by incorporating both auxiliary tasks that the model should perform well on and adversarial tasks that the model should not perform well on. We employ Necessary Condition Analysis (NCA) as a data-driven approach for deciding what category these tasks should fall in. Our novel proposed framework, Adversarial Multi-Task Neural Networks (AMT), penalizes adversarial tasks, determined by NCA to be scene recognition in the Holistic Video Understanding (HVU) dataset, to improve action recognition. This upends the common assumption that the model should always be encouraged to do well on all tasks in multi-task learning. Simultaneously, AMT still retains all the benefits of multi-task learning as a generalization of existing methods and uses object recognition as an auxiliary task to aid action recognition. We introduce two challenging Scene-Invariant test splits of HVU, where the model is evaluated on action-scene co-occurrences not encountered in training. We show that our approach improves accuracy by ~3% and encourages the model to attend to action features instead of correlation-biasing scene features.
PrivHAR: Recognizing Human Actions From Privacy-preserving Lens
Jun 08, 2022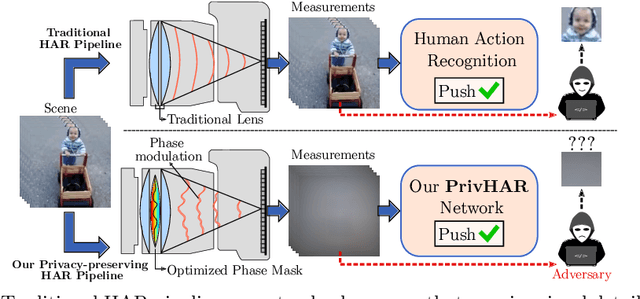
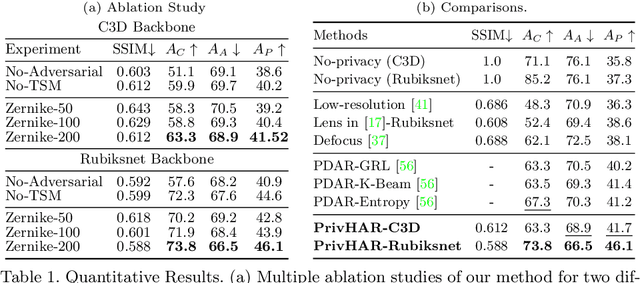
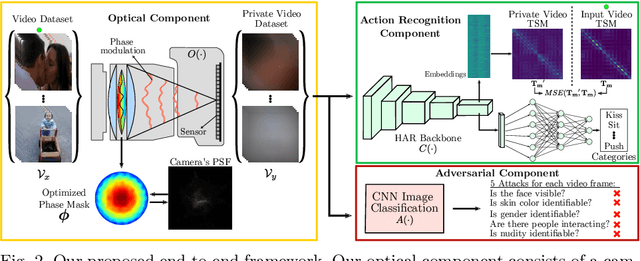
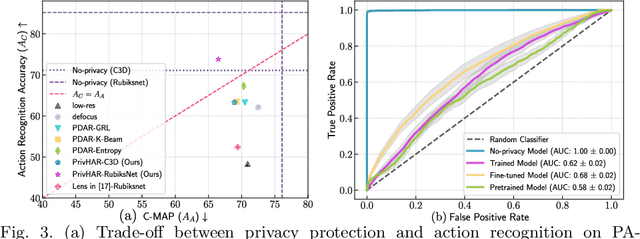
The accelerated use of digital cameras prompts an increasing concern about privacy and security, particularly in applications such as action recognition. In this paper, we propose an optimizing framework to provide robust visual privacy protection along the human action recognition pipeline. Our framework parameterizes the camera lens to successfully degrade the quality of the videos to inhibit privacy attributes and protect against adversarial attacks while maintaining relevant features for activity recognition. We validate our approach with extensive simulations and hardware experiments.