 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Rank Collapse in Feedback Alignment
Jun 09, 2026Backpropagation (BP) is widely viewed as biologically implausible, in part because it requires feedback weights to be the transpose of forward weights for error propagation. Interestingly, when training a network with fixed random feedback weights to circumvent this issue, learning aligns the forward weights with the feedback weights, leading the backpropagated error signal to become an approximation of the standard gradient used by BP. This process, called Feedback Alignment (FA), occurs in MLPs and very shallow CNNs but does not scale well to deeper architectures. In this work, we first investigated differences between BP and FA models, trained on CIFAR10, specifically focusing on the effective rank of the signal. We found that the FA error has a considerably lower rank and hence is constrained to a lower-dimensional subspace compared to BP, limiting exploration of the parameter space. Motivated by this observation, we evaluated two mechanisms for increasing the effective dimensionality of FA: Muon, an optimiser that orthogonalises weight updates; and hidden activity normalisation, which promotes activation orthogonality. Across larger architectures and benchmarks, we find that these methods consistently improve over FA baselines, for example, on CIFAR100 with a Resnet-18, accuracy increases by 9 percentage points. Our results identify low-dimensional gradient dynamics as a key obstacle to scaling FA and suggest that inducing higher-dimensional update geometry is a promising route toward scaling alternatives to backpropagation.
Uncertainty Prioritized Experience Replay
Jun 10, 2025



Prioritized experience replay, which improves sample efficiency by selecting relevant transitions to update parameter estimates, is a crucial component of contemporary value-based deep reinforcement learning models. Typically, transitions are prioritized based on their temporal difference error. However, this approach is prone to favoring noisy transitions, even when the value estimation closely approximates the target mean. This phenomenon resembles the noisy TV problem postulated in the exploration literature, in which exploration-guided agents get stuck by mistaking noise for novelty. To mitigate the disruptive effects of noise in value estimation, we propose using epistemic uncertainty estimation to guide the prioritization of transitions from the replay buffer. Epistemic uncertainty quantifies the uncertainty that can be reduced by learning, hence reducing transitions sampled from the buffer generated by unpredictable random processes. We first illustrate the benefits of epistemic uncertainty prioritized replay in two tabular toy models: a simple multi-arm bandit task, and a noisy gridworld. Subsequently, we evaluate our prioritization scheme on the Atari suite, outperforming quantile regression deep Q-learning benchmarks; thus forging a path for the use of uncertainty prioritized replay in reinforcement learning agents.
Relational reasoning and inductive bias in transformers trained on a transitive inference task
Jun 04, 2025



Transformer-based models have demonstrated remarkable reasoning abilities, but the mechanisms underlying relational reasoning in different learning regimes remain poorly understood. In this work, we investigate how transformers perform a classic relational reasoning task from the Psychology literature, \textit{transitive inference}, which requires inference about indirectly related items by integrating information across observed adjacent item pairs (e.g., if A>B and B>C, then A>C). We compare transitive inference behavior across two distinct learning regimes: in-weights learning (IWL), where models store information in network parameters, and in-context learning (ICL), where models flexibly utilize information presented within the input sequence. Our findings reveal that IWL naturally induces a generalization bias towards transitive inference, despite being trained only on adjacent items, whereas ICL models trained solely on adjacent items do not generalize transitively. Mechanistic analysis shows that ICL models develop induction circuits that implement a simple match-and-copy strategy that performs well at relating adjacent pairs, but does not encoding hierarchical relationships among indirectly related items. Interestingly, when pre-trained on in-context linear regression tasks, transformers successfully exhibit in-context generalizable transitive inference. Moreover, like IWL, they display both \textit{symbolic distance} and \textit{terminal item effects} characteristic of human and animal performance, without forming induction circuits. These results suggest that pre-training on tasks with underlying structure promotes the development of representations that can scaffold in-context relational reasoning.
