 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Gated Linear Networks
Jun 10, 2020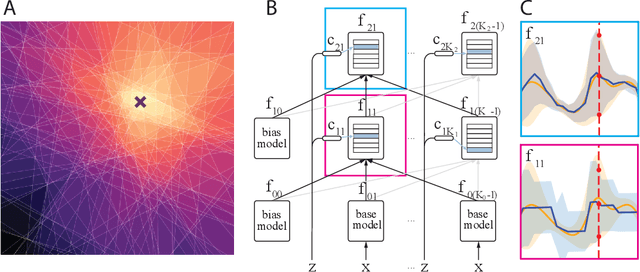
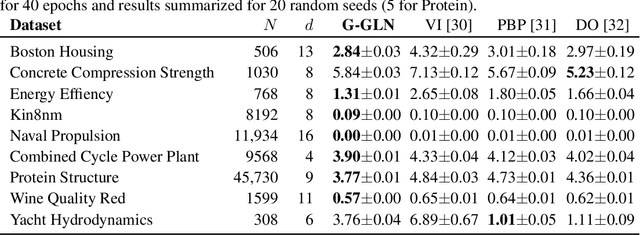
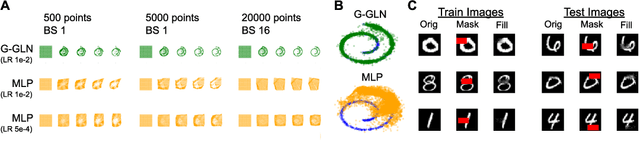
We propose the Gaussian Gated Linear Network (G-GLN), an extension to the recently proposed GLN family of deep neural networks. Instead of using backpropagation to learn features, GLNs have a distributed and local credit assignment mechanism based on optimizing a convex objective. This gives rise to many desirable properties including universality, data-efficient online learning, trivial interpretability and robustness to catastrophic forgetting. We extend the GLN framework from classification to multiple regression and density modelling by generalizing geometric mixing to a product of Gaussian densities. The G-GLN achieves competitive or state-of-the-art performance on several univariate and multivariate regression benchmarks, and we demonstrate its applicability to practical tasks including online contextual bandits and density estimation via denoising.
Online Learning in Contextual Bandits using Gated Linear Networks
Feb 21, 2020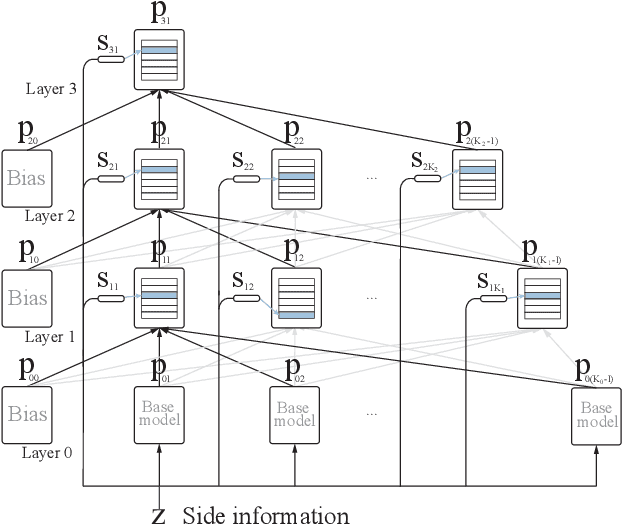
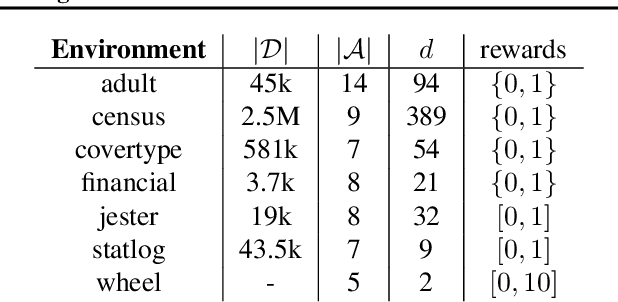
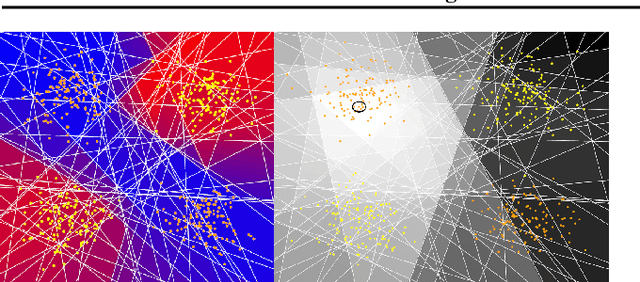
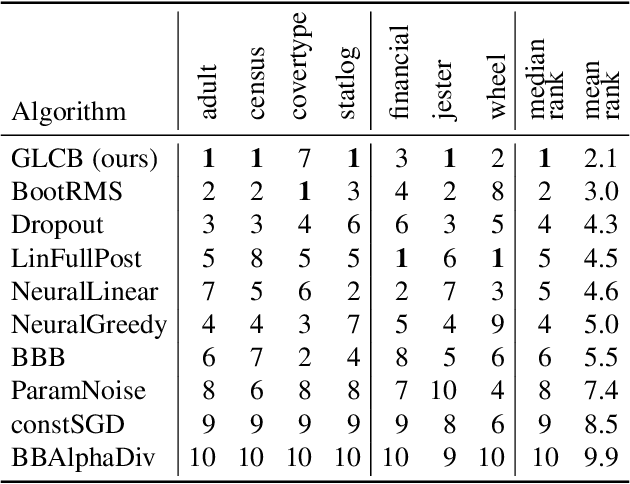
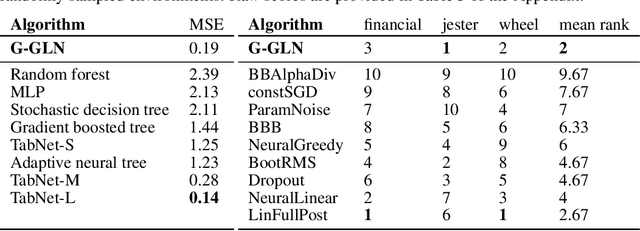
We introduce a new and completely online contextual bandit algorithm called Gated Linear Contextual Bandits (GLCB). This algorithm is based on Gated Linear Networks (GLNs), a recently introduced deep learning architecture with properties well-suited to the online setting. Leveraging data-dependent gating properties of the GLN we are able to estimate prediction uncertainty with effectively zero algorithmic overhead. We empirically