 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Roles of "Text" in Text Games
Oct 15, 2022
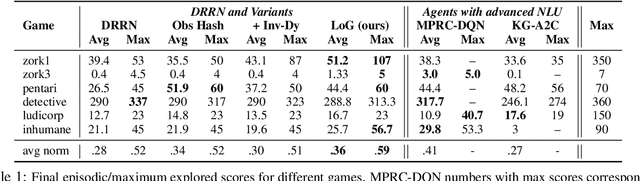
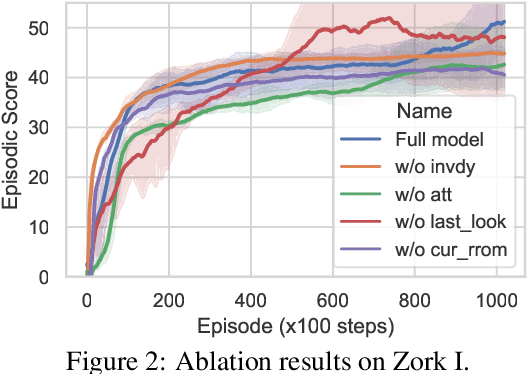
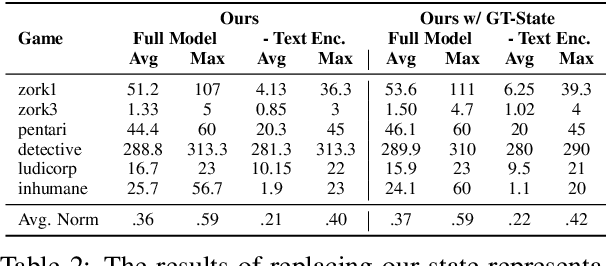
Text games present opportunities for natural language understanding (NLU) methods to tackle reinforcement learning (RL) challenges. However, recent work has questioned the necessity of NLU by showing random text hashes could perform decently. In this paper, we pursue a fine-grained investigation into the roles of text in the face of different RL challenges, and reconcile that semantic and non-semantic language representations could be complementary rather than contrasting. Concretely, we propose a simple scheme to extract relevant contextual information into an approximate state hash as extra input for an RNN-based text agent. Such a lightweight plug-in achieves competitive performance with state-of-the-art text agents using advanced NLU techniques such as knowledge graph and passage retrieval, suggesting non-NLU methods might suffice to tackle the challenge of partial observability. However, if we remove RNN encoders and use approximate or even ground-truth state hash alone, the model performs miserably, which confirms the importance of semantic function approximation to tackle the challenge of combinatorially large observation and action spaces. Our findings and analysis provide new insights for designing better text game task setups and agents.
Learning Physical Dynamics with Subequivariant Graph Neural Networks
Oct 13, 2022



Graph Neural Networks (GNNs) have become a prevailing tool for learning physical dynamics. However, they still encounter several challenges: 1) Physical laws abide by symmetry, which is a vital inductive bias accounting for model generalization and should be incorporated into the model design. Existing simulators either consider insufficient symmetry, or enforce excessive equivariance in practice when symmetry is partially broken by gravity. 2) Objects in the physical world possess diverse shapes, sizes, and properties, which should be appropriately processed by the model. To tackle these difficulties, we propose a novel backbone, Subequivariant Graph Neural Network, which 1) relaxes equivariance to subequivariance by considering external fields like gravity, where the universal approximation ability holds theoretically; 2) introduces a new subequivariant object-aware message passing for learning physical interactions between multiple objects of various shapes in the particle-based representation; 3) operates in a hierarchical fashion, allowing for modeling long-range and complex interactions. Our model achieves on average over 3% enhancement in contact prediction accuracy across 8 scenarios on Physion and 2X lower rollout MSE on RigidFall compared with state-of-the-art GNN simulators, while exhibiting strong generalization and data efficiency.
Abstract Interpretation for Generalized Heuristic Search in Model-Based Planning
Aug 05, 2022

Domain-general model-based planners often derive their generality by constructing search heuristics through the relaxation or abstraction of symbolic world models. We illustrate how abstract interpretation can serve as a unifying framework for these abstraction-based heuristics, extending the reach of heuristic search to richer world models that make use of more complex datatypes and functions (e.g. sets, geometry), and even models with uncertainty and probabilistic effects. These heuristics can also be integrated with learning, allowing agents to jumpstart planning in novel world models via abstraction-derived information that is later refined by experience. This suggests that abstract interpretation can play a key role in building universal reasoning systems.
Solving the Baby Intuitions Benchmark with a Hierarchically Bayesian Theory of Mind
Aug 04, 2022


To facilitate the development of new models to bridge the gap between machine and human social intelligence, the recently proposed Baby Intuitions Benchmark (arXiv:2102.11938) provides a suite of tasks designed to evaluate commonsense reasoning about agents' goals and actions that even young infants exhibit. Here we present a principled Bayesian solution to this benchmark, based on a hierarchically Bayesian Theory of Mind (HBToM). By including hierarchical priors on agent goals and dispositions, inference over our HBToM model enables few-shot learning of the efficiency and preferences of an agent, which can then be used in commonsense plausibility judgements about subsequent agent behavior. This approach achieves near-perfect accuracy on most benchmark tasks, outperforming deep learning and imitation learning baselines while producing interpretable human-like inferences, demonstrating the advantages of structured Bayesian models of human social cognition.
Robust Change Detection Based on Neural Descriptor Fields
Aug 01, 2022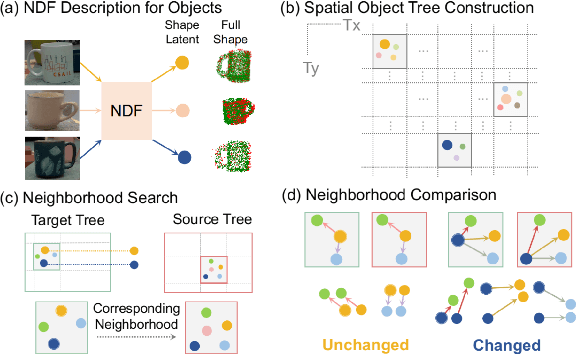
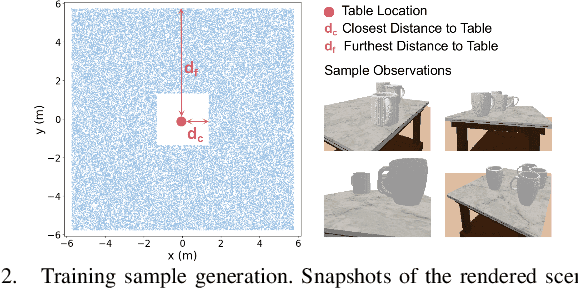
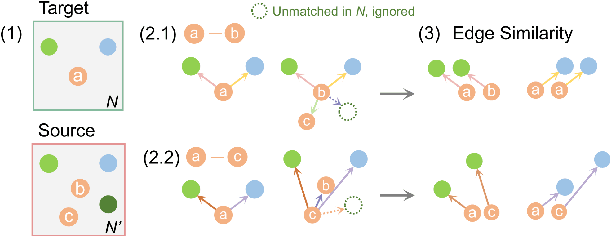
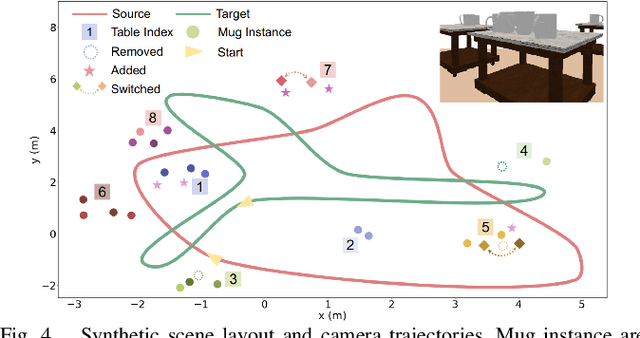
The ability to reason about changes in the environment is crucial for robots operating over extended periods of time. Agents are expected to capture changes during operation so that actions can be followed to ensure a smooth progression of the working session. However, varying viewing angles and accumulated localization errors make it easy for robots to falsely detect changes in the surrounding world due to low observation overlap and drifted object associations. In this paper, based on the recently proposed category-level Neural Descriptor Fields (NDFs), we develop an object-level online change detection approach that is robust to partially overlapping observations and noisy localization results. Utilizing the shape completion capability and SE(3)-equivariance of NDFs, we represent objects with compact shape codes encoding full object shapes from partial observations. The objects are then organized in a spatial tree structure based on object centers recovered from NDFs for fast queries of object neighborhoods. By associating objects via shape code similarity and comparing local object-neighbor spatial layout, our proposed approach demonstrates robustness to low observation overlap and localization noises. We conduct experiments on both synthetic and real-world sequences and achieve improved change detection results compared to multiple baseline methods. Project webpage: https://yilundu.github.io/ndf_change
Seeing 3D Objects in a Single Image via Self-Supervised Static-Dynamic Disentanglement
Jul 22, 2022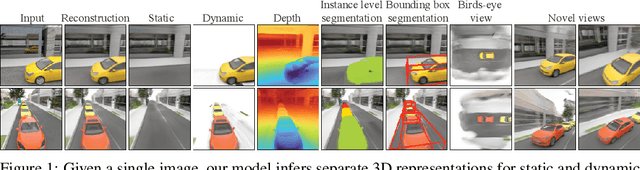
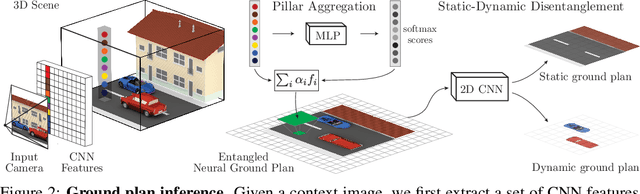
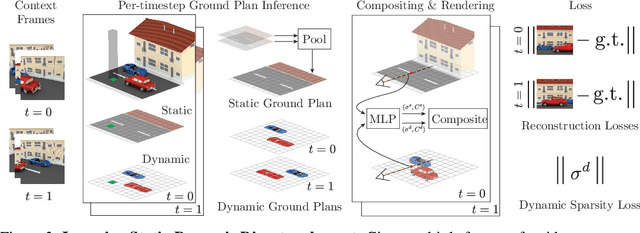

Human perception reliably identifies movable and immovable parts of 3D scenes, and completes the 3D structure of objects and background from incomplete observations. We learn this skill not via labeled examples, but simply by observing objects move. In this work, we propose an approach that observes unlabeled multi-view videos at training time and learns to map a single image observation of a complex scene, such as a street with cars, to a 3D neural scene representation that is disentangled into movable and immovable parts while plausibly completing its 3D structure. We separately parameterize movable and immovable scene parts via 2D neural ground plans. These ground plans are 2D grids of features aligned with the ground plane that can be locally decoded into 3D neural radiance fields. Our model is trained self-supervised via neural rendering. We demonstrate that the structure inherent to our disentangled 3D representation enables a variety of downstream tasks in street-scale 3D scenes using simple heuristics, such as extraction of object-centric 3D representations, novel view synthesis, instance segmentation, and 3D bounding box prediction, highlighting its value as a backbone for data-efficient 3D scene understanding models. This disentanglement further enables scene editing via object manipulation such as deletion, insertion, and rigid-body motion.
3D Concept Grounding on Neural Fields
Jul 13, 2022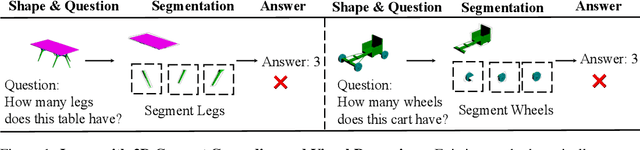
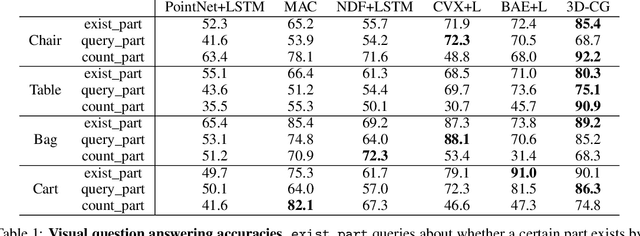
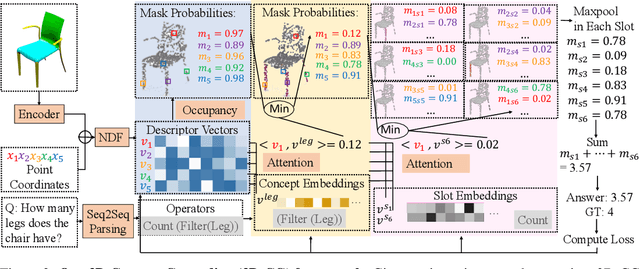
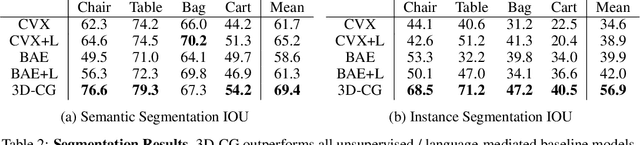
In this paper, we address the challenging problem of 3D concept grounding (i.e. segmenting and learning visual concepts) by looking at RGBD images and reasoning about paired questions and answers. Existing visual reasoning approaches typically utilize supervised methods to extract 2D segmentation masks on which concepts are grounded. In contrast, humans are capable of grounding concepts on the underlying 3D representation of images. However, traditionally inferred 3D representations (e.g., point clouds, voxelgrids, and meshes) cannot capture continuous 3D features flexibly, thus making it challenging to ground concepts to 3D regions based on the language description of the object being referred to. To address both issues, we propose to leverage the continuous, differentiable nature of neural fields to segment and learn concepts. Specifically, each 3D coordinate in a scene is represented as a high-dimensional descriptor. Concept grounding can then be performed by computing the similarity between the descriptor vector of a 3D coordinate and the vector embedding of a language concept, which enables segmentations and concept learning to be jointly learned on neural fields in a differentiable fashion. As a result, both 3D semantic and instance segmentations can emerge directly from question answering supervision using a set of defined neural operators on top of neural fields (e.g., filtering and counting). Experimental results show that our proposed framework outperforms unsupervised/language-mediated segmentation models on semantic and instance segmentation tasks, as well as outperforms existing models on the challenging 3D aware visual reasoning tasks. Furthermore, our framework can generalize well to unseen shape categories and real scans.
Finding Fallen Objects Via Asynchronous Audio-Visual Integration
Jul 07, 2022
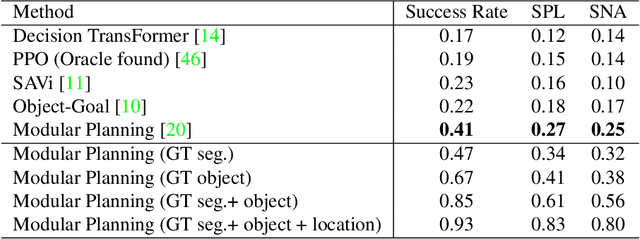

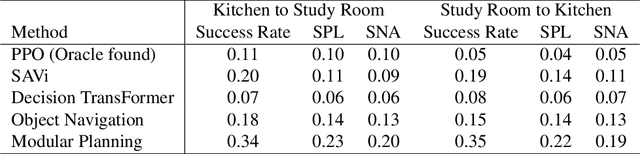
The way an object looks and sounds provide complementary reflections of its physical properties. In many settings cues from vision and audition arrive asynchronously but must be integrated, as when we hear an object dropped on the floor and then must find it. In this paper, we introduce a setting in which to study multi-modal object localization in 3D virtual environments. An object is dropped somewhere in a room. An embodied robot agent, equipped with a camera and microphone, must determine what object has been dropped -- and where -- by combining audio and visual signals with knowledge of the underlying physics. To study this problem, we have generated a large-scale dataset -- the Fallen Objects dataset -- that includes 8000 instances of 30 physical object categories in 64 rooms. The dataset uses the ThreeDWorld platform which can simulate physics-based impact sounds and complex physical interactions between objects in a photorealistic setting. As a first step toward addressing this challenge, we develop a set of embodied agent baselines, based on imitation learning, reinforcement learning, and modular planning, and perform an in-depth analysis of the challenge of this new task.
Learning Iterative Reasoning through Energy Minimization
Jun 30, 2022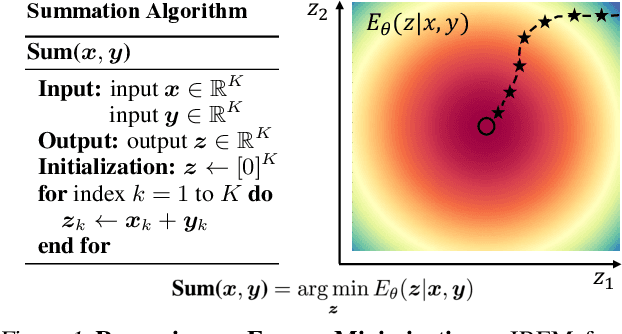
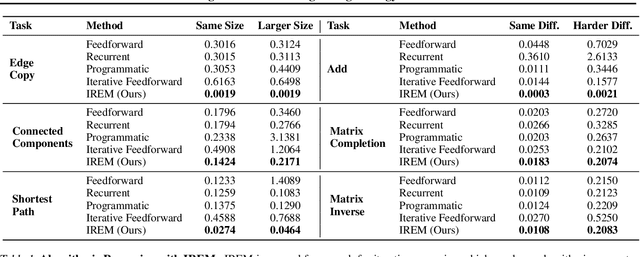
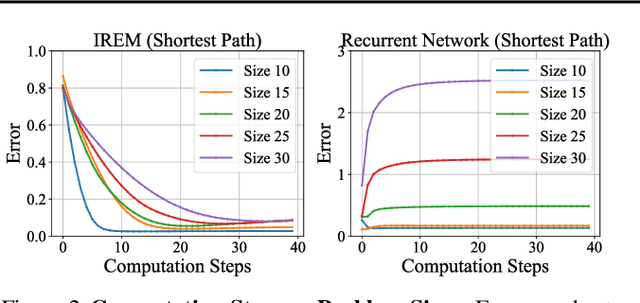
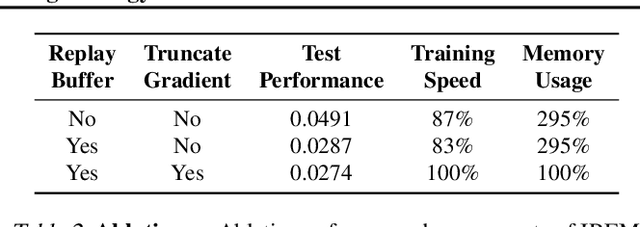
Deep learning has excelled on complex pattern recognition tasks such as image classification and object recognition. However, it struggles with tasks requiring nontrivial reasoning, such as algorithmic computation. Humans are able to solve such tasks through iterative reasoning -- spending more time thinking about harder tasks. Most existing neural networks, however, exhibit a fixed computational budget controlled by the neural network architecture, preventing additional computational processing on harder tasks. In this work, we present a new framework for iterative reasoning with neural networks. We train a neural network to parameterize an energy landscape over all outputs, and implement each step of the iterative reasoning as an energy minimization step to find a minimal energy solution. By formulating reasoning as an energy minimization problem, for harder problems that lead to more complex energy landscapes, we may then adjust our underlying computational budget by running a more complex optimization procedure. We empirically illustrate that our iterative reasoning approach can solve more accurate and generalizable algorithmic reasoning tasks in both graph and continuous domains. Finally, we illustrate that our approach can recursively solve algorithmic problems requiring nested reasoning
Prompting Decision Transformer for Few-Shot Policy Generalization
Jun 27, 2022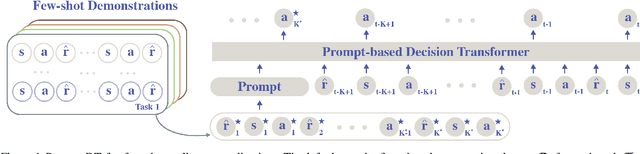
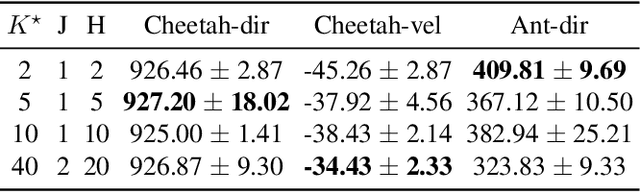
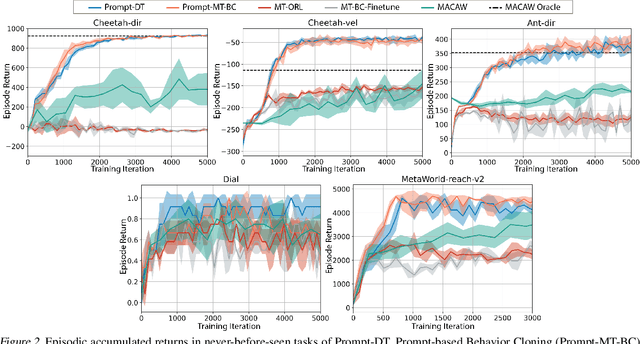
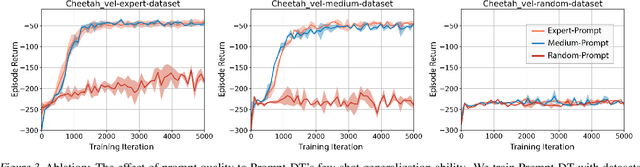
Humans can leverage prior experience and learn novel tasks from a handful of demonstrations. In contrast to offline meta-reinforcement learning, which aims to achieve quick adaptation through better algorithm design, we investigate the effect of architecture inductive bias on the few-shot learning capability. We propose a Prompt-based Decision Transformer (Prompt-DT), which leverages the sequential modeling ability of the Transformer architecture and the prompt framework to achieve few-shot adaptation in offline RL. We design the trajectory prompt, which contains segments of the few-shot demonstrations, and encodes task-specific information to guide policy generation. Our experiments in five MuJoCo control benchmarks show that Prompt-DT is a strong few-shot learner without any extra finetuning on unseen target tasks. Prompt-DT outperforms its variants and strong meta offline RL baselines by a large margin with a trajectory prompt containing only a few timesteps. Prompt-DT is also robust to prompt length changes and can generalize to out-of-distribution (OOD) environments.