Lifelong Reinforcement Learning via Neuromodulation
Aug 15, 2024



Navigating multiple tasks$\unicode{x2014}$for instance in succession as in continual or lifelong learning, or in distributions as in meta or multi-task learning$\unicode{x2014}$requires some notion of adaptation. Evolution over timescales of millennia has imbued humans and other animals with highly effective adaptive learning and decision-making strategies. Central to these functions are so-called neuromodulatory systems. In this work we introduce an abstract framework for integrating theories and evidence from neuroscience and the cognitive sciences into the design of adaptive artificial reinforcement learning algorithms. We give a concrete instance of this framework built on literature surrounding the neuromodulators Acetylcholine (ACh) and Noradrenaline (NA), and empirically validate the effectiveness of the resulting adaptive algorithm in a non-stationary multi-armed bandit problem. We conclude with a theory-based experiment proposal providing an avenue to link our framework back to efforts in experimental neuroscience.
Toward Next-Generation Artificial Intelligence: Catalyzing the NeuroAI Revolution
Oct 15, 2022Neuroscience has long been an important driver of progress in artificial intelligence (AI). We propose that to accelerate progress in AI, we must invest in fundamental research in NeuroAI.
When Does Re-initialization Work?
Jun 20, 2022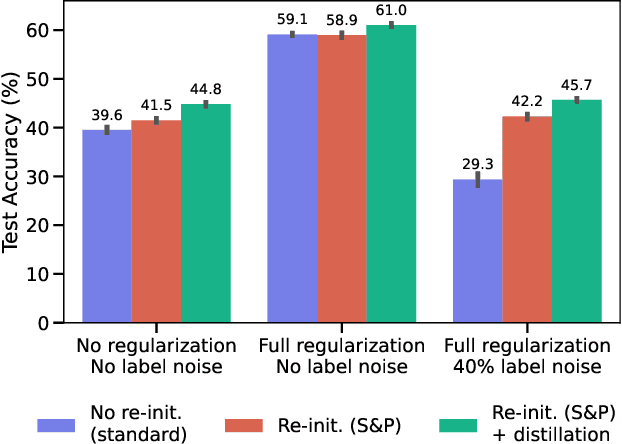
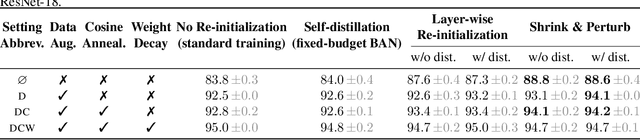
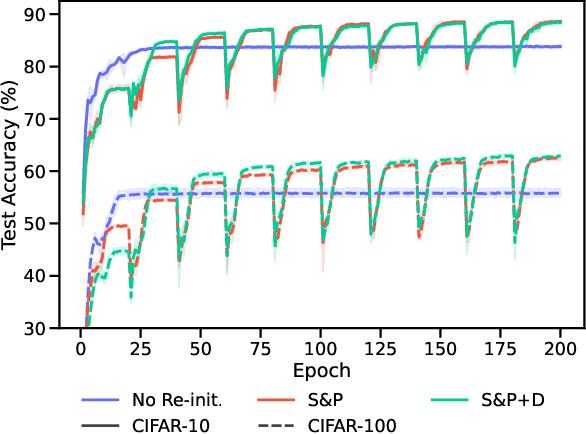

Re-initializing a neural network during training has been observed to improve generalization in recent works. Yet it is neither widely adopted in deep learning practice nor is it often used in state-of-the-art training protocols. This raises the question of when re-initialization works, and whether it should be used together with regularization techniques such as data augmentation, weight decay and learning rate schedules. In this work, we conduct an extensive empirical comparison of standard training with a selection of re-initialization methods to answer this question, training over 15,000 models on a variety of image classification benchmarks. We first establish that such methods are consistently beneficial for generalization in the absence of any other regularization. However, when deployed alongside other carefully tuned regularization techniques, re-initialization methods offer little to no added benefit for generalization, although optimal generalization performance becomes less sensitive to the choice of learning rate and weight decay hyperparameters. To investigate the impact of re-initialization methods on noisy data, we also consider learning under label noise. Surprisingly, in this case, re-initialization significantly improves upon standard training, even in the presence of other carefully tuned regularization techniques.
Maslow's Hammer for Catastrophic Forgetting: Node Re-Use vs Node Activation
May 18, 2022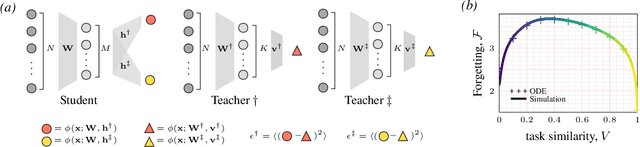
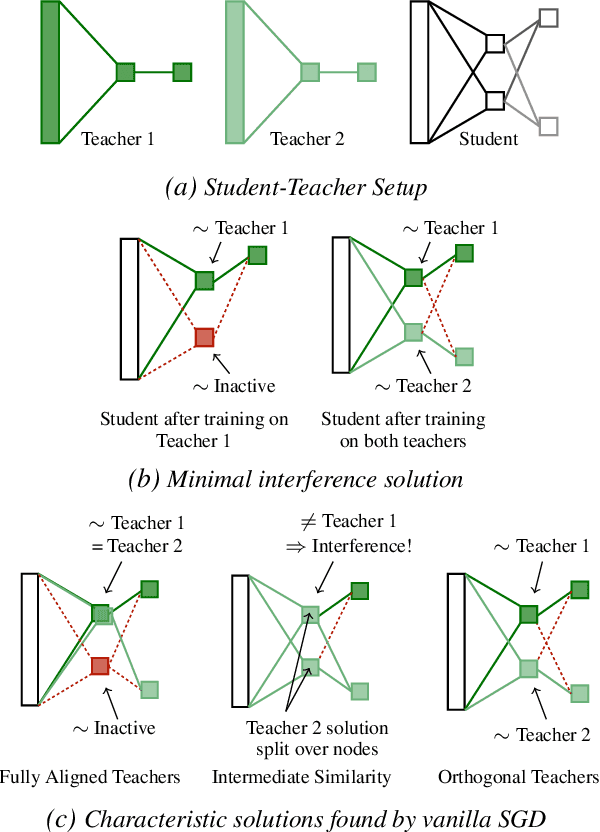
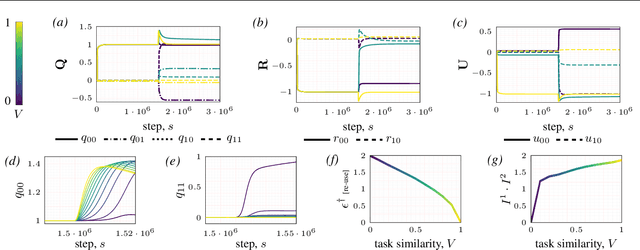
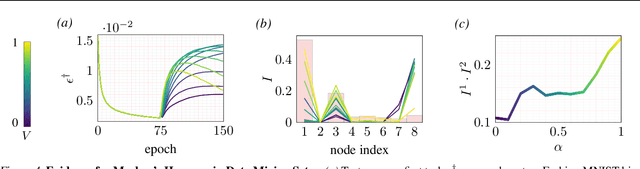
Continual learning - learning new tasks in sequence while maintaining performance on old tasks - remains particularly challenging for artificial neural networks. Surprisingly, the amount of forgetting does not increase with the dissimilarity between the learned tasks, but appears to be worst in an intermediate similarity regime. In this paper we theoretically analyse both a synthetic teacher-student framework and a real data setup to provide an explanation of this phenomenon that we name Maslow's hammer hypothesis. Our analysis reveals the presence of a trade-off between node activation and node re-use that results in worst forgetting in the intermediate regime. Using this understanding we reinterpret popular algorithmic interventions for catastrophic interference in terms of this trade-off, and identify the regimes in which they are most effective.
A study on the plasticity of neural networks
May 31, 2021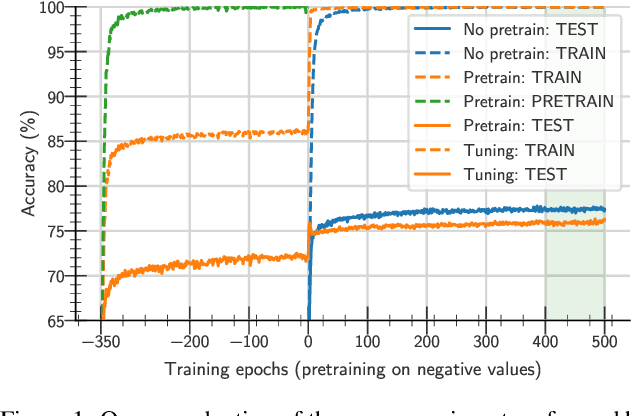
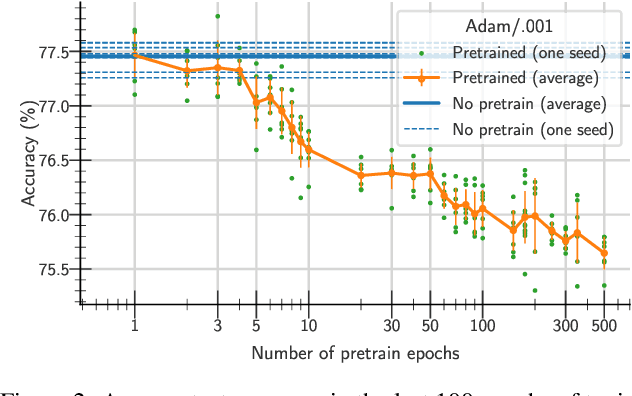
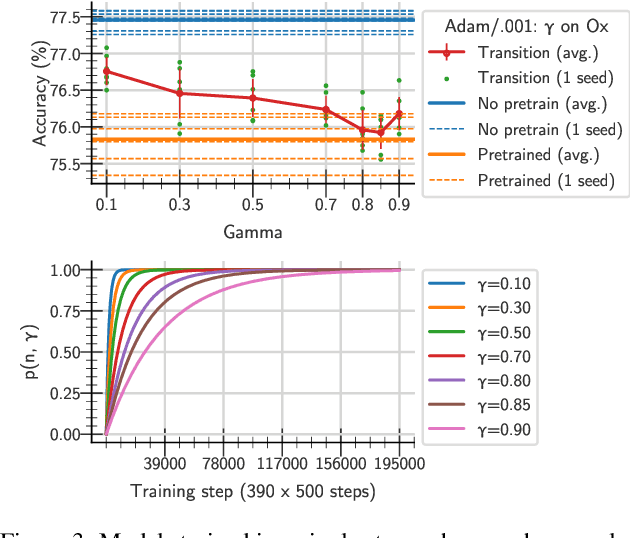
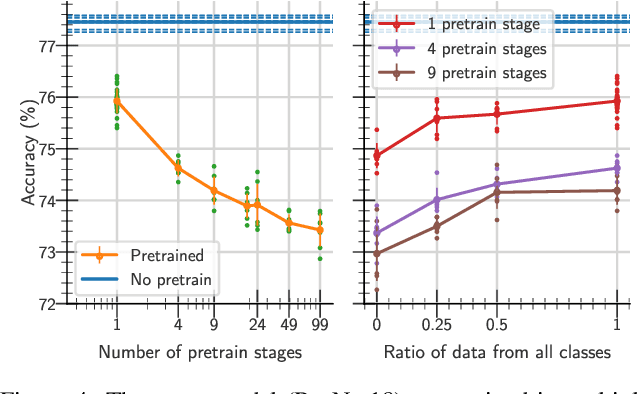
One aim shared by multiple settings, such as continual learning or transfer learning, is to leverage previously acquired knowledge to converge faster on the current task. Usually this is done through fine-tuning, where an implicit assumption is that the network maintains its plasticity, meaning that the performance it can reach on any given task is not affected negatively by previously seen tasks. It has been observed recently that a pretrained model on data from the same distribution as the one it is fine-tuned on might not reach the same generalisation as a freshly initialised one. We build and extend this observation, providing a hypothesis for the mechanics behind it. We discuss the implication of losing plasticity for continual learning which heavily relies on optimising pretrained models.
CCN GAC Workshop: Issues with learning in biological recurrent neural networks
May 12, 2021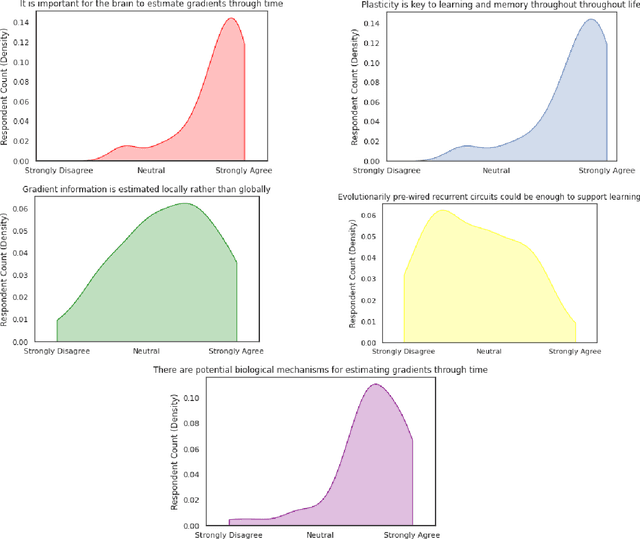
This perspective piece came about through the Generative Adversarial Collaboration (GAC) series of workshops organized by the Computational Cognitive Neuroscience (CCN) conference in 2020. We brought together a number of experts from the field of theoretical neuroscience to debate emerging issues in our understanding of how learning is implemented in biological recurrent neural networks. Here, we will give a brief review of the common assumptions about biological learning and the corresponding findings from experimental neuroscience and contrast them with the efficiency of gradient-based learning in recurrent neural networks commonly used in artificial intelligence. We will then outline the key issues discussed in the workshop: synaptic plasticity, neural circuits, theory-experiment divide, and objective functions. Finally, we conclude with recommendations for both theoretical and experimental neuroscientists when designing new studies that could help to bring clarity to these issues.
Spectral Normalisation for Deep Reinforcement Learning: an Optimisation Perspective
May 11, 2021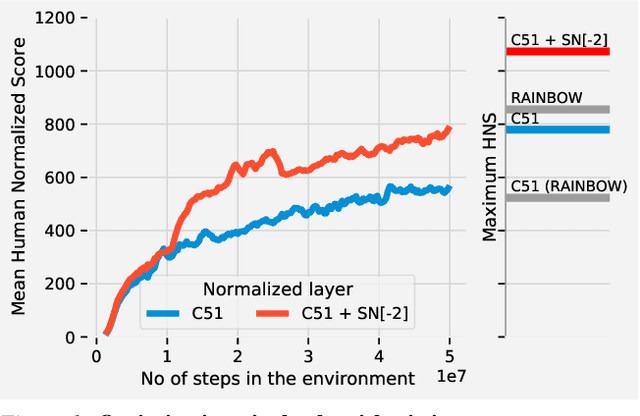
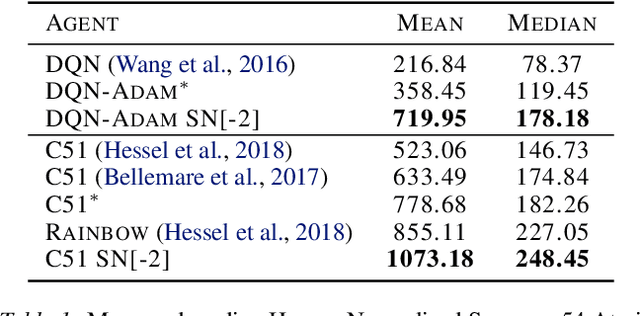
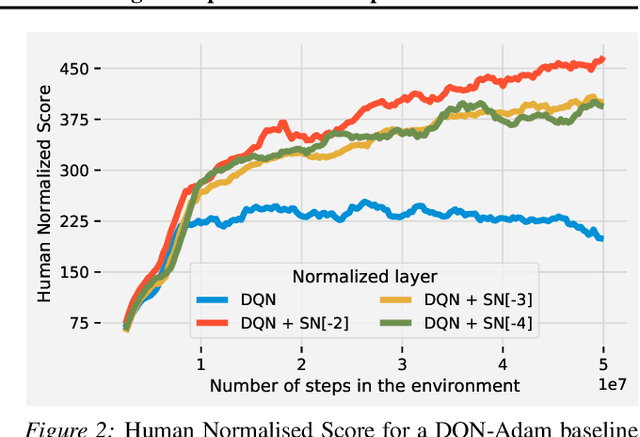

Most of the recent deep reinforcement learning advances take an RL-centric perspective and focus on refinements of the training objective. We diverge from this view and show we can recover the performance of these developments not by changing the objective, but by regularising the value-function estimator. Constraining the Lipschitz constant of a single layer using spectral normalisation is sufficient to elevate the performance of a Categorical-DQN agent to that of a more elaborated \rainbow{} agent on the challenging Atari domain. We conduct ablation studies to disentangle the various effects normalisation has on the learning dynamics and show that is sufficient to modulate the parameter updates to recover most of the performance of spectral normalisation. These findings hint towards the need to also focus on the neural component and its learning dynamics to tackle the peculiarities of Deep Reinforcement Learning.