evaluate GLCB compared to 9 state-of-the-art algorithms that leverage deep neural networks, on a standard benchmark suite of discrete and continuous contextual bandit problems. GLCB obtains median first-place despite being the only online method, and we further support these results with a theoretical study of its convergence properties.
Gated Linear Networks
Sep 30, 2019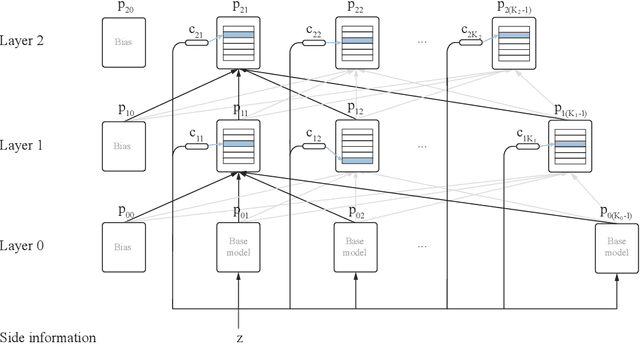
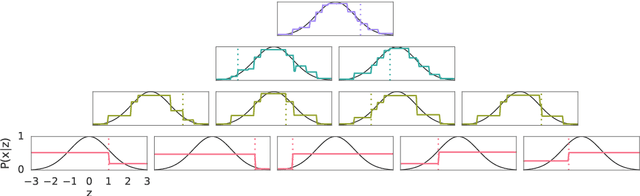
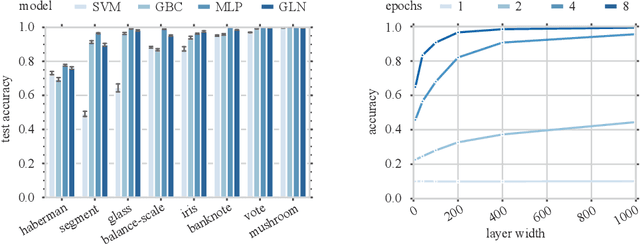
This paper presents a family of backpropagation-free neural architectures, Gated Linear Networks (GLNs),that are well suited to online learning applications where sample efficiency is of paramount importance. The impressive empirical performance of these architectures has long been known within the data compression community, but a theoretically satisfying explanation as to how and why they perform so well has proven difficult. What distinguishes these architectures from other neural systems is the distributed and local nature of their credit assignment mechanism; each neuron directly predicts the target and has its own set of hard-gated weights that are locally adapted via online convex optimization. By providing an interpretation, generalization and subsequent theoretical analysis, we show that sufficiently large GLNs are universal in a strong sense: not only can they model any compactly supported, continuous density function to arbitrary accuracy, but that any choice of no-regret online convex optimization technique will provably converge to the correct solution with enough data. Empirically we show a collection of single-pass learning results on established machine learning benchmarks that are competitive with results obtained with general purpose batch learning techniques.
Meta-learning of Sequential Strategies
May 08, 2019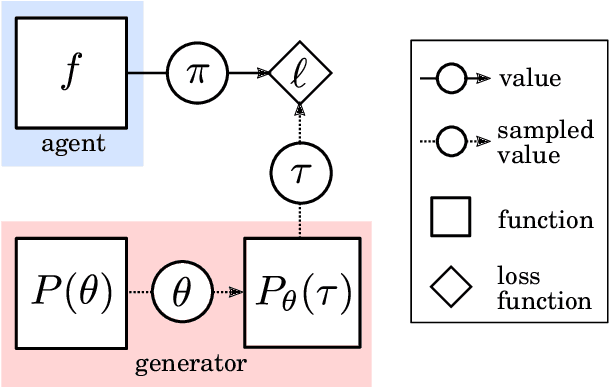
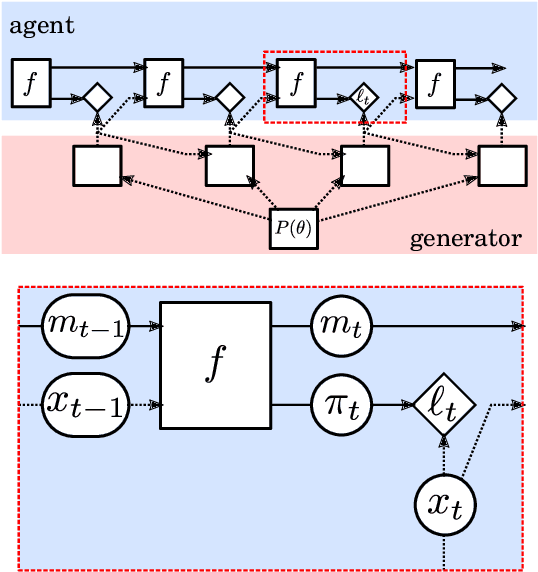
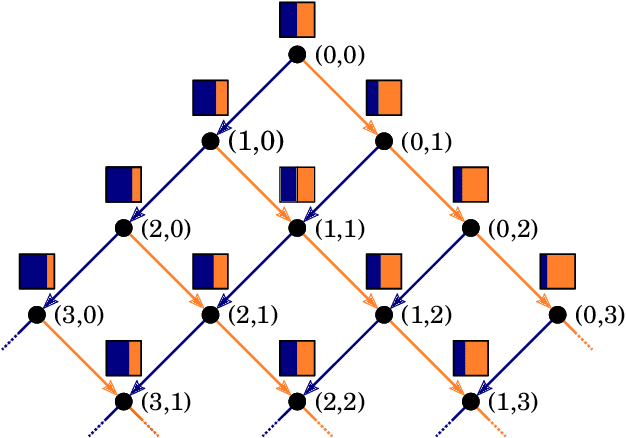
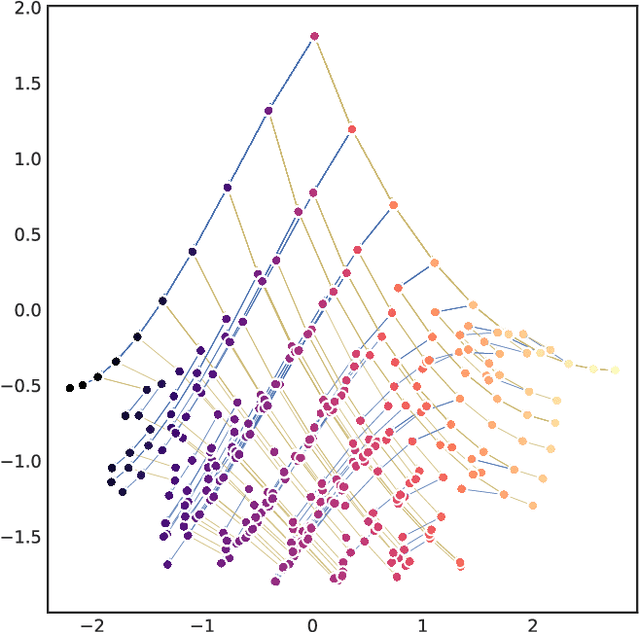
In this report we review memory-based meta-learning as a tool for building sample-efficient strategies that learn from past experience to adapt to any task within a target class. Our goal is to equip the reader with the conceptual foundations of this tool for building new, scalable agents that operate on broad domains. To do so, we present basic algorithmic templates for building near-optimal predictors and reinforcement learners which behave as if they had a probabilistic model that allowed them to efficiently exploit task structure. Furthermore, we recast memory-based meta-learning within a Bayesian framework, showing that the meta-learned strategies are near-optimal because they amortize Bayes-filtered data, where the adaptation is implemented in the memory dynamics as a state-machine of sufficient statistics. Essentially, memory-based meta-learning translates the hard problem of probabilistic sequential inference into a regression problem.
Online Learning with Gated Linear Networks
Dec 05, 2017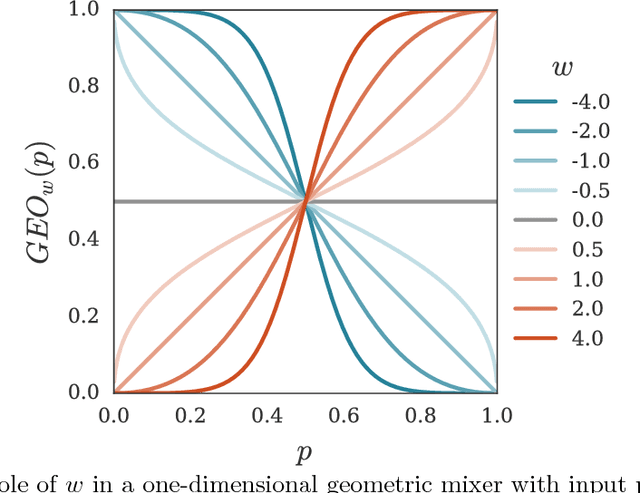
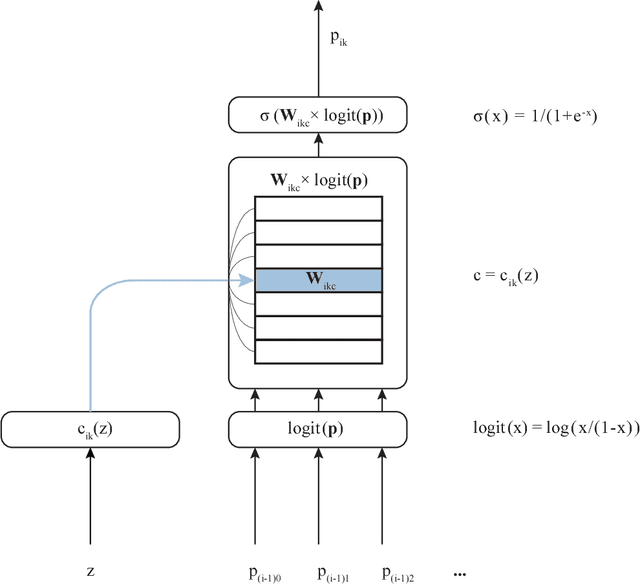
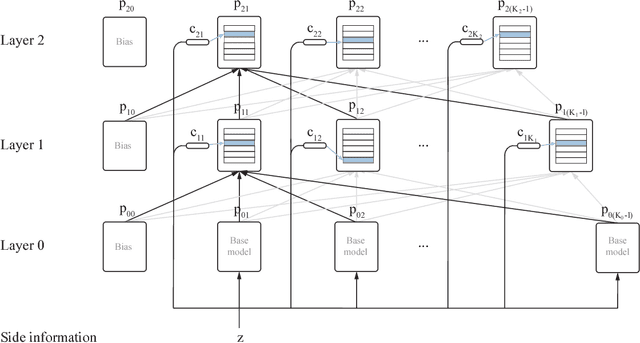
This paper describes a family of probabilistic architectures designed for online learning under the logarithmic loss. Rather than relying on non-linear transfer functions, our method gains representational power by the use of data conditioning. We state under general conditions a learnable capacity theorem that shows this approach can in principle learn any bounded Borel-measurable function on a compact subset of euclidean space; the result is stronger than many universality results for connectionist architectures because we provide both the model and the learning procedure for which convergence is guaranteed.
Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents
Dec 01, 2017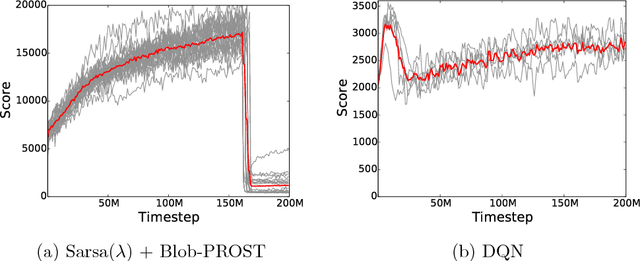
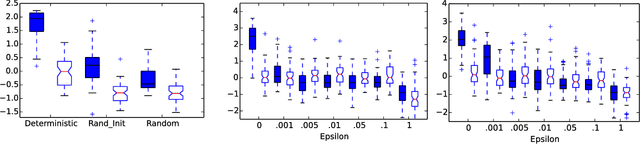
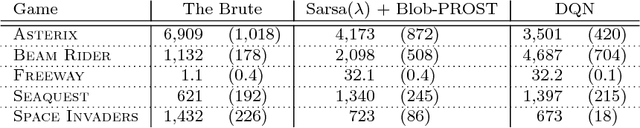

The Arcade Learning Environment (ALE) is an evaluation platform that poses the challenge of building AI agents with general competency across dozens of Atari 2600 games. It supports a variety of different problem settings and it has been receiving increasing attention from the scientific community, leading to some high-profile success stories such as the much publicized Deep Q-Networks (DQN). In this article we take a big picture look at how the ALE is being used by the research community. We show how diverse the evaluation methodologies in the ALE have become with time, and highlight some key concerns when evaluating agents in the ALE. We use this discussion to present some methodological best practices and provide new benchmark results using these best practices. To further the progress in the field, we introduce a new version of the ALE that supports multiple game modes and provides a form of stochasticity we call sticky actions. We conclude this big picture look by revisiting challenges posed when the ALE was introduced, summarizing the state-of-the-art in various problems and highlighting problems that remain open.
Overcoming catastrophic forgetting in neural networks
Jan 25, 2017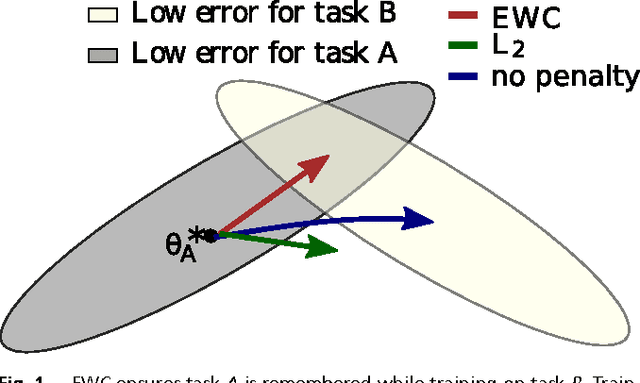
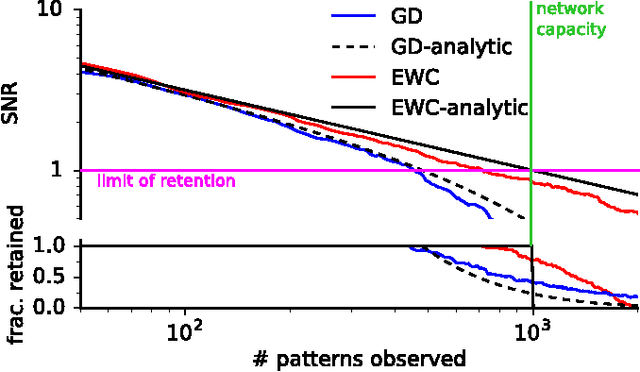
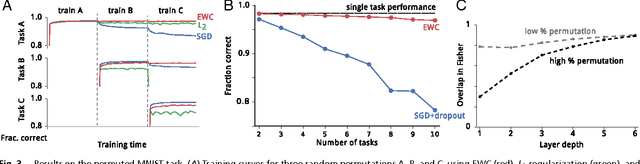
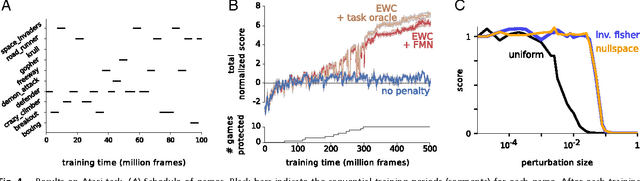
The ability to learn tasks in a sequential fashion is crucial to the development of artificial intelligence. Neural networks are not, in general, capable of this and it has been widely thought that catastrophic forgetting is an inevitable feature of connectionist models. We show that it is possible to overcome this limitation and train networks that can maintain expertise on tasks which they have not experienced for a long time. Our approach remembers old tasks by selectively slowing down learning on the weights important for those tasks. We demonstrate our approach is scalable and effective by solving a set of classification tasks based on the MNIST hand written digit dataset and by learning several Atari 2600 games sequentially.
Compress and Control
Nov 19, 2014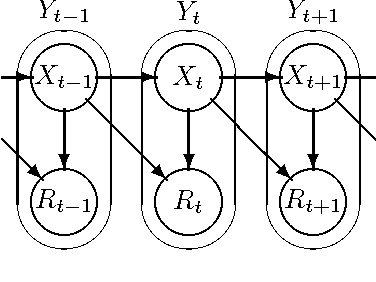
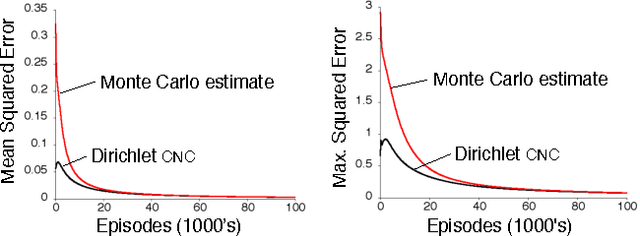
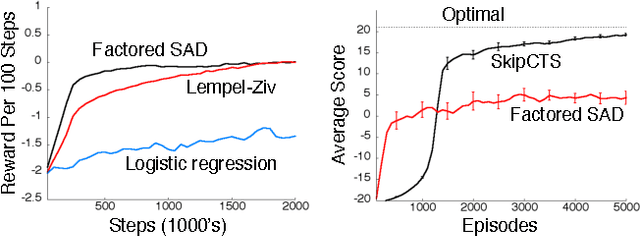
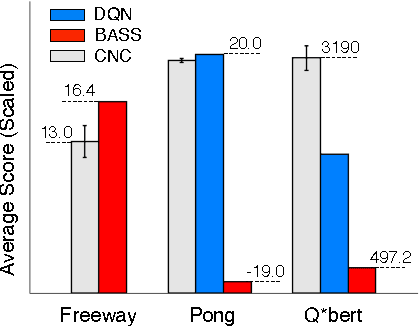
This paper describes a new information-theoretic policy evaluation technique for reinforcement learning. This technique converts any compression or density model into a corresponding estimate of value. Under appropriate stationarity and ergodicity conditions, we show that the use of a sufficiently powerful model gives rise to a consistent value function estimator. We also study the behavior of this technique when applied to various Atari 2600 video games, where the use of suboptimal modeling techniques is unavoidable. We consider three fundamentally different models, all too limited to perfectly model the dynamics of the system. Remarkably, we find that our technique provides sufficiently accurate value estimates for effective on-policy control. We conclude with a suggestive study highlighting the potential of our technique to scale to large problems.
Online Learning of k-CNF Boolean Functions
Mar 26, 2014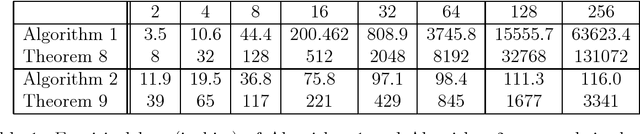
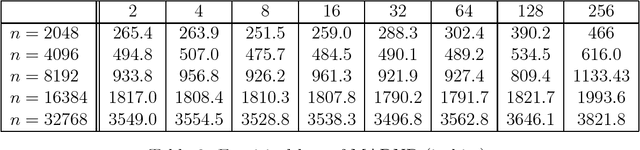
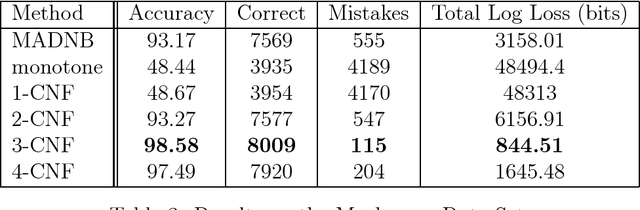
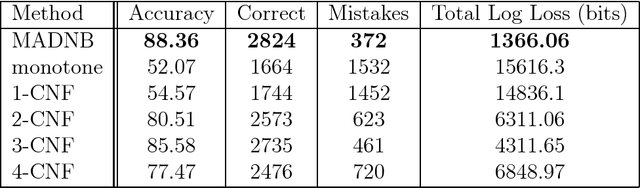
This paper revisits the problem of learning a k-CNF Boolean function from examples in the context of online learning under the logarithmic loss. In doing so, we give a Bayesian interpretation to one of Valiant's celebrated PAC learning algorithms, which we then build upon to derive two efficient, online, probabilistic, supervised learning algorithms for predicting the output of an unknown k-CNF Boolean function. We analyze the loss of our methods, and show that the cumulative log-loss can be upper bounded, ignoring logarithmic factors, by a polynomial function of the size of each example.
The Arcade Learning Environment: An Evaluation Platform for General Agents
Jun 21, 2013

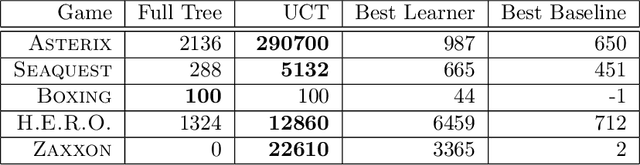
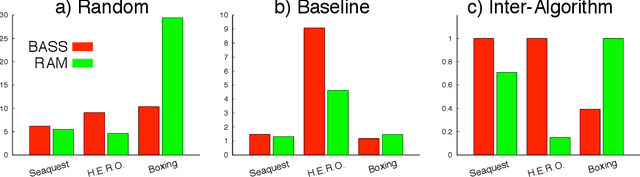
In this article we introduce the Arcade Learning Environment (ALE): both a challenge problem and a platform and methodology for evaluating the development of general, domain-independent AI technology. ALE provides an interface to hundreds of Atari 2600 game environments, each one different, interesting, and designed to be a challenge for human players. ALE presents significant research challenges for reinforcement learning, model learning, model-based planning, imitation learning, transfer learning, and intrinsic motivation. Most importantly, it provides a rigorous testbed for evaluating and comparing approaches to these problems. We illustrate the promise of ALE by developing and benchmarking domain-independent agents designed using well-established AI techniques for both reinforcement learning and planning. In doing so, we also propose an evaluation methodology made possible by ALE, reporting empirical results on over 55 different games. All of the software, including the benchmark agents, is publicly